 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysInOne: Visual Physics Learning and Reasoning in One Suite
Apr 10, 2026We present PhysInOne, a large-scale synthetic dataset addressing the critical scarcity of physically-grounded training data for AI systems. Unlike existing datasets limited to merely hundreds or thousands of examples, PhysInOne provides 2 million videos across 153,810 dynamic 3D scenes, covering 71 basic physical phenomena in mechanics, optics, fluid dynamics, and magnetism. Distinct from previous works, our scenes feature multiobject interactions against complex backgrounds, with comprehensive ground-truth annotations including 3D geometry, semantics, dynamic motion, physical properties, and text descriptions. We demonstrate PhysInOne's efficacy across four emerging applications: physics-aware video generation, long-/short-term future frame prediction, physical property estimation, and motion transfer. Experiments show that fine-tuning foundation models on PhysInOne significantly enhances physical plausibility, while also exposing critical gaps in modeling complex physical dynamics and estimating intrinsic properties. As the largest dataset of its kind, orders of magnitude beyond prior works, PhysInOne establishes a new benchmark for advancing physics-grounded world models in generation, simulation, and embodied AI.
Fast SAM 3D Body: Accelerating SAM 3D Body for Real-Time Full-Body Human Mesh Recovery
Mar 16, 2026SAM 3D Body (3DB) achieves state-of-the-art accuracy in monocular 3D human mesh recovery, yet its inference latency of several seconds per image precludes real-time application. We present Fast SAM 3D Body, a training-free acceleration framework that reformulates the 3DB inference pathway to achieve interactive rates. By decoupling serial spatial dependencies and applying architecture-aware pruning, we enable parallelized multi-crop feature extraction and streamlined transformer decoding. Moreover, to extract the joint-level kinematics (SMPL) compatible with existing humanoid control and policy learning frameworks, we replace the iterative mesh fitting with a direct feedforward mapping, accelerating this specific conversion by over 10,000x. Overall, our framework delivers up to a 10.9x end-to-end speedup while maintaining on-par reconstruction fidelity, even surpassing 3DB on benchmarks such as LSPET. We demonstrate its utility by deploying Fast SAM 3D Body in a vision-only teleoperation system that-unlike methods reliant on wearable IMUs-enables real-time humanoid control and the direct collection of manipulation policies from a single RGB stream.
WebWorld: A Large-Scale World Model for Web Agent Training
Feb 16, 2026Web agents require massive trajectories to generalize, yet real-world training is constrained by network latency, rate limits, and safety risks. We introduce \textbf{WebWorld} series, the first open-web simulator trained at scale. While existing simulators are restricted to closed environments with thousands of trajectories, WebWorld leverages a scalable data pipeline to train on 1M+ open-web interactions, supporting reasoning, multi-format data, and long-horizon simulations of 30+ steps. For intrinsic evaluation, we introduce WebWorld-Bench with dual metrics spanning nine dimensions, where WebWorld achieves simulation performance comparable to Gemini-3-Pro. For extrinsic evaluation, Qwen3-14B trained on WebWorld-synthesized trajectories improves by +9.2\% on WebArena, reaching performance comparable to GPT-4o. WebWorld enables effective inference-time search, outperforming GPT-5 as a world model. Beyond web simulation, WebWorld exhibits cross-domain generalization to code, GUI, and game environments, providing a replicable recipe for world model construction.
SceneDiff: A Benchmark and Method for Multiview Object Change Detection
Dec 18, 2025We investigate the problem of identifying objects that have been added, removed, or moved between a pair of captures (images or videos) of the same scene at different times. Detecting such changes is important for many applications, such as robotic tidying or construction progress and safety monitoring. A major challenge is that varying viewpoints can cause objects to falsely appear changed. We introduce SceneDiff Benchmark, the first multiview change detection benchmark with object instance annotations, comprising 350 diverse video pairs with thousands of changed objects. We also introduce the SceneDiff method, a new training-free approach for multiview object change detection that leverages pretrained 3D, segmentation, and image encoding models to robustly predict across multiple benchmarks. Our method aligns the captures in 3D, extracts object regions, and compares spatial and semantic region features to detect changes. Experiments on multi-view and two-view benchmarks demonstrate that our method outperforms existing approaches by large margins (94% and 37.4% relative AP improvements). The benchmark and code will be publicly released.
