 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Map Learning of Traffic Light to Lane Assignment based on Motion Data
Sep 28, 2023Understanding which traffic light controls which lane is crucial to navigate intersections safely. Autonomous vehicles commonly rely on High Definition (HD) maps that contain information about the assignment of traffic lights to lanes. The manual provisioning of this information is tedious, expensive, and not scalable. To remedy these issues, our novel approach derives the assignments from traffic light states and the corresponding motion patterns of vehicle traffic. This works in an automated way and independently of the geometric arrangement. We show the effectiveness of basic statistical approaches for this task by implementing and evaluating a pattern-based contribution method. In addition, our novel rejection method includes accompanying safety considerations by leveraging statistical hypothesis testing. Finally, we propose a dataset transformation to re-purpose available motion prediction datasets for semantic map learning. Our publicly available API for the Lyft Level 5 dataset enables researchers to develop and evaluate their own approaches.
Unsupervised and Generic Short-Term Anticipation of Human Body Motions
Dec 13, 2019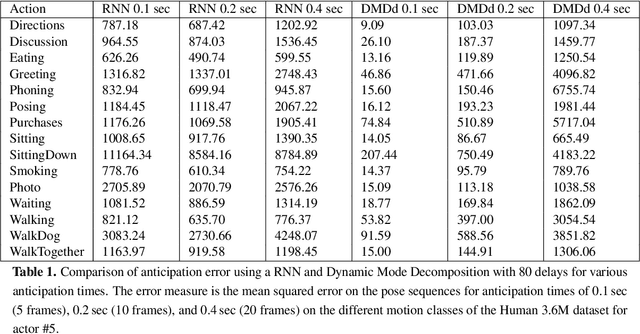
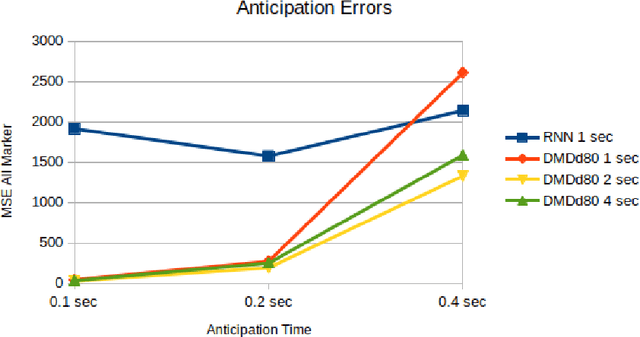
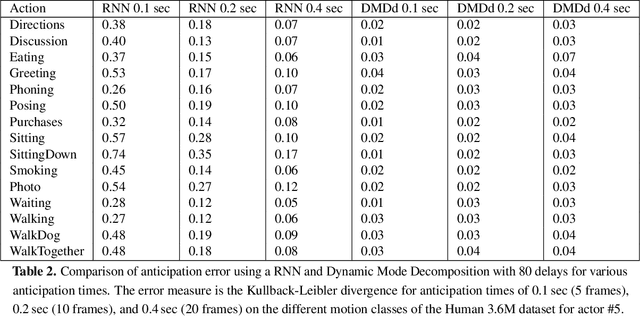
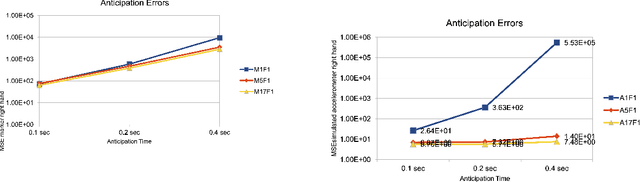
Various neural network based methods are capable of anticipating human body motions from data for a short period of time. What these methods lack are the interpretability and explainability of the network and its results. We propose to use Dynamic Mode Decomposition with delays to represent and anticipate human body motions. Exploring the influence of the number of delays on the reconstruction and prediction of various motion classes, we show that the anticipation errors in our results are comparable or even better for very short anticipation times ($<0.4$ sec) to a recurrent neural network based method. We perceive our method as a first step towards the interpretability of the results by representing human body motions as linear combinations of ``factors''. In addition, compared to the neural network based methods large training times are not needed. Actually, our methods do not even regress to any other motions than the one to be anticipated and hence is of a generic nature.
