 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect and Explicit 3D Generation from a Single Image
Nov 17, 2024



Current image-to-3D approaches suffer from high computational costs and lack scalability for high-resolution outputs. In contrast, we introduce a novel framework to directly generate explicit surface geometry and texture using multi-view 2D depth and RGB images along with 3D Gaussian features using a repurposed Stable Diffusion model. We introduce a depth branch into U-Net for efficient and high quality multi-view, cross-domain generation and incorporate epipolar attention into the latent-to-pixel decoder for pixel-level multi-view consistency. By back-projecting the generated depth pixels into 3D space, we create a structured 3D representation that can be either rendered via Gaussian splatting or extracted to high-quality meshes, thereby leveraging additional novel view synthesis loss to further improve our performance. Extensive experiments demonstrate that our method surpasses existing baselines in geometry and texture quality while achieving significantly faster generation time.
Direct May Not Be the Best: An Incremental Evolution View of Pose Generation
Apr 15, 2024Pose diversity is an inherent representative characteristic of 2D images. Due to the 3D to 2D projection mechanism, there is evident content discrepancy among distinct pose images. This is the main obstacle bothering pose transformation related researches. To deal with this challenge, we propose a fine-grained incremental evolution centered pose generation framework, rather than traditional direct one-to-one in a rush. Since proposed approach actually bypasses the theoretical difficulty of directly modeling dramatic non-linear variation, the incurred content distortion and blurring could be effectively constrained, at the same time the various individual pose details, especially clothes texture, could be precisely maintained. In order to systematically guide the evolution course, both global and incremental evolution constraints are elaborately designed and merged into the overall framework. And a novel triple-path knowledge fusion structure is worked out to take full advantage of all available valuable knowledge to conduct high-quality pose synthesis. In addition, our framework could generate a series of valuable byproducts, namely the various intermediate poses. Extensive experiments have been conducted to verify the effectiveness of the proposed approach. Code is available at https://github.com/Xiaofei-CN/Incremental-Evolution-Pose-Generation.
MRC-Net: 6-DoF Pose Estimation with MultiScale Residual Correlation
Mar 20, 2024We propose a single-shot approach to determining 6-DoF pose of an object with available 3D computer-aided design (CAD) model from a single RGB image. Our method, dubbed MRC-Net, comprises two stages. The first performs pose classification and renders the 3D object in the classified pose. The second stage performs regression to predict fine-grained residual pose within class. Connecting the two stages is a novel multi-scale residual correlation (MRC) layer that captures high-and-low level correspondences between the input image and rendering from first stage. MRC-Net employs a Siamese network with shared weights between both stages to learn embeddings for input and rendered images. To mitigate ambiguity when predicting discrete pose class labels on symmetric objects, we use soft probabilistic labels to define pose class in the first stage. We demonstrate state-of-the-art accuracy, outperforming all competing RGB-based methods on four challenging BOP benchmark datasets: T-LESS, LM-O, YCB-V, and ITODD. Our method is non-iterative and requires no complex post-processing.
Deep, convergent, unrolled half-quadratic splitting for image deconvolution
Feb 25, 2024



In recent years, algorithm unrolling has emerged as a powerful technique for designing interpretable neural networks based on iterative algorithms. Imaging inverse problems have particularly benefited from unrolling-based deep network design since many traditional model-based approaches rely on iterative optimization. Despite exciting progress, typical unrolling approaches heuristically design layer-specific convolution weights to improve performance. Crucially, convergence properties of the underlying iterative algorithm are lost once layer-specific parameters are learned from training data. We propose an unrolling technique that breaks the trade-off between retaining algorithm properties while simultaneously enhancing performance. We focus on image deblurring and unrolling the widely-applied Half-Quadratic Splitting (HQS) algorithm. We develop a new parametrization scheme which enforces layer-specific parameters to asymptotically approach certain fixed points. Through extensive experimental studies, we verify that our approach achieves competitive performance with state-of-the-art unrolled layer-specific learning and significantly improves over the traditional HQS algorithm. We further establish convergence of the proposed unrolled network as the number of layers approaches infinity, and characterize its convergence rate. Our experimental verification involves simulations that validate the analytical results as well as comparison with state-of-the-art non-blind deblurring techniques on benchmark datasets. The merits of the proposed convergent unrolled network are established over competing alternatives, especially in the regime of limited training.
