 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalkCuts: A Large-Scale Dataset for Multi-Shot Human Speech Video Generation
Oct 08, 2025In this work, we present TalkCuts, a large-scale dataset designed to facilitate the study of multi-shot human speech video generation. Unlike existing datasets that focus on single-shot, static viewpoints, TalkCuts offers 164k clips totaling over 500 hours of high-quality human speech videos with diverse camera shots, including close-up, half-body, and full-body views. The dataset includes detailed textual descriptions, 2D keypoints and 3D SMPL-X motion annotations, covering over 10k identities, enabling multimodal learning and evaluation. As a first attempt to showcase the value of the dataset, we present Orator, an LLM-guided multi-modal generation framework as a simple baseline, where the language model functions as a multi-faceted director, orchestrating detailed specifications for camera transitions, speaker gesticulations, and vocal modulation. This architecture enables the synthesis of coherent long-form videos through our integrated multi-modal video generation module. Extensive experiments in both pose-guided and audio-driven settings show that training on TalkCuts significantly enhances the cinematographic coherence and visual appeal of generated multi-shot speech videos. We believe TalkCuts provides a strong foundation for future work in controllable, multi-shot speech video generation and broader multimodal learning.
SoundReactor: Frame-level Online Video-to-Audio Generation
Oct 02, 2025



Prevailing Video-to-Audio (V2A) generation models operate offline, assuming an entire video sequence or chunks of frames are available beforehand. This critically limits their use in interactive applications such as live content creation and emerging generative world models. To address this gap, we introduce the novel task of frame-level online V2A generation, where a model autoregressively generates audio from video without access to future video frames. Furthermore, we propose SoundReactor, which, to the best of our knowledge, is the first simple yet effective framework explicitly tailored for this task. Our design enforces end-to-end causality and targets low per-frame latency with audio-visual synchronization. Our model's backbone is a decoder-only causal transformer over continuous audio latents. For vision conditioning, it leverages grid (patch) features extracted from the smallest variant of the DINOv2 vision encoder, which are aggregated into a single token per frame to maintain end-to-end causality and efficiency. The model is trained through a diffusion pre-training followed by consistency fine-tuning to accelerate the diffusion head decoding. On a benchmark of diverse gameplay videos from AAA titles, our model successfully generates semantically and temporally aligned, high-quality full-band stereo audio, validated by both objective and human evaluations. Furthermore, our model achieves low per-frame waveform-level latency (26.3ms with the head NFE=1, 31.5ms with NFE=4) on 30FPS, 480p videos using a single H100. Demo samples are available at https://koichi-saito-sony.github.io/soundreactor/.
Dyadic Mamba: Long-term Dyadic Human Motion Synthesis
May 14, 2025Generating realistic dyadic human motion from text descriptions presents significant challenges, particularly for extended interactions that exceed typical training sequence lengths. While recent transformer-based approaches have shown promising results for short-term dyadic motion synthesis, they struggle with longer sequences due to inherent limitations in positional encoding schemes. In this paper, we introduce Dyadic Mamba, a novel approach that leverages State-Space Models (SSMs) to generate high-quality dyadic human motion of arbitrary length. Our method employs a simple yet effective architecture that facilitates information flow between individual motion sequences through concatenation, eliminating the need for complex cross-attention mechanisms. We demonstrate that Dyadic Mamba achieves competitive performance on standard short-term benchmarks while significantly outperforming transformer-based approaches on longer sequences. Additionally, we propose a new benchmark for evaluating long-term motion synthesis quality, providing a standardized framework for future research. Our results demonstrate that SSM-based architectures offer a promising direction for addressing the challenging task of long-term dyadic human motion synthesis from text descriptions.
Massively Multi-Person 3D Human Motion Forecasting with Scene Context
Sep 18, 2024



Forecasting long-term 3D human motion is challenging: the stochasticity of human behavior makes it hard to generate realistic human motion from the input sequence alone. Information on the scene environment and the motion of nearby people can greatly aid the generation process. We propose a scene-aware social transformer model (SAST) to forecast long-term (10s) human motion motion. Unlike previous models, our approach can model interactions between both widely varying numbers of people and objects in a scene. We combine a temporal convolutional encoder-decoder architecture with a Transformer-based bottleneck that allows us to efficiently combine motion and scene information. We model the conditional motion distribution using denoising diffusion models. We benchmark our approach on the Humans in Kitchens dataset, which contains 1 to 16 persons and 29 to 50 objects that are visible simultaneously. Our model outperforms other approaches in terms of realism and diversity on different metrics and in a user study. Code is available at https://github.com/felixbmuller/SAST.
