 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLossy Neural Compression for Geospatial Analytics: A Review
Mar 03, 2025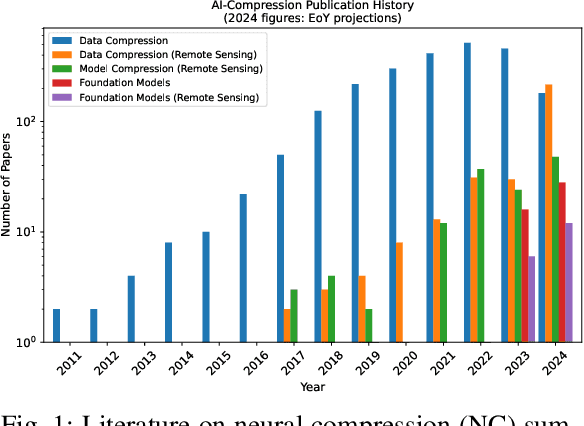
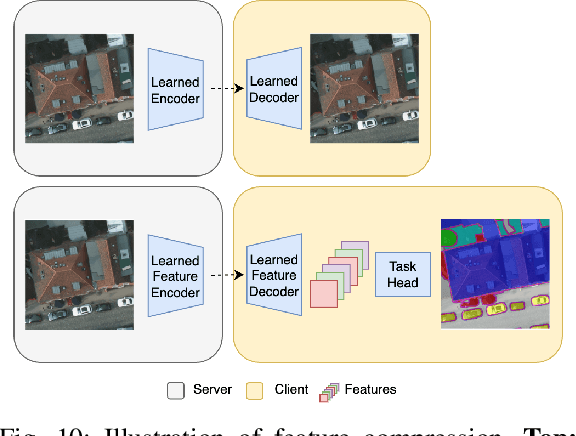
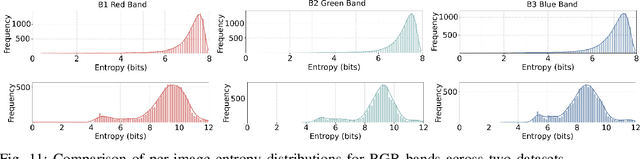
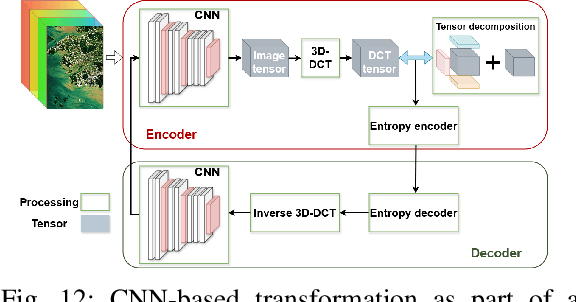
Over the past decades, there has been an explosion in the amount of available Earth Observation (EO) data. The unprecedented coverage of the Earth's surface and atmosphere by satellite imagery has resulted in large volumes of data that must be transmitted to ground stations, stored in data centers, and distributed to end users. Modern Earth System Models (ESMs) face similar challenges, operating at high spatial and temporal resolutions, producing petabytes of data per simulated day. Data compression has gained relevance over the past decade, with neural compression (NC) emerging from deep learning and information theory, making EO data and ESM outputs ideal candidates due to their abundance of unlabeled data. In this review, we outline recent developments in NC applied to geospatial data. We introduce the fundamental concepts of NC including seminal works in its traditional applications to image and video compression domains with focus on lossy compression. We discuss the unique characteristics of EO and ESM data, contrasting them with "natural images", and explain the additional challenges and opportunities they present. Moreover, we review current applications of NC across various EO modalities and explore the limited efforts in ESM compression to date. The advent of self-supervised learning (SSL) and foundation models (FM) has advanced methods to efficiently distill representations from vast unlabeled data. We connect these developments to NC for EO, highlighting the similarities between the two fields and elaborate on the potential of transferring compressed feature representations for machine--to--machine communication. Based on insights drawn from this review, we devise future directions relevant to applications in EO and ESM.