Deep Algorithm Unrolling for Biomedical Imaging
Aug 15, 2021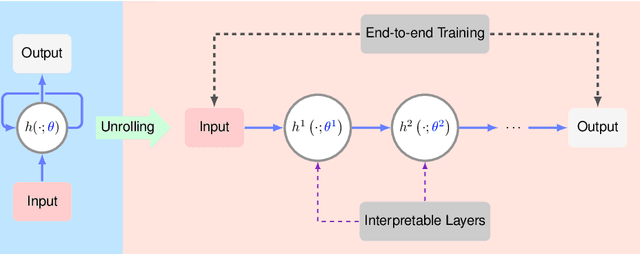
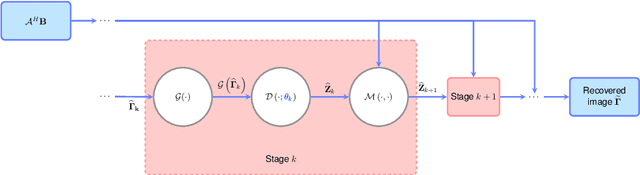
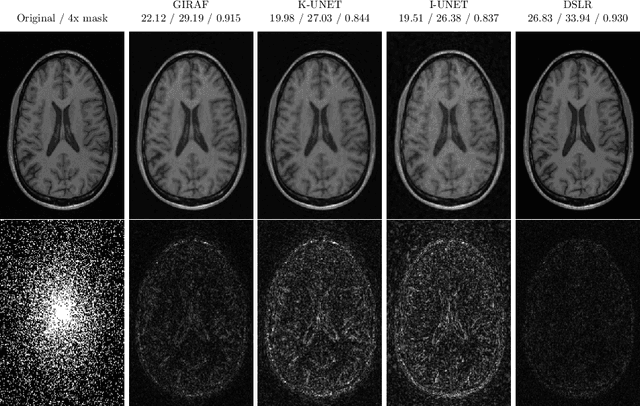
In this chapter, we review biomedical applications and breakthroughs via leveraging algorithm unrolling, an important technique that bridges between traditional iterative algorithms and modern deep learning techniques. To provide context, we start by tracing the origin of algorithm unrolling and providing a comprehensive tutorial on how to unroll iterative algorithms into deep networks. We then extensively cover algorithm unrolling in a wide variety of biomedical imaging modalities and delve into several representative recent works in detail. Indeed, there is a rich history of iterative algorithms for biomedical image synthesis, which makes the field ripe for unrolling techniques. In addition, we put algorithm unrolling into a broad perspective, in order to understand why it is particularly effective and discuss recent trends. Finally, we conclude the chapter by discussing open challenges, and suggesting future research directions.