TAVA: Template-free Animatable Volumetric Actors
Jun 21, 2022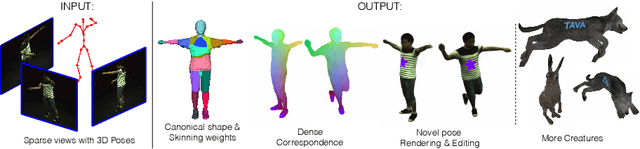

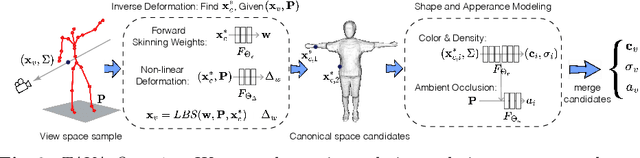
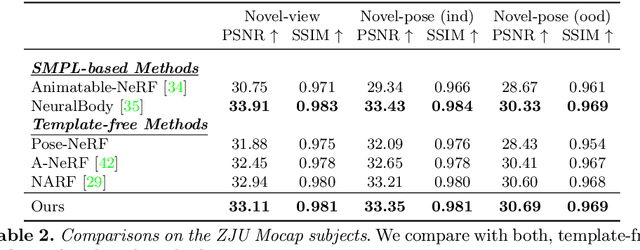
Coordinate-based volumetric representations have the potential to generate photo-realistic virtual avatars from images. However, virtual avatars also need to be controllable even to a novel pose that may not have been observed. Traditional techniques, such as LBS, provide such a function; yet it usually requires a hand-designed body template, 3D scan data, and limited appearance models. On the other hand, neural representation has been shown to be powerful in representing visual details, but are under explored on deforming dynamic articulated actors. In this paper, we propose TAVA, a method to create T emplate-free Animatable Volumetric Actors, based on neural representations. We rely solely on multi-view data and a tracked skeleton to create a volumetric model of an actor, which can be animated at the test time given novel pose. Since TAVA does not require a body template, it is applicable to humans as well as other creatures such as animals. Furthermore, TAVA is designed such that it can recover accurate dense correspondences, making it amenable to content-creation and editing tasks. Through extensive experiments, we demonstrate that the proposed method generalizes well to novel poses as well as unseen views and showcase basic editing capabilities.
Iterative Greedy Matching for 3D Human Pose Tracking from Multiple Views
Jan 24, 2021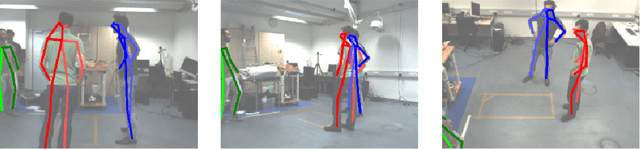
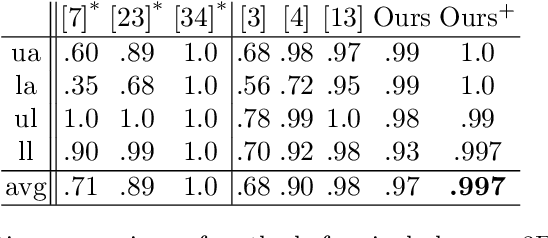

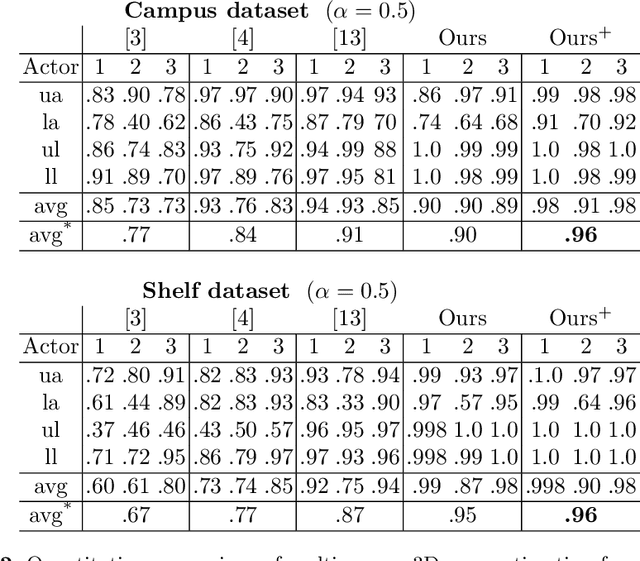
In this work we propose an approach for estimating 3D human poses of multiple people from a set of calibrated cameras. Estimating 3D human poses from multiple views has several compelling properties: human poses are estimated within a global coordinate space and multiple cameras provide an extended field of view which helps in resolving ambiguities, occlusions and motion blur. Our approach builds upon a real-time 2D multi-person pose estimation system and greedily solves the association problem between multiple views. We utilize bipartite matching to track multiple people over multiple frames. This proofs to be especially efficient as problems associated with greedy matching such as occlusion can be easily resolved in 3D. Our approach achieves state-of-the-art results on popular benchmarks and may serve as a baseline for future work.