Hybrid Neural-MPM for Interactive Fluid Simulations in Real-Time
May 25, 2025



We propose a neural physics system for real-time, interactive fluid simulations. Traditional physics-based methods, while accurate, are computationally intensive and suffer from latency issues. Recent machine-learning methods reduce computational costs while preserving fidelity; yet most still fail to satisfy the latency constraints for real-time use and lack support for interactive applications. To bridge this gap, we introduce a novel hybrid method that integrates numerical simulation, neural physics, and generative control. Our neural physics jointly pursues low-latency simulation and high physical fidelity by employing a fallback safeguard to classical numerical solvers. Furthermore, we develop a diffusion-based controller that is trained using a reverse modeling strategy to generate external dynamic force fields for fluid manipulation. Our system demonstrates robust performance across diverse 2D/3D scenarios, material types, and obstacle interactions, achieving real-time simulations at high frame rates (11~29% latency) while enabling fluid control guided by user-friendly freehand sketches. We present a significant step towards practical, controllable, and physically plausible fluid simulations for real-time interactive applications. We promise to release both models and data upon acceptance.
Direct and Explicit 3D Generation from a Single Image
Nov 17, 2024



Current image-to-3D approaches suffer from high computational costs and lack scalability for high-resolution outputs. In contrast, we introduce a novel framework to directly generate explicit surface geometry and texture using multi-view 2D depth and RGB images along with 3D Gaussian features using a repurposed Stable Diffusion model. We introduce a depth branch into U-Net for efficient and high quality multi-view, cross-domain generation and incorporate epipolar attention into the latent-to-pixel decoder for pixel-level multi-view consistency. By back-projecting the generated depth pixels into 3D space, we create a structured 3D representation that can be either rendered via Gaussian splatting or extracted to high-quality meshes, thereby leveraging additional novel view synthesis loss to further improve our performance. Extensive experiments demonstrate that our method surpasses existing baselines in geometry and texture quality while achieving significantly faster generation time.
MonoPatchNeRF: Improving Neural Radiance Fields with Patch-based Monocular Guidance
Apr 12, 2024The latest regularized Neural Radiance Field (NeRF) approaches produce poor geometry and view extrapolation for multiview stereo (MVS) benchmarks such as ETH3D. In this paper, we aim to create 3D models that provide accurate geometry and view synthesis, partially closing the large geometric performance gap between NeRF and traditional MVS methods. We propose a patch-based approach that effectively leverages monocular surface normal and relative depth predictions. The patch-based ray sampling also enables the appearance regularization of normalized cross-correlation (NCC) and structural similarity (SSIM) between randomly sampled virtual and training views. We further show that "density restrictions" based on sparse structure-from-motion points can help greatly improve geometric accuracy with a slight drop in novel view synthesis metrics. Our experiments show 4x the performance of RegNeRF and 8x that of FreeNeRF on average F1@2cm for ETH3D MVS benchmark, suggesting a fruitful research direction to improve the geometric accuracy of NeRF-based models, and sheds light on a potential future approach to enable NeRF-based optimization to eventually outperform traditional MVS.
QFF: Quantized Fourier Features for Neural Field Representations
Dec 02, 2022Multilayer perceptrons (MLPs) learn high frequencies slowly. Recent approaches encode features in spatial bins to improve speed of learning details, but at the cost of larger model size and loss of continuity. Instead, we propose to encode features in bins of Fourier features that are commonly used for positional encoding. We call these Quantized Fourier Features (QFF). As a naturally multiresolution and periodic representation, our experiments show that using QFF can result in smaller model size, faster training, and better quality outputs for several applications, including Neural Image Representations (NIR), Neural Radiance Field (NeRF) and Signed Distance Function (SDF) modeling. QFF are easy to code, fast to compute, and serve as a simple drop-in addition to many neural field representations.