Algorithm Unrolling: Interpretable, Efficient Deep Learning for Signal and Image Processing
Dec 22, 2019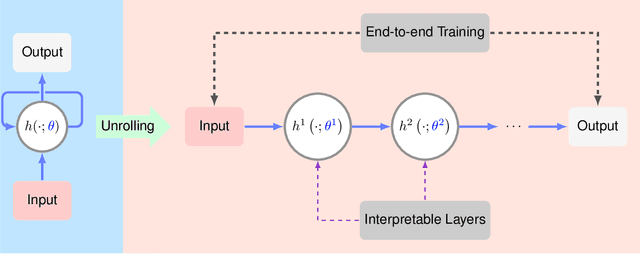
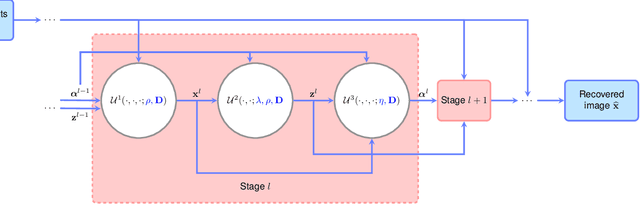

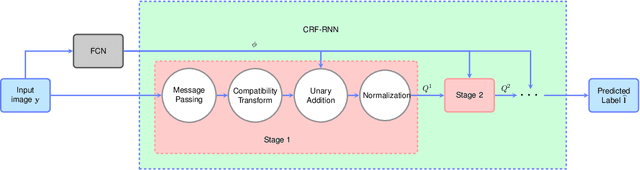
Deep neural networks provide unprecedented performance gains in many real world problems in signal and image processing. Despite these gains, future development and practical deployment of deep networks is hindered by their blackbox nature, i.e., lack of interpretability, and by the need for very large training sets. An emerging technique called algorithm unrolling or unfolding offers promise in eliminating these issues by providing a concrete and systematic connection between iterative algorithms that are used widely in signal processing and deep neural networks. Unrolling methods were first proposed to develop fast neural network approximations for sparse coding. More recently, this direction has attracted enormous attention and is rapidly growing both in theoretic investigations and practical applications. The growing popularity of unrolled deep networks is due in part to their potential in developing efficient, high-performance and yet interpretable network architectures from reasonable size training sets. In this article, we review algorithm unrolling for signal and image processing. We extensively cover popular techniques for algorithm unrolling in various domains of signal and image processing including imaging, vision and recognition, and speech processing. By reviewing previous works, we reveal the connections between iterative algorithms and neural networks and present recent theoretical results. Finally, we provide a discussion on current limitations of unrolling and suggest possible future research directions.
Robust Alignment for Panoramic Stitching via an Exact Rank Constraint
Apr 01, 2019
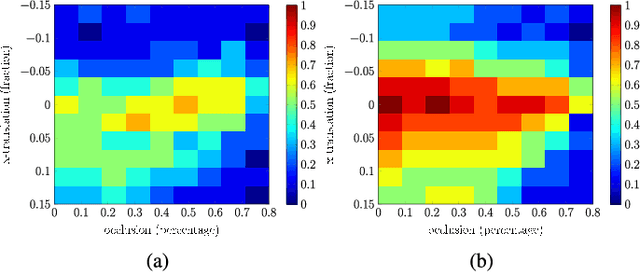


We study the problem of image alignment for panoramic stitching. Unlike most existing approaches that are feature-based, our algorithm works on pixels directly, and accounts for errors across the whole images globally. Technically, we formulate the alignment problem as rank-1 and sparse matrix decomposition over transformed images, and develop an efficient algorithm for solving this challenging non-convex optimization problem. The algorithm reduces to solving a sequence of subproblems, where we analytically establish exact recovery conditions, convergence and optimality, together with convergence rate and complexity. We generalize it to simultaneously align multiple images and recover multiple homographies, extending its application scope towards vast majority of practical scenarios. Experimental results demonstrate that the proposed algorithm is capable of more accurately aligning the images and generating higher quality stitched images than state-of-the-art methods.
