 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCHNet: SAM Marries CLIP for Human Parsing
Mar 28, 2025Vision Foundation Model (VFM) such as the Segment Anything Model (SAM) and Contrastive Language-Image Pre-training Model (CLIP) has shown promising performance for segmentation and detection tasks. However, although SAM excels in fine-grained segmentation, it faces major challenges when applying it to semantic-aware segmentation. While CLIP exhibits a strong semantic understanding capability via aligning the global features of language and vision, it has deficiencies in fine-grained segmentation tasks. Human parsing requires to segment human bodies into constituent parts and involves both accurate fine-grained segmentation and high semantic understanding of each part. Based on traits of SAM and CLIP, we formulate high efficient modules to effectively integrate features of them to benefit human parsing. We propose a Semantic-Refinement Module to integrate semantic features of CLIP with SAM features to benefit parsing. Moreover, we formulate a high efficient Fine-tuning Module to adjust the pretrained SAM for human parsing that needs high semantic information and simultaneously demands spatial details, which significantly reduces the training time compared with full-time training and achieves notable performance. Extensive experiments demonstrate the effectiveness of our method on LIP, PPP, and CIHP databases.
Research on gesture recognition method based on SEDCNN-SVM
Oct 24, 2024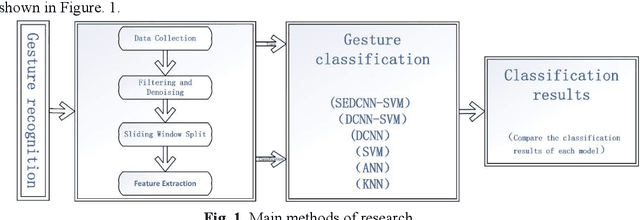
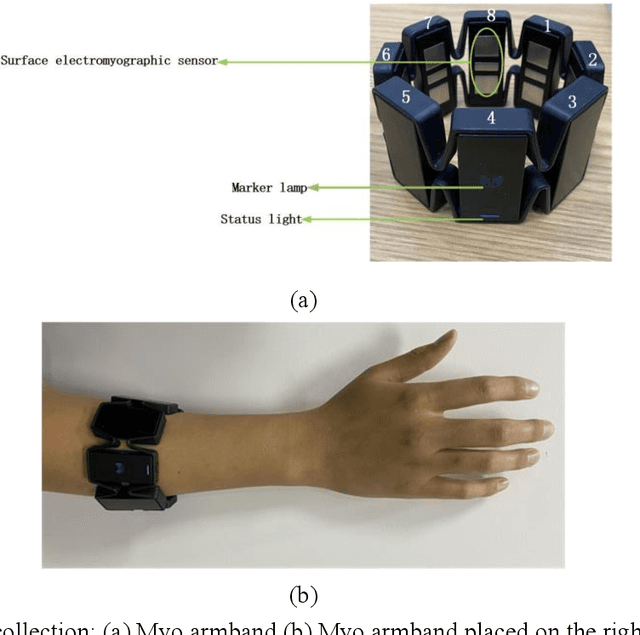
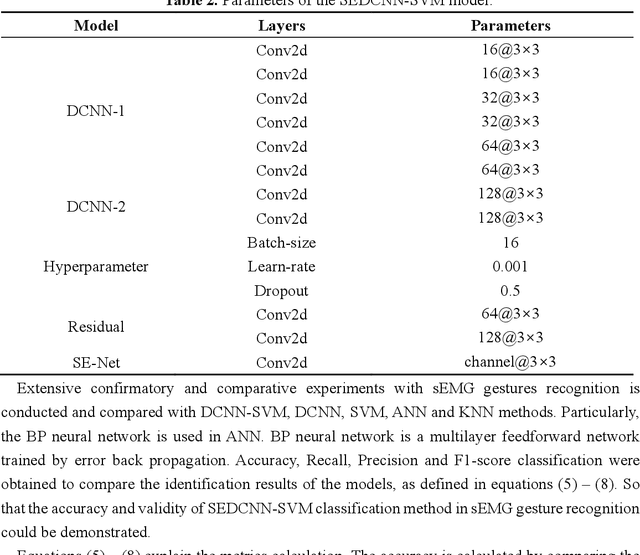

Gesture recognition based on surface electromyographic signal (sEMG) is one of the most used methods. The traditional manual feature extraction can only extract some low-level signal features, this causes poor classifier performance and low recognition accuracy when dealing with some complex signals. A recognition method, namely SEDCNN-SVM, is proposed to recognize sEMG of different gestures. SEDCNN-SVM consists of an improved deep convolutional neural network (DCNN) and a support vector machine (SVM). The DCNN can automatically extract and learn the feature information of sEMG through the convolution operation of the convolutional layer, so that it can capture the complex and high-level features in the data. The Squeeze and Excitation Networks (SE-Net) and the residual module were added to the model, so that the feature representation of each channel could be improved, the loss of feature information in convolutional operations was reduced, useful feature information was captured, and the problem of network gradient vanishing was eased. The SVM can improve the generalization ability and classification accuracy of the model by constructing an optimal hyperplane of the feature space. Hence, the SVM was used to replace the full connection layer and the Softmax function layer of the DCNN, the use of a suitable kernel function in SVM can improve the model's generalization ability and classification accuracy. To verify the effectiveness of the proposed classification algorithm, this method is analyzed and compared with other comparative classification methods. The recognition accuracy of SEDCNN-SVM can reach 0.955, it is significantly improved compared with other classification methods, the SEDCNN-SVM model is recognized online in real time.