Deep PatchMatch MVS with Learned Patch Coplanarity, Geometric Consistency and Adaptive Pixel Sampling
Oct 14, 2022
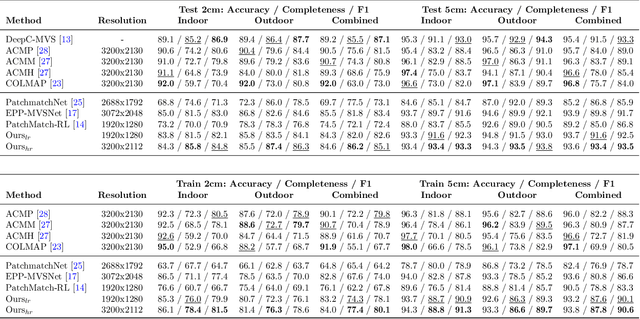
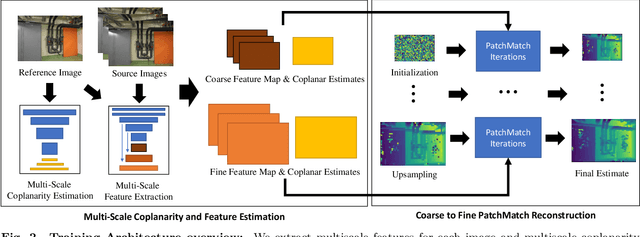
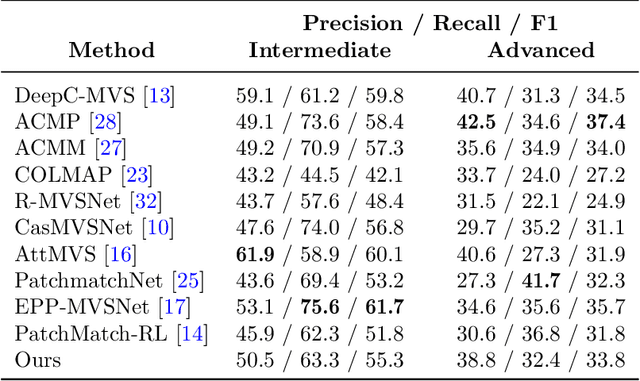
Recent work in multi-view stereo (MVS) combines learnable photometric scores and regularization with PatchMatch-based optimization to achieve robust pixelwise estimates of depth, normals, and visibility. However, non-learning based methods still outperform for large scenes with sparse views, in part due to use of geometric consistency constraints and ability to optimize over many views at high resolution. In this paper, we build on learning-based approaches to improve photometric scores by learning patch coplanarity and encourage geometric consistency by learning a scaled photometric cost that can be combined with reprojection error. We also propose an adaptive pixel sampling strategy for candidate propagation that reduces memory to enable training on larger resolution with more views and a larger encoder. These modifications lead to 6-15% gains in accuracy and completeness on the challenging ETH3D benchmark, resulting in higher F1 performance than the widely used state-of-the-art non-learning approaches ACMM and ACMP.