* German Conference on Pattern Recognition 2019
ANR: Articulated Neural Rendering for Virtual Avatars
Dec 23, 2020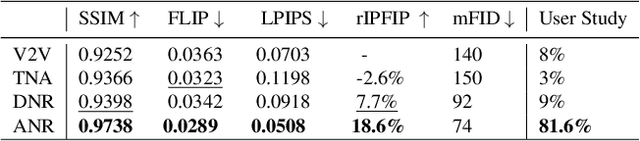
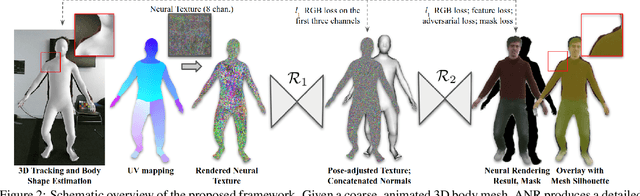
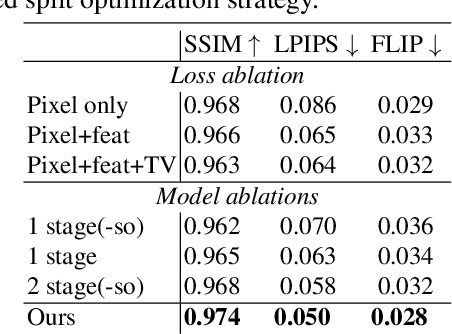
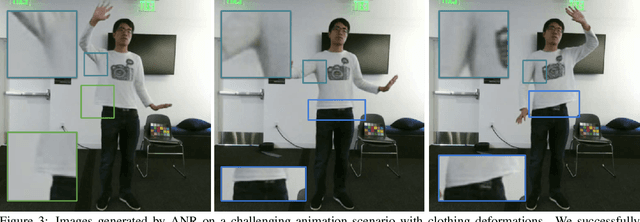
The combination of traditional rendering with neural networks in Deferred Neural Rendering (DNR) provides a compelling balance between computational complexity and realism of the resulting images. Using skinned meshes for rendering articulating objects is a natural extension for the DNR framework and would open it up to a plethora of applications. However, in this case the neural shading step must account for deformations that are possibly not captured in the mesh, as well as alignment inaccuracies and dynamics -- which can confound the DNR pipeline. We present Articulated Neural Rendering (ANR), a novel framework based on DNR which explicitly addresses its limitations for virtual human avatars. We show the superiority of ANR not only with respect to DNR but also with methods specialized for avatar creation and animation. In two user studies, we observe a clear preference for our avatar model and we demonstrate state-of-the-art performance on quantitative evaluation metrics. Perceptually, we observe better temporal stability, level of detail and plausibility.
Adversarial Synthesis of Human Pose from Text
May 01, 2020
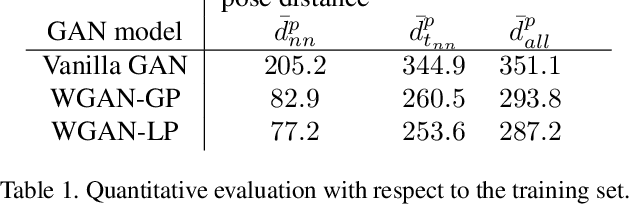
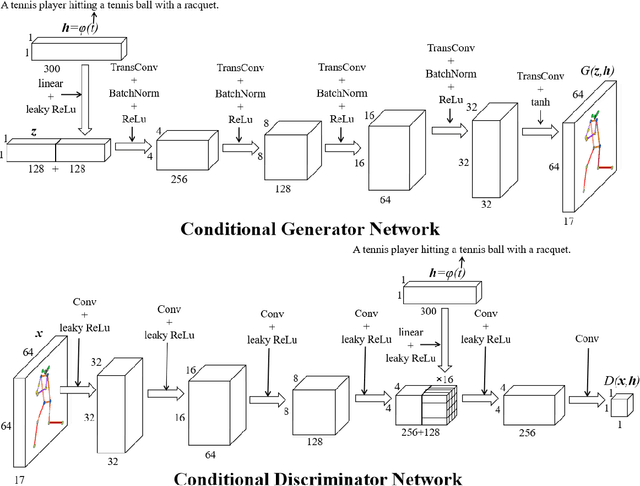
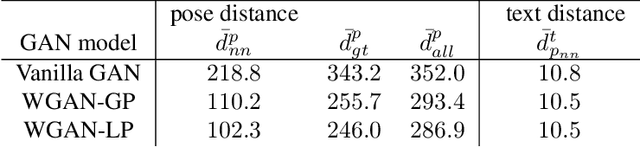
This work introduces the novel task of human pose synthesis from text. In order to solve this task, we propose a model that is based on a conditional generative adversarial network. It is designed to generate 2D human poses conditioned on human-written text descriptions. The model is trained and evaluated using the COCO dataset, which consists of images capturing complex everyday scenes. We show through qualitative and quantitative results that the model is capable of synthesizing plausible poses matching the given text, indicating it is possible to generate poses that are consistent with the given semantic features, especially for actions with distinctive poses. We also show that the model outperforms a vanilla GAN.