Human Motion Anticipation with Symbolic Label
Dec 13, 2019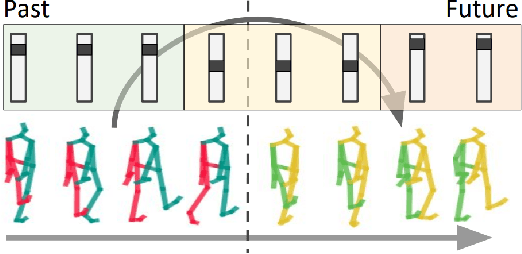
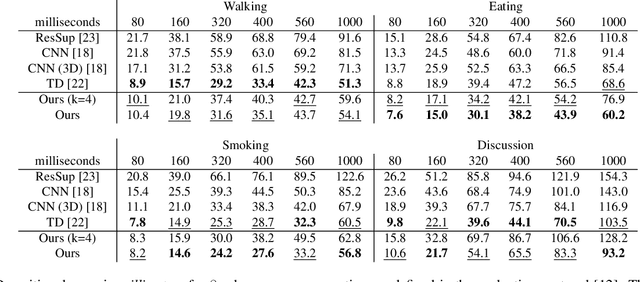
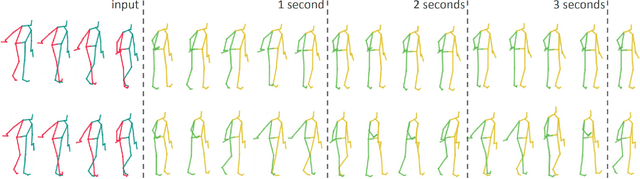
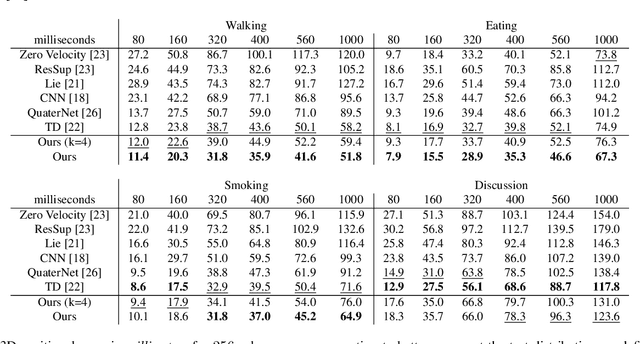
Anticipating human motion depends on two factors: the past motion and the person's intention. While the first factor has been extensively utilized to forecast short sequences of human motion, the second one remains elusive. In this work we approximate a person's intention via a symbolic representation, for example fine-grained action labels such as walking or sitting down. Forecasting a symbolic representation is much easier than forecasting the full body pose with its complex inter-dependencies. However, knowing the future actions makes forecasting human motion easier. We exploit this connection by first anticipating symbolic labels and then generate human motion, conditioned on the human motion input sequence as well as on the forecast labels. This allows the model to anticipate motion changes many steps ahead and adapt the poses accordingly. We achieve state-of-the-art results on short-term as well as on long-term human motion forecasting.
Bonn Activity Maps: Dataset Description
Dec 13, 2019
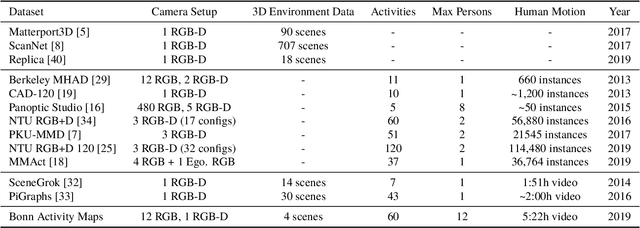


The key prerequisite for accessing the huge potential of current machine learning techniques is the availability of large databases that capture the complex relations of interest. Previous datasets are focused on either 3D scene representations with semantic information, tracking of multiple persons and recognition of their actions, or activity recognition of a single person in captured 3D environments. We present Bonn Activity Maps, a large-scale dataset for human tracking, activity recognition and anticipation of multiple persons. Our dataset comprises four different scenes that have been recorded by time-synchronized cameras each only capturing the scene partially, the reconstructed 3D models with semantic annotations, motion trajectories for individual people including 3D human poses as well as human activity annotations. We utilize the annotations to generate activity likelihoods on the 3D models called activity maps.