An Algorithm Unrolling Approach to Deep Blind Image Deblurring
Mar 11, 2019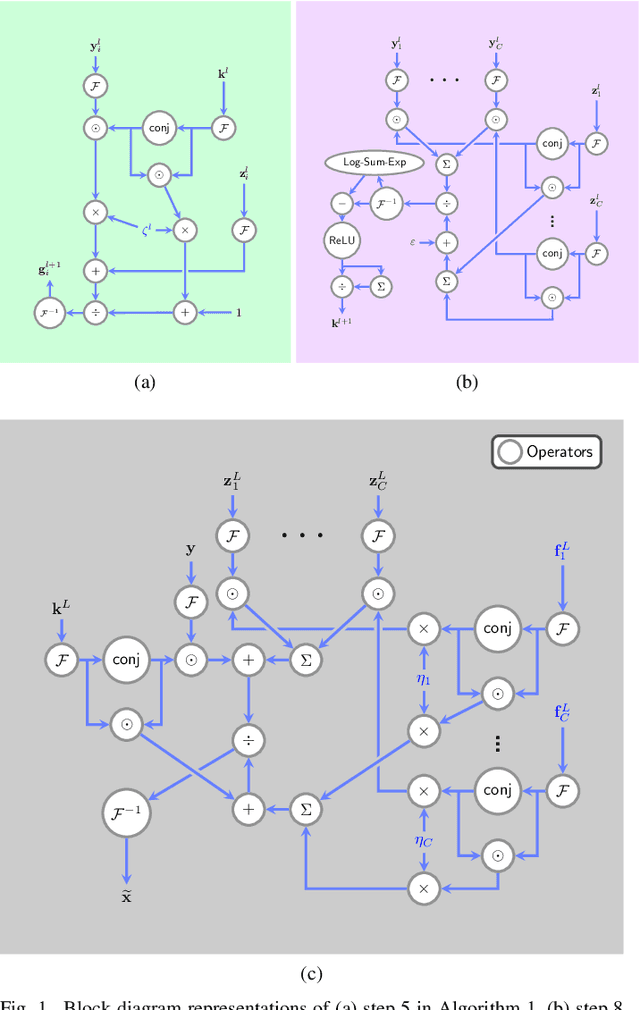

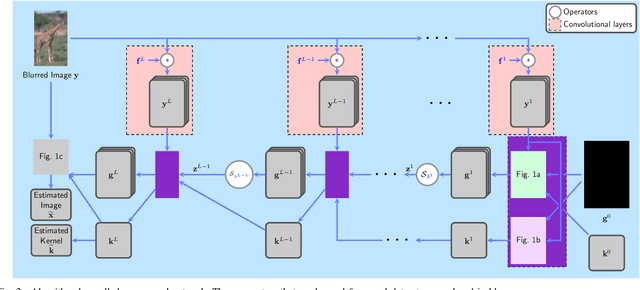
Blind image deblurring remains a topic of enduring interest. Learning based approaches, especially those that employ neural networks have emerged to complement traditional model based methods and in many cases achieve vastly enhanced performance. That said, neural network approaches are generally empirically designed and the underlying structures are difficult to interpret. In recent years, a promising technique called algorithm unrolling has been developed that has helped connect iterative algorithms such as those for sparse coding to neural network architectures. However, such connections have not been made yet for blind image deblurring. In this paper, we propose a neural network architecture based on this idea. We first present an iterative algorithm that may be considered as a generalization of the traditional total-variation regularization method in the gradient domain. We then unroll the algorithm to construct a neural network for image deblurring which we refer to as Deep Unrolling for Blind Deblurring (DUBLID). Key algorithm parameters are learned with the help of training images. Our proposed deep network DUBLID achieves significant practical performance gains while enjoying interpretability at the same time. Extensive experimental results show that DUBLID outperforms many state-of-the-art methods and in addition is computationally faster.