Human Motion Anticipation with Symbolic Label
Dec 13, 2019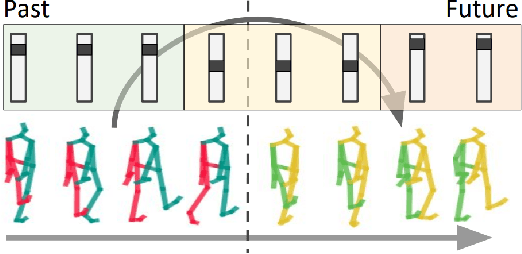
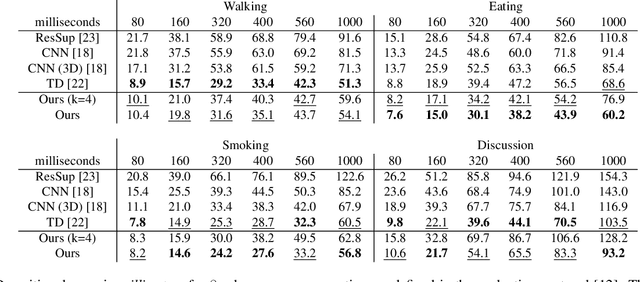
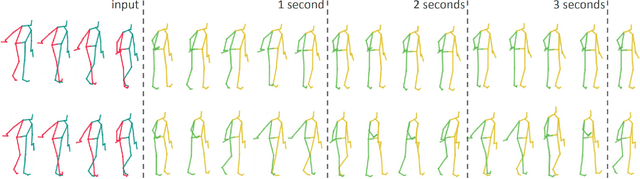
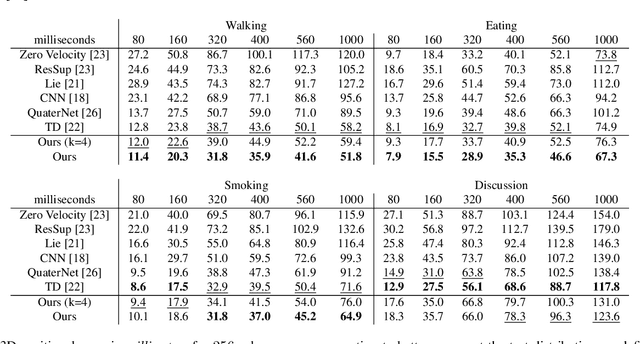
Anticipating human motion depends on two factors: the past motion and the person's intention. While the first factor has been extensively utilized to forecast short sequences of human motion, the second one remains elusive. In this work we approximate a person's intention via a symbolic representation, for example fine-grained action labels such as walking or sitting down. Forecasting a symbolic representation is much easier than forecasting the full body pose with its complex inter-dependencies. However, knowing the future actions makes forecasting human motion easier. We exploit this connection by first anticipating symbolic labels and then generate human motion, conditioned on the human motion input sequence as well as on the forecast labels. This allows the model to anticipate motion changes many steps ahead and adapt the poses accordingly. We achieve state-of-the-art results on short-term as well as on long-term human motion forecasting.
Bonn Activity Maps: Dataset Description
Dec 13, 2019
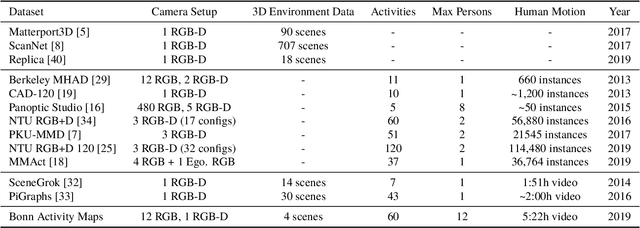


The key prerequisite for accessing the huge potential of current machine learning techniques is the availability of large databases that capture the complex relations of interest. Previous datasets are focused on either 3D scene representations with semantic information, tracking of multiple persons and recognition of their actions, or activity recognition of a single person in captured 3D environments. We present Bonn Activity Maps, a large-scale dataset for human tracking, activity recognition and anticipation of multiple persons. Our dataset comprises four different scenes that have been recorded by time-synchronized cameras each only capturing the scene partially, the reconstructed 3D models with semantic annotations, motion trajectories for individual people including 3D human poses as well as human activity annotations. We utilize the annotations to generate activity likelihoods on the 3D models called activity maps.