A Dual-Source Approach for 3D Human Pose Estimation from a Single Image
Sep 06, 2017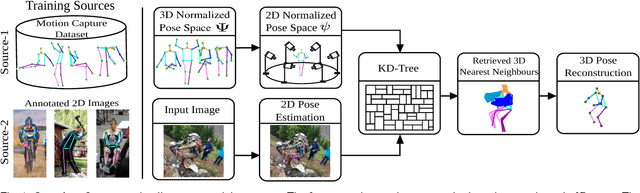
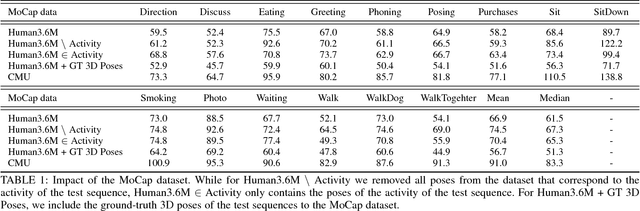
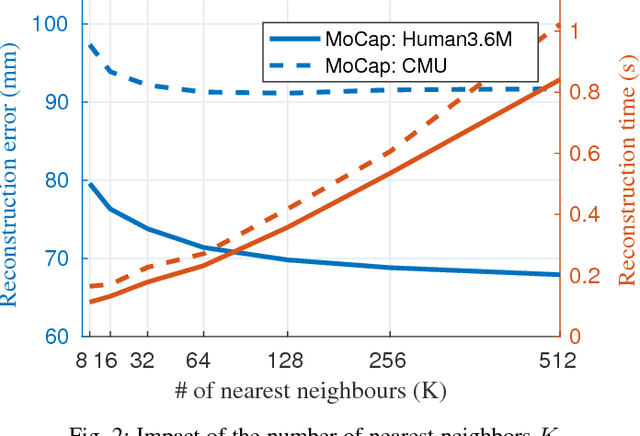
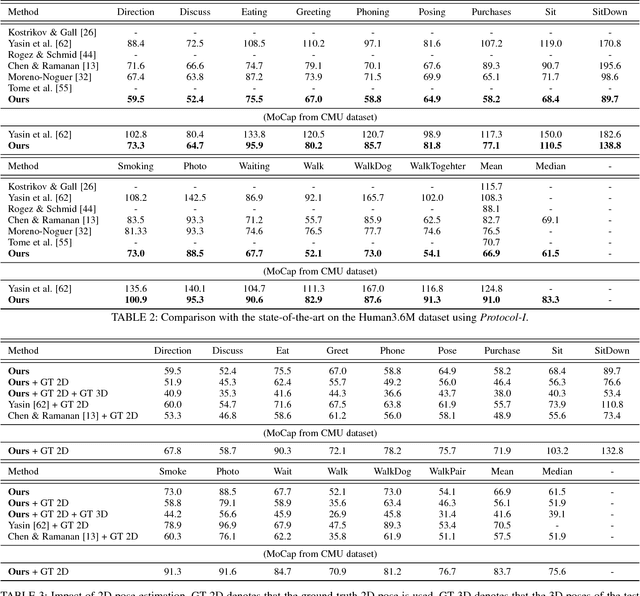
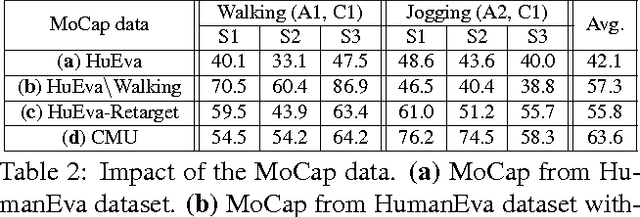
In this work we address the challenging problem of 3D human pose estimation from single images. Recent approaches learn deep neural networks to regress 3D pose directly from images. One major challenge for such methods, however, is the collection of training data. Specifically, collecting large amounts of training data containing unconstrained images annotated with accurate 3D poses is infeasible. We therefore propose to use two independent training sources. The first source consists of accurate 3D motion capture data, and the second source consists of unconstrained images with annotated 2D poses. To integrate both sources, we propose a dual-source approach that combines 2D pose estimation with efficient 3D pose retrieval. To this end, we first convert the motion capture data into a normalized 2D pose space, and separately learn a 2D pose estimation model from the image data. During inference, we estimate the 2D pose and efficiently retrieve the nearest 3D poses. We then jointly estimate a mapping from the 3D pose space to the image and reconstruct the 3D pose. We provide a comprehensive evaluation of the proposed method and experimentally demonstrate the effectiveness of our approach, even when the skeleton structures of the two sources differ substantially.