Scaling Image Tokenizers with Grouped Spherical Quantization
Dec 03, 2024



Vision tokenizers have gained a lot of attraction due to their scalability and compactness; previous works depend on old-school GAN-based hyperparameters, biased comparisons, and a lack of comprehensive analysis of the scaling behaviours. To tackle those issues, we introduce Grouped Spherical Quantization (GSQ), featuring spherical codebook initialization and lookup regularization to constrain codebook latent to a spherical surface. Our empirical analysis of image tokenizer training strategies demonstrates that GSQ-GAN achieves superior reconstruction quality over state-of-the-art methods with fewer training iterations, providing a solid foundation for scaling studies. Building on this, we systematically examine the scaling behaviours of GSQ, specifically in latent dimensionality, codebook size, and compression ratios, and their impact on model performance. Our findings reveal distinct behaviours at high and low spatial compression levels, underscoring challenges in representing high-dimensional latent spaces. We show that GSQ can restructure high-dimensional latent into compact, low-dimensional spaces, thus enabling efficient scaling with improved quality. As a result, GSQ-GAN achieves a 16x down-sampling with a reconstruction FID (rFID) of 0.50.
Data Pruning in Generative Diffusion Models
Nov 19, 2024



Data pruning is the problem of identifying a core subset that is most beneficial to training and discarding the remainder. While pruning strategies are well studied for discriminative models like those used in classification, little research has gone into their application to generative models. Generative models aim to estimate the underlying distribution of the data, so presumably they should benefit from larger datasets. In this work we aim to shed light on the accuracy of this statement, specifically answer the question of whether data pruning for generative diffusion models could have a positive impact. Contrary to intuition, we show that eliminating redundant or noisy data in large datasets is beneficial particularly when done strategically. We experiment with several pruning methods including recent-state-of-art