Recurrent Transformer Variational Autoencoders for Multi-Action Motion Synthesis
Jun 14, 2022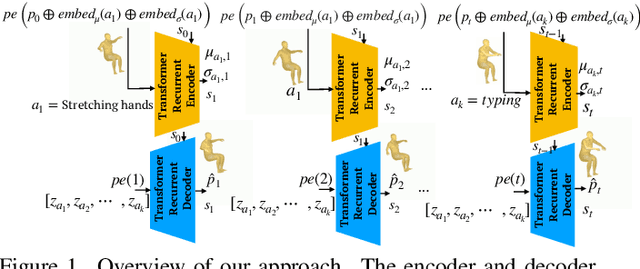
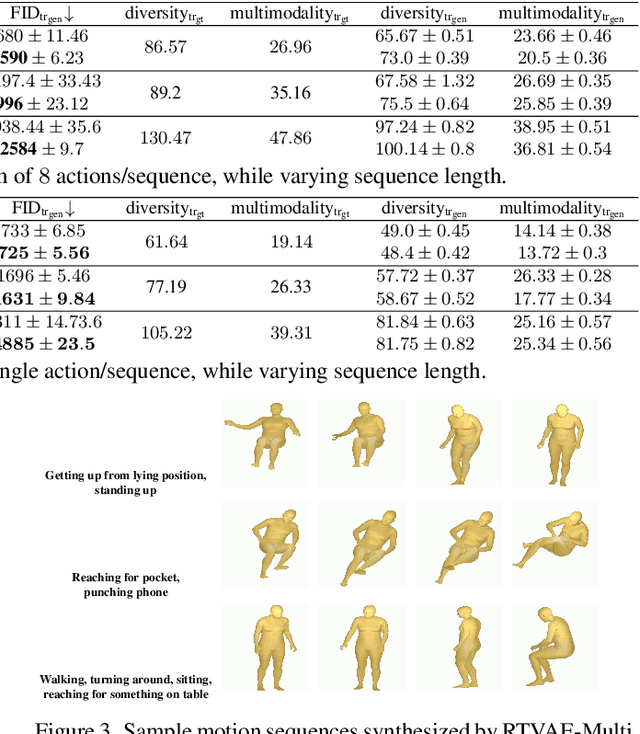
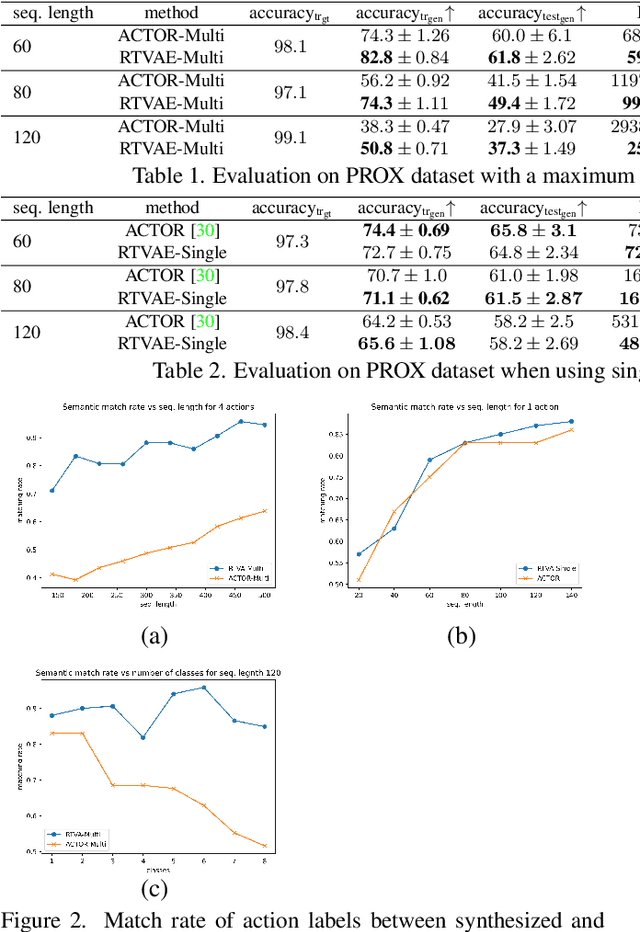

We consider the problem of synthesizing multi-action human motion sequences of arbitrary lengths. Existing approaches have mastered motion sequence generation in single-action scenarios, but fail to generalize to multi-action and arbitrary-length sequences. We fill this gap by proposing a novel efficient approach that leverages the expressiveness of Recurrent Transformers and generative richness of conditional Variational Autoencoders. The proposed iterative approach is able to generate smooth and realistic human motion sequences with an arbitrary number of actions and frames while doing so in linear space and time. We train and evaluate the proposed approach on PROX dataset which we augment with ground-truth action labels. Experimental evaluation shows significant improvements in FID score and semantic consistency metrics compared to the state-of-the-art.