A Dual-Source Approach for 3D Pose Estimation from a Single Image
Mar 27, 2016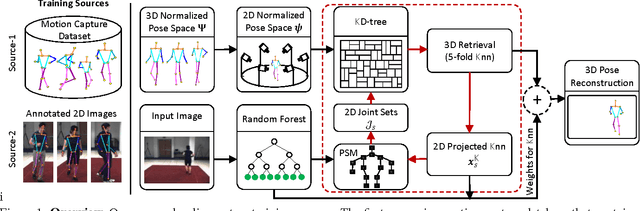
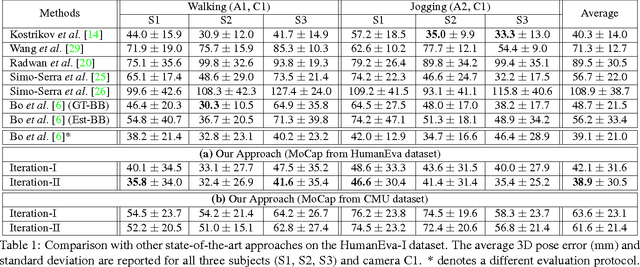
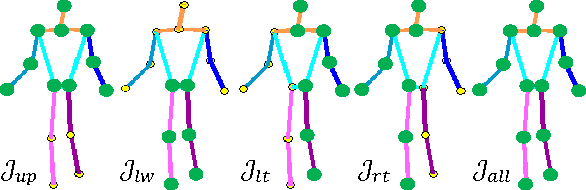
One major challenge for 3D pose estimation from a single RGB image is the acquisition of sufficient training data. In particular, collecting large amounts of training data that contain unconstrained images and are annotated with accurate 3D poses is infeasible. We therefore propose to use two independent training sources. The first source consists of images with annotated 2D poses and the second source consists of accurate 3D motion capture data. To integrate both sources, we propose a dual-source approach that combines 2D pose estimation with efficient and robust 3D pose retrieval. In our experiments, we show that our approach achieves state-of-the-art results and is even competitive when the skeleton structure of the two sources differ substantially.
Efficient Unsupervised Temporal Segmentation of Motion Data
Oct 22, 2015


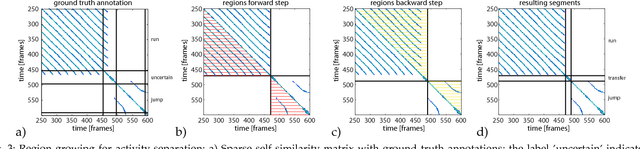
We introduce a method for automated temporal segmentation of human motion data into distinct actions and compositing motion primitives based on self-similar structures in the motion sequence. We use neighbourhood graphs for the partitioning and the similarity information in the graph is further exploited to cluster the motion primitives into larger entities of semantic significance. The method requires no assumptions about the motion sequences at hand and no user interaction is required for the segmentation or clustering. In addition, we introduce a feature bundling preprocessing technique to make the segmentation more robust to noise, as well as a notion of motion symmetry for more refined primitive detection. We test our method on several sensor modalities, including markered and markerless motion capture as well as on electromyograph and accelerometer recordings. The results highlight our system's capabilities for both segmentation and for analysis of the finer structures of motion data, all in a completely unsupervised manner.