Direct May Not Be the Best: An Incremental Evolution View of Pose Generation
Apr 15, 2024Pose diversity is an inherent representative characteristic of 2D images. Due to the 3D to 2D projection mechanism, there is evident content discrepancy among distinct pose images. This is the main obstacle bothering pose transformation related researches. To deal with this challenge, we propose a fine-grained incremental evolution centered pose generation framework, rather than traditional direct one-to-one in a rush. Since proposed approach actually bypasses the theoretical difficulty of directly modeling dramatic non-linear variation, the incurred content distortion and blurring could be effectively constrained, at the same time the various individual pose details, especially clothes texture, could be precisely maintained. In order to systematically guide the evolution course, both global and incremental evolution constraints are elaborately designed and merged into the overall framework. And a novel triple-path knowledge fusion structure is worked out to take full advantage of all available valuable knowledge to conduct high-quality pose synthesis. In addition, our framework could generate a series of valuable byproducts, namely the various intermediate poses. Extensive experiments have been conducted to verify the effectiveness of the proposed approach. Code is available at https://github.com/Xiaofei-CN/Incremental-Evolution-Pose-Generation.
CDGNet: Class Distribution Guided Network for Human Parsing
Nov 28, 2021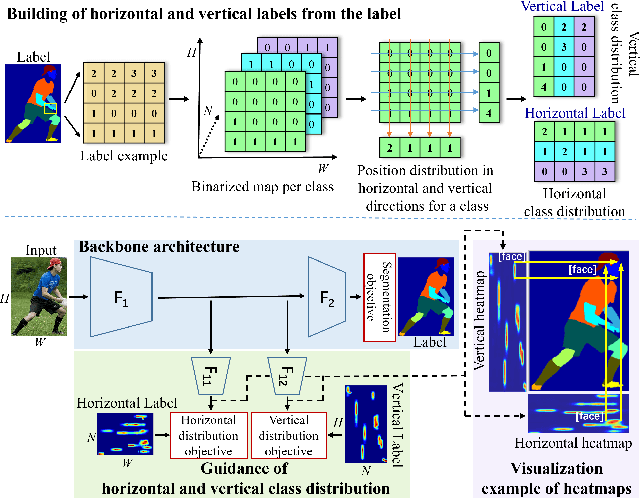

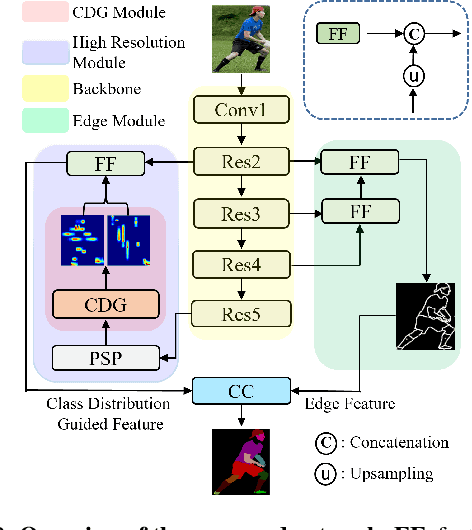
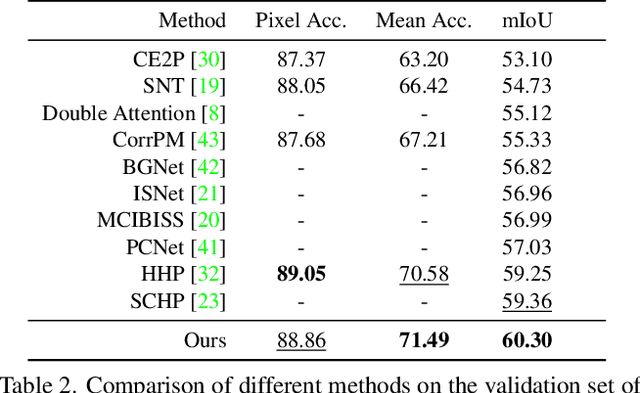
The objective of human parsing is to partition a human in an image into constituent parts. This task involves labeling each pixel of the human image according to the classes. Since the human body comprises hierarchically structured parts, each body part of an image can have its sole position distribution characteristics. Probably, a human head is less likely to be under the feet, and arms are more likely to be near the torso. Inspired by this observation, we make instance class distributions by accumulating the original human parsing label in the horizontal and vertical directions, which can be utilized as supervision signals. Using these horizontal and vertical class distribution labels, the network is guided to exploit the intrinsic position distribution of each class. We combine two guided features to form a spatial guidance map, which is then superimposed onto the baseline network by multiplication and concatenation to distinguish the human parts precisely. We conducted extensive experiments to demonstrate the effectiveness and superiority of our method on three well-known benchmarks: LIP, ATR, and CIHP databases.
Advancing COVID-19 Diagnosis with Privacy-Preserving Collaboration in Artificial Intelligence
Nov 18, 2021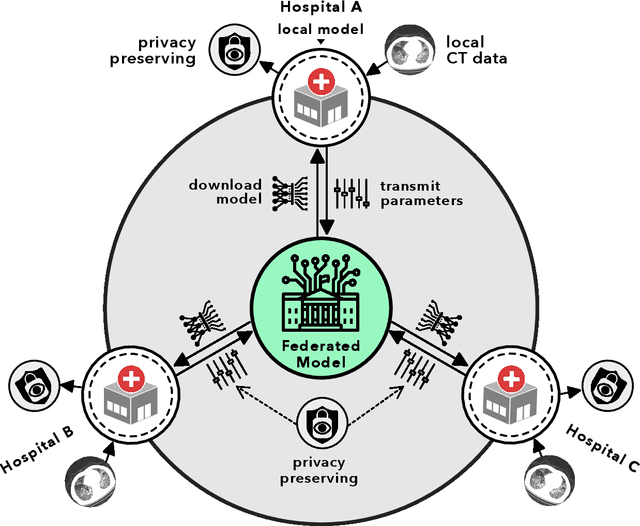
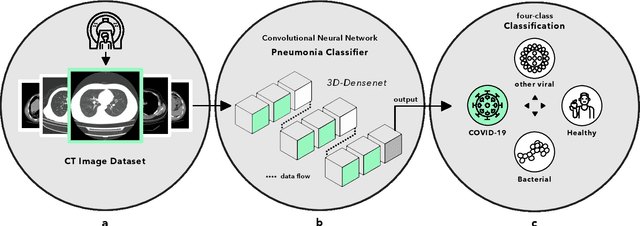
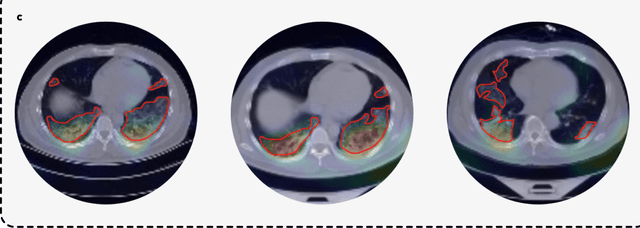
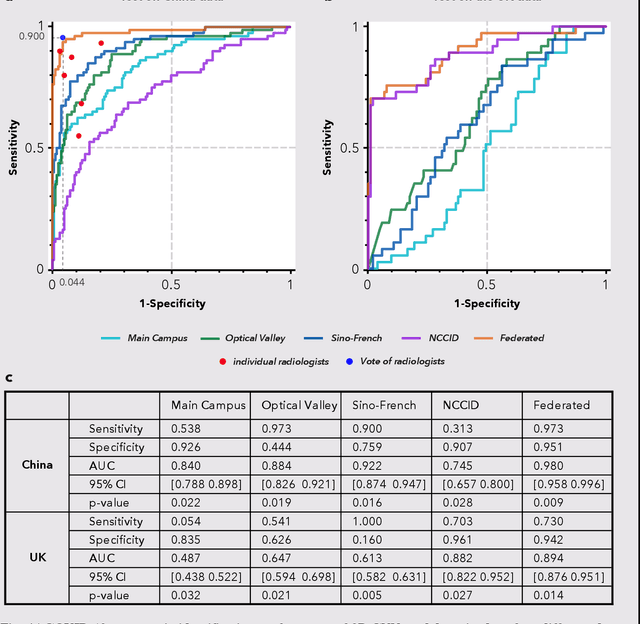
Artificial intelligence (AI) provides a promising substitution for streamlining COVID-19 diagnoses. However, concerns surrounding security and trustworthiness impede the collection of large-scale representative medical data, posing a considerable challenge for training a well-generalised model in clinical practices. To address this, we launch the Unified CT-COVID AI Diagnostic Initiative (UCADI), where the AI model can be distributedly trained and independently executed at each host institution under a federated learning framework (FL) without data sharing. Here we show that our FL model outperformed all the local models by a large yield (test sensitivity /specificity in China: 0.973/0.951, in the UK: 0.730/0.942), achieving comparable performance with a panel of professional radiologists. We further evaluated the model on the hold-out (collected from another two hospitals leaving out the FL) and heterogeneous (acquired with contrast materials) data, provided visual explanations for decisions made by the model, and analysed the trade-offs between the model performance and the communication costs in the federated training process. Our study is based on 9,573 chest computed tomography scans (CTs) from 3,336 patients collected from 23 hospitals located in China and the UK. Collectively, our work advanced the prospects of utilising federated learning for privacy-preserving AI in digital health.
UBER-GNN: A User-Based Embeddings Recommendation based on Graph Neural Networks
Aug 06, 2020
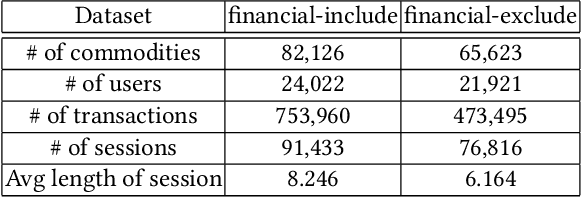
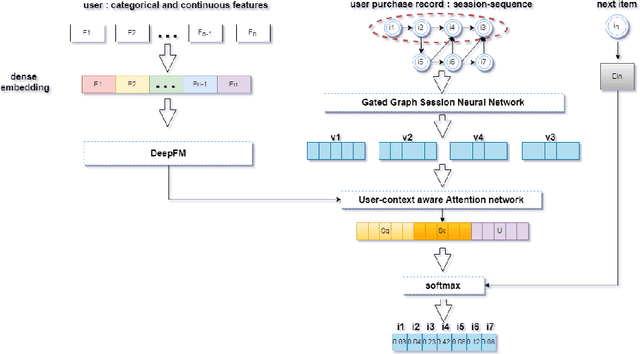
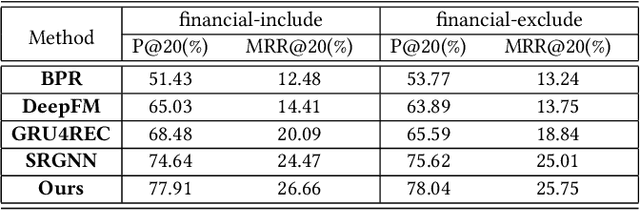
The problem of session-based recommendation aims to predict user next actions based on session histories. Previous methods models session histories into sequences and estimate user latent features by RNN and GNN methods to make recommendations. However under massive-scale and complicated financial recommendation scenarios with both virtual and real commodities , such methods are not sufficient to represent accurate user latent features and neglect the long-term characteristics of users. To take long-term preference and dynamic interests into account, we propose a novel method, i.e. User-Based Embeddings Recommendation with Graph Neural Network, UBER-GNN for brevity. UBER-GNN takes advantage of structured data to generate longterm user preferences, and transfers session sequences into graphs to generate graph-based dynamic interests. The final user latent feature is then represented as the composition of the long-term preferences and the dynamic interests using attention mechanism. Extensive experiments conducted on real Ping An scenario show that UBER-GNN outperforms the state-of-the-art session-based recommendation methods.