 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCHNet: SAM Marries CLIP for Human Parsing
Mar 28, 2025Vision Foundation Model (VFM) such as the Segment Anything Model (SAM) and Contrastive Language-Image Pre-training Model (CLIP) has shown promising performance for segmentation and detection tasks. However, although SAM excels in fine-grained segmentation, it faces major challenges when applying it to semantic-aware segmentation. While CLIP exhibits a strong semantic understanding capability via aligning the global features of language and vision, it has deficiencies in fine-grained segmentation tasks. Human parsing requires to segment human bodies into constituent parts and involves both accurate fine-grained segmentation and high semantic understanding of each part. Based on traits of SAM and CLIP, we formulate high efficient modules to effectively integrate features of them to benefit human parsing. We propose a Semantic-Refinement Module to integrate semantic features of CLIP with SAM features to benefit parsing. Moreover, we formulate a high efficient Fine-tuning Module to adjust the pretrained SAM for human parsing that needs high semantic information and simultaneously demands spatial details, which significantly reduces the training time compared with full-time training and achieves notable performance. Extensive experiments demonstrate the effectiveness of our method on LIP, PPP, and CIHP databases.
CDGNet: Class Distribution Guided Network for Human Parsing
Nov 28, 2021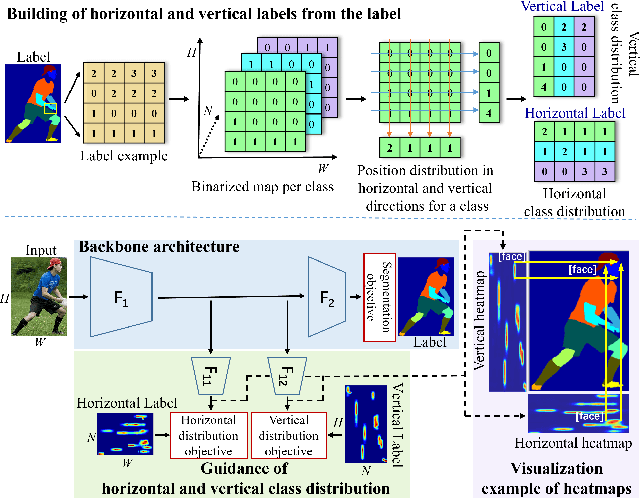

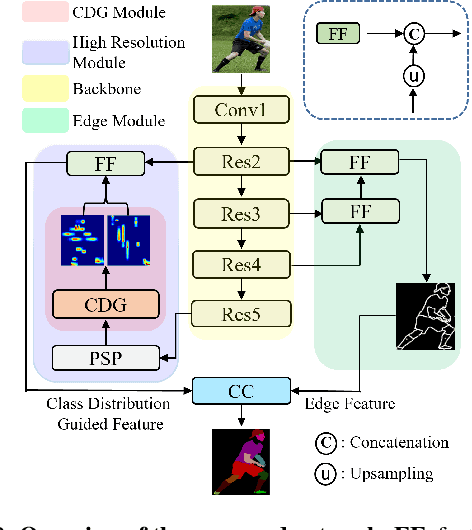
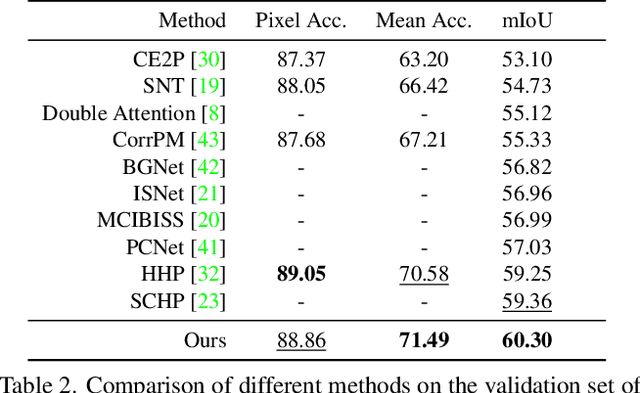
The objective of human parsing is to partition a human in an image into constituent parts. This task involves labeling each pixel of the human image according to the classes. Since the human body comprises hierarchically structured parts, each body part of an image can have its sole position distribution characteristics. Probably, a human head is less likely to be under the feet, and arms are more likely to be near the torso. Inspired by this observation, we make instance class distributions by accumulating the original human parsing label in the horizontal and vertical directions, which can be utilized as supervision signals. Using these horizontal and vertical class distribution labels, the network is guided to exploit the intrinsic position distribution of each class. We combine two guided features to form a spatial guidance map, which is then superimposed onto the baseline network by multiplication and concatenation to distinguish the human parts precisely. We conducted extensive experiments to demonstrate the effectiveness and superiority of our method on three well-known benchmarks: LIP, ATR, and CIHP databases.