methods, and evaluate over CelebA-HQ and ImageNet datasets. We demonstrate that a simple clustering method outperforms other sophisticated and computationally demanding methods. We further exhibit how we can leverage clustering to balance skewed datasets in an unsupervised manner to allow fair sampling for underrepresented populations in the data distribution, which is a crucial problem in generative models.
Recurrent Transformer Variational Autoencoders for Multi-Action Motion Synthesis
Jun 14, 2022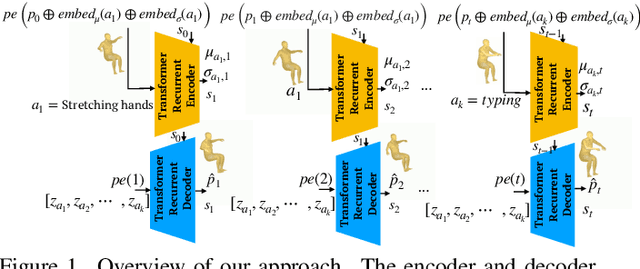
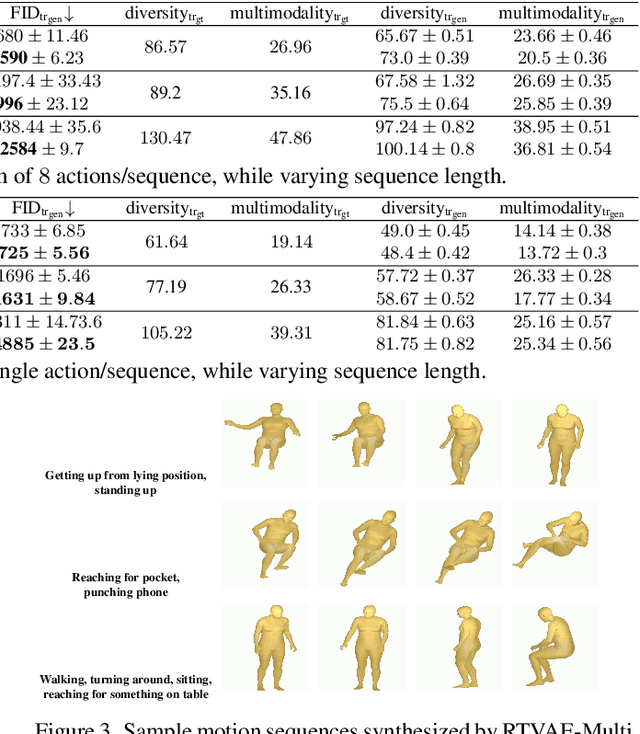
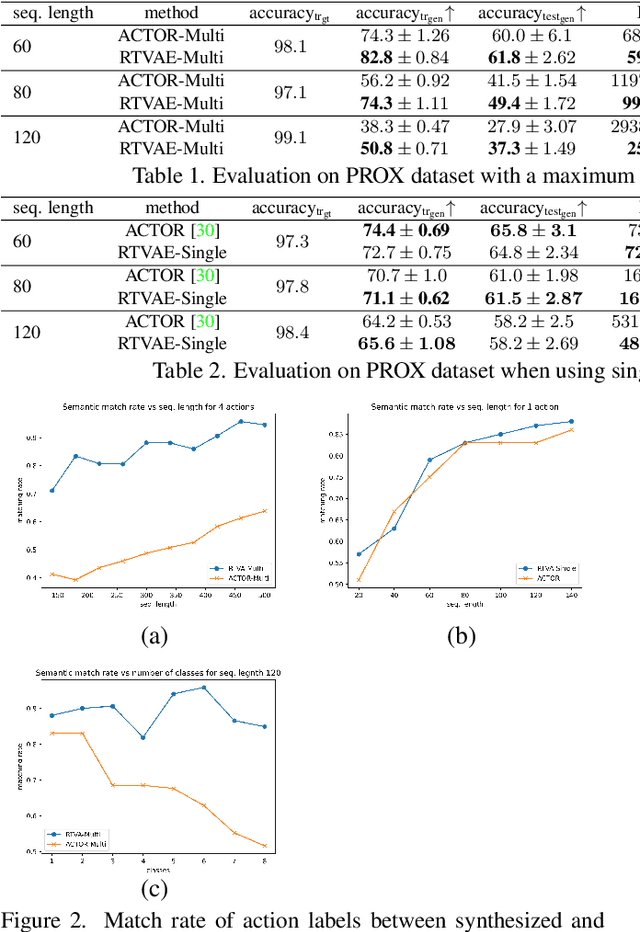

We consider the problem of synthesizing multi-action human motion sequences of arbitrary lengths. Existing approaches have mastered motion sequence generation in single-action scenarios, but fail to generalize to multi-action and arbitrary-length sequences. We fill this gap by proposing a novel efficient approach that leverages the expressiveness of Recurrent Transformers and generative richness of conditional Variational Autoencoders. The proposed iterative approach is able to generate smooth and realistic human motion sequences with an arbitrary number of actions and frames while doing so in linear space and time. We train and evaluate the proposed approach on PROX dataset which we augment with ground-truth action labels. Experimental evaluation shows significant improvements in FID score and semantic consistency metrics compared to the state-of-the-art.
Towards Better Adversarial Synthesis of Human Images from Text
Jul 05, 2021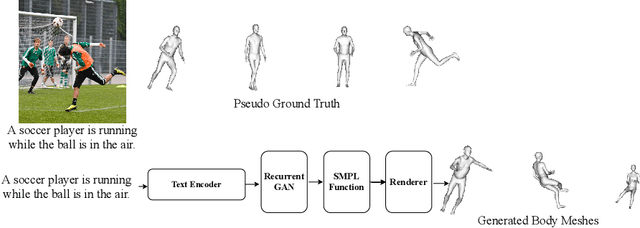


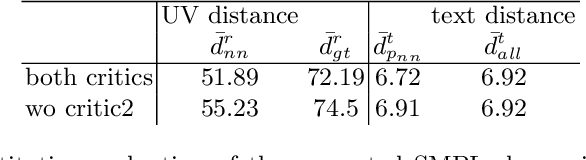
This paper proposes an approach that generates multiple 3D human meshes from text. The human shapes are represented by 3D meshes based on the SMPL model. The model's performance is evaluated on the COCO dataset, which contains challenging human shapes and intricate interactions between individuals. The model is able to capture the dynamics of the scene and the interactions between individuals based on text. We further show how using such a shape as input to image synthesis frameworks helps to constrain the network to synthesize humans with realistic human shapes.
Adversarial Synthesis of Human Pose from Text
May 01, 2020
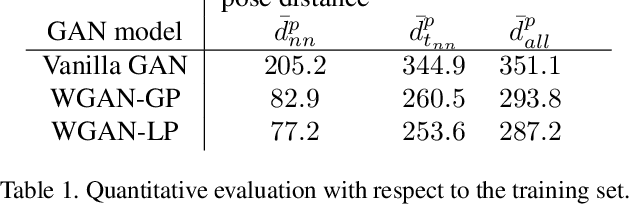
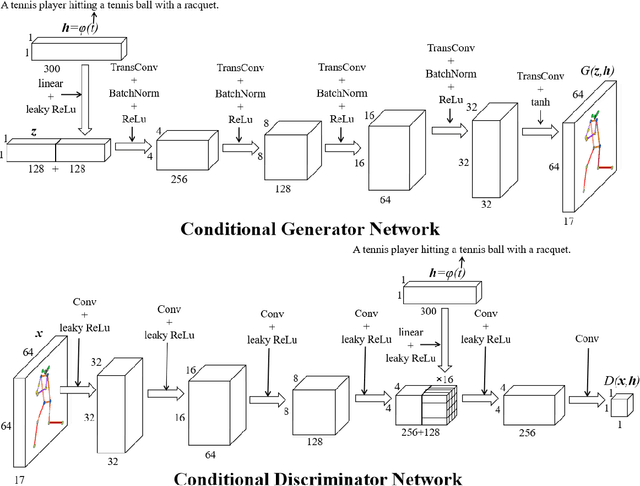
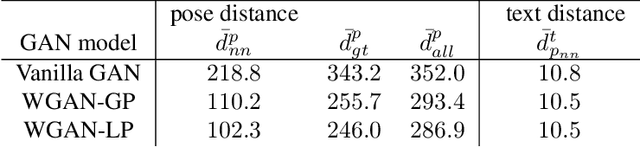
This work introduces the novel task of human pose synthesis from text. In order to solve this task, we propose a model that is based on a conditional generative adversarial network. It is designed to generate 2D human poses conditioned on human-written text descriptions. The model is trained and evaluated using the COCO dataset, which consists of images capturing complex everyday scenes. We show through qualitative and quantitative results that the model is capable of synthesizing plausible poses matching the given text, indicating it is possible to generate poses that are consistent with the given semantic features, especially for actions with distinctive poses. We also show that the model outperforms a vanilla GAN.
Unifying Part Detection and Association for Recurrent Multi-Person Pose Estimation
Apr 26, 2019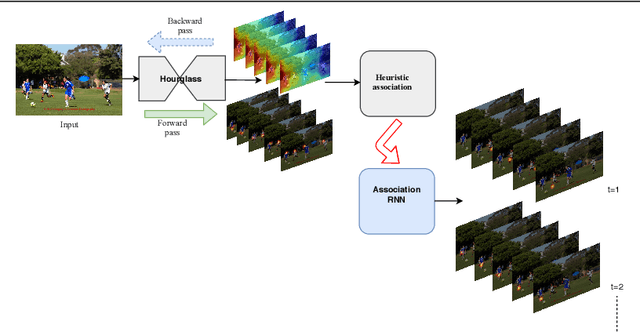
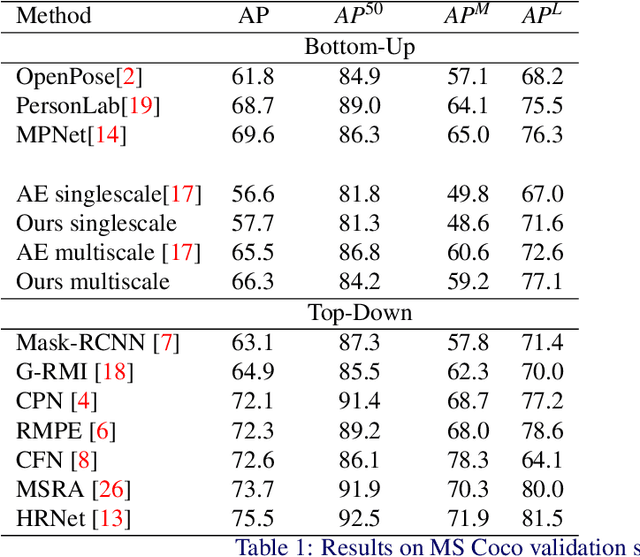


We propose a joint model of human joint detection and association for 2D multi-person pose estimation (MPPE). The approach unifies training of joint detection and association without a need for further processing or sophisticated heuristics in order to associate the joints with people individually. The approach consists of two stages, where in the first stage joint detection heatmaps and association features are extracted, and in the second stage, whose input are the extracted features of the first stage, we introduce a recurrent neural network (RNN) which predicts the heatmaps of a single person's joints in each iteration. In addition, the network learns a stopping criterion in order to halt once it has identified all individuals in the image. This approach allowed us to eliminate several heuristic assumptions and parameters needed for association which do not necessarily hold true. Additionally, such an end-to-end approach allows the final objective to be known and directly optimized over during training. We evaluated our model on the challenging MSCOCO dataset and obtained an improvement over the baseline, particularly in challenging scenes with occlusions.
Convolutional Simplex Projection Network (CSPN) for Weakly Supervised Semantic Segmentation
Jul 24, 2018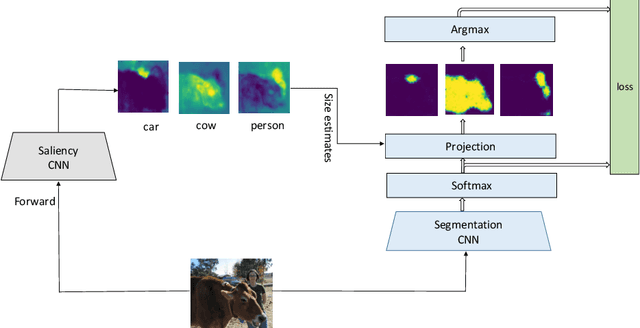
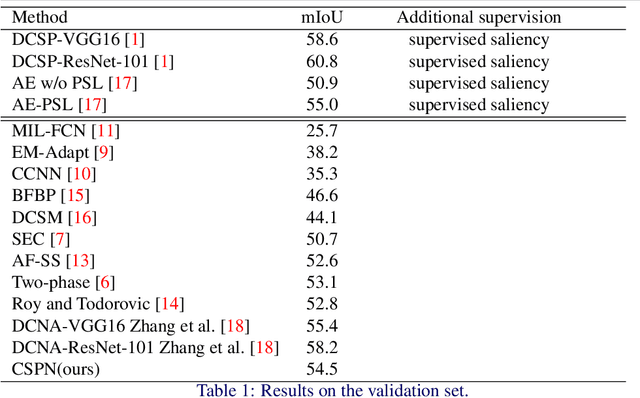

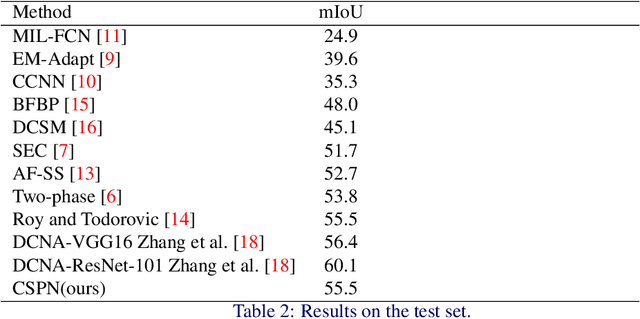
Weakly supervised semantic segmentation has been a subject of increased interest due to the scarcity of fully annotated images. We introduce a new approach for solving weakly supervised semantic segmentation with deep Convolutional Neural Networks (CNNs). The method introduces a novel layer which applies simplex projection on the output of a neural network using area constraints of class objects. The proposed method is general and can be seamlessly integrated into any CNN architecture. Moreover, the projection layer allows strongly supervised models to be adapted to weakly supervised models effortlessly by substituting ground truth labels. Our experiments have shown that applying such an operation on the output of a CNN improves the accuracy of semantic segmentation in a weakly supervised setting with image-level labels.