An Algorithm Unrolling Approach to Deep Image Deblurring
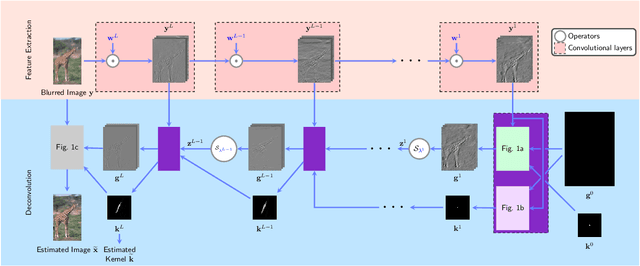
Feb 15, 2019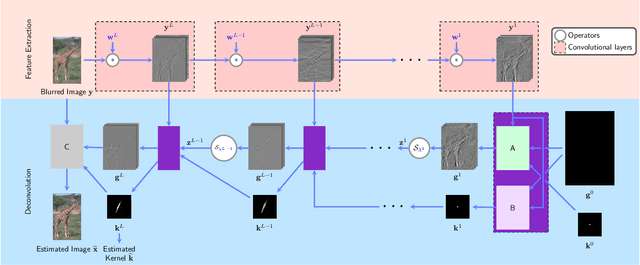
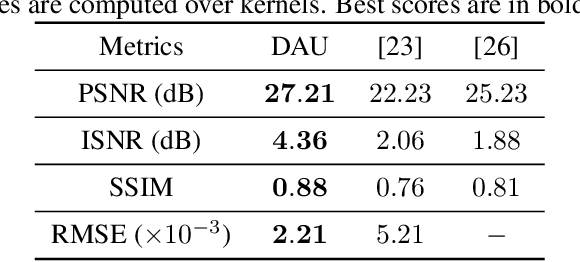
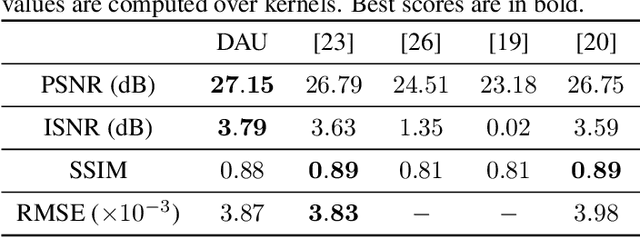

While neural networks have achieved vastly enhanced performance over traditional iterative methods in many cases, they are generally empirically designed and the underlying structures are difficult to interpret. The algorithm unrolling approach has helped connect iterative algorithms to neural network architectures. However, such connections have not been made yet for blind image deblurring. In this paper, we propose a neural network architecture that advances this idea. We first present an iterative algorithm that may be considered a generalization of the traditional total-variation regularization method on the gradient domain, and subsequently unroll the half-quadratic splitting algorithm to construct a neural network. Our proposed deep network achieves significant practical performance gains while enjoying interpretability at the same time. Experimental results show that our approach outperforms many state-of-the-art methods.
Blind Image Deblurring Using Row-Column Sparse Representations
Dec 05, 2017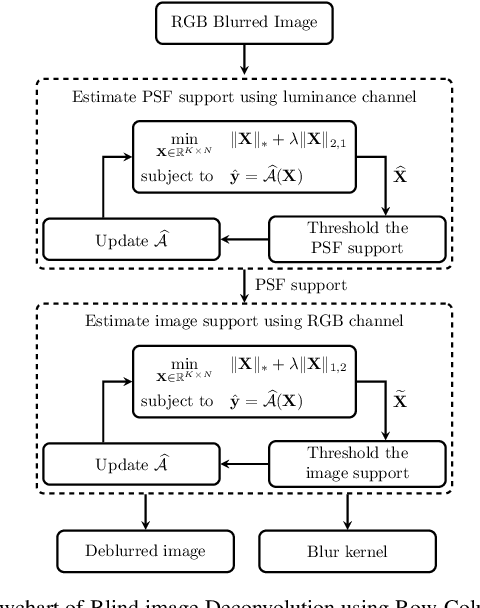



Blind image deblurring is a particularly challenging inverse problem where the blur kernel is unknown and must be estimated en route to recover the deblurred image. The problem is of strong practical relevance since many imaging devices such as cellphone cameras, must rely on deblurring algorithms to yield satisfactory image quality. Despite significant research effort, handling large motions remains an open problem. In this paper, we develop a new method called Blind Image Deblurring using Row-Column Sparsity (BD-RCS) to address this issue. Specifically, we model the outer product of kernel and image coefficients in certain transformation domains as a rank-one matrix, and recover it by solving a rank minimization problem. Our central contribution then includes solving {\em two new} optimization problems involving row and column sparsity to automatically determine blur kernel and image support sequentially. The kernel and image can then be recovered through a singular value decomposition (SVD). Experimental results on linear motion deblurring demonstrate that BD-RCS can yield better results than state of the art, particularly when the blur is caused by large motion. This is confirmed both visually and through quantitative measures.