 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIRIT: Adapting Vision Foundation Models for Unified Single- and Multi-Frame Infrared Small Target Detection
Feb 02, 2026Infrared small target detection (IRSTD) is crucial for surveillance and early-warning, with deployments spanning both single-frame analysis and video-mode tracking. A practical solution should leverage vision foundation models (VFMs) to mitigate infrared data scarcity, while adopting a memory-attention-based temporal propagation framework that unifies single- and multi-frame inference. However, infrared small targets exhibit weak radiometric signals and limited semantic cues, which differ markedly from visible-spectrum imagery. This modality gap makes direct use of semantics-oriented VFMs and appearance-driven cross-frame association unreliable for IRSTD: hierarchical feature aggregation can submerge localized target peaks, and appearance-only memory attention becomes ambiguous, leading to spurious clutter associations. To address these challenges, we propose SPIRIT, a unified and VFM-compatible framework that adapts VFMs to IRSTD via lightweight physics-informed plug-ins. Spatially, PIFR refines features by approximating rank-sparsity decomposition to suppress structured background components and enhance sparse target-like signals. Temporally, PGMA injects history-derived soft spatial priors into memory cross-attention to constrain cross-frame association, enabling robust video detection while naturally reverting to single-frame inference when temporal context is absent. Experiments on multiple IRSTD benchmarks show consistent gains over VFM-based baselines and SOTA performance.
FedRD: Reducing Divergences for Generalized Federated Learning via Heterogeneity-aware Parameter Guidance
Jan 28, 2026Heterogeneous federated learning (HFL) aims to ensure effective and privacy-preserving collaboration among different entities. As newly joined clients require significant adjustments and additional training to align with the existing system, the problem of generalizing federated learning models to unseen clients under heterogeneous data has become progressively crucial. Consequently, we highlight two unsolved challenging issues in federated domain generalization: Optimization Divergence and Performance Divergence. To tackle the above challenges, we propose FedRD, a novel heterogeneity-aware federated learning algorithm that collaboratively utilizes parameter-guided global generalization aggregation and local debiased classification to reduce divergences, aiming to obtain an optimal global model for participating and unseen clients. Extensive experiments on public multi-domain datasets demonstrate that our approach exhibits a substantial performance advantage over competing baselines in addressing this specific problem.
S-DAG: A Subject-Based Directed Acyclic Graph for Multi-Agent Heterogeneous Reasoning
Nov 19, 2025Large Language Models (LLMs) have achieved impressive performance in complex reasoning problems. Their effectiveness highly depends on the specific nature of the task, especially the required domain knowledge. Existing approaches, such as mixture-of-experts, typically operate at the task level; they are too coarse to effectively solve the heterogeneous problems involving multiple subjects. This work proposes a novel framework that performs fine-grained analysis at subject level equipped with a designated multi-agent collaboration strategy for addressing heterogeneous problem reasoning. Specifically, given an input query, we first employ a Graph Neural Network to identify the relevant subjects and infer their interdependencies to generate an \textit{Subject-based Directed Acyclic Graph} (S-DAG), where nodes represent subjects and edges encode information flow. Then we profile the LLM models by assigning each model a subject-specific expertise score, and select the top-performing one for matching corresponding subject of the S-DAG. Such subject-model matching enables graph-structured multi-agent collaboration where information flows from the starting model to the ending model over S-DAG. We curate and release multi-subject subsets of standard benchmarks (MMLU-Pro, GPQA, MedMCQA) to better reflect complex, real-world reasoning tasks. Extensive experiments show that our approach significantly outperforms existing task-level model selection and multi-agent collaboration baselines in accuracy and efficiency. These results highlight the effectiveness of subject-aware reasoning and structured collaboration in addressing complex and multi-subject problems.
Research on gesture recognition method based on SEDCNN-SVM
Oct 24, 2024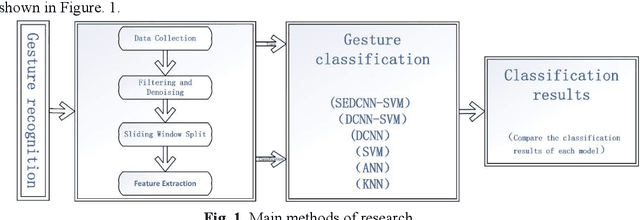
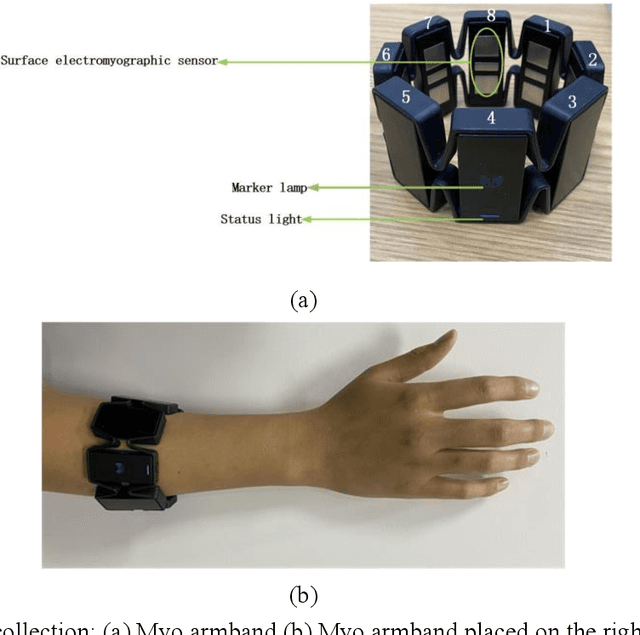
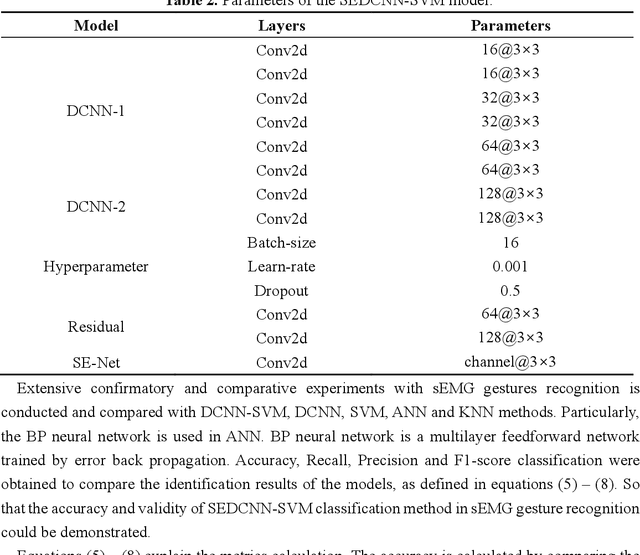

Gesture recognition based on surface electromyographic signal (sEMG) is one of the most used methods. The traditional manual feature extraction can only extract some low-level signal features, this causes poor classifier performance and low recognition accuracy when dealing with some complex signals. A recognition method, namely SEDCNN-SVM, is proposed to recognize sEMG of different gestures. SEDCNN-SVM consists of an improved deep convolutional neural network (DCNN) and a support vector machine (SVM). The DCNN can automatically extract and learn the feature information of sEMG through the convolution operation of the convolutional layer, so that it can capture the complex and high-level features in the data. The Squeeze and Excitation Networks (SE-Net) and the residual module were added to the model, so that the feature representation of each channel could be improved, the loss of feature information in convolutional operations was reduced, useful feature information was captured, and the problem of network gradient vanishing was eased. The SVM can improve the generalization ability and classification accuracy of the model by constructing an optimal hyperplane of the feature space. Hence, the SVM was used to replace the full connection layer and the Softmax function layer of the DCNN, the use of a suitable kernel function in SVM can improve the model's generalization ability and classification accuracy. To verify the effectiveness of the proposed classification algorithm, this method is analyzed and compared with other comparative classification methods. The recognition accuracy of SEDCNN-SVM can reach 0.955, it is significantly improved compared with other classification methods, the SEDCNN-SVM model is recognized online in real time.
Unleashing the Power of Generic Segmentation Models: A Simple Baseline for Infrared Small Target Detection
Sep 07, 2024Recent advancements in deep learning have greatly advanced the field of infrared small object detection (IRSTD). Despite their remarkable success, a notable gap persists between these IRSTD methods and generic segmentation approaches in natural image domains. This gap primarily arises from the significant modality differences and the limited availability of infrared data. In this study, we aim to bridge this divergence by investigating the adaptation of generic segmentation models, such as the Segment Anything Model (SAM), to IRSTD tasks. Our investigation reveals that many generic segmentation models can achieve comparable performance to state-of-the-art IRSTD methods. However, their full potential in IRSTD remains untapped. To address this, we propose a simple, lightweight, yet effective baseline model for segmenting small infrared objects. Through appropriate distillation strategies, we empower smaller student models to outperform state-of-the-art methods, even surpassing fine-tuned teacher results. Furthermore, we enhance the model's performance by introducing a novel query design comprising dense and sparse queries to effectively encode multi-scale features. Through extensive experimentation across four popular IRSTD datasets, our model demonstrates significantly improved performance in both accuracy and throughput compared to existing approaches, surpassing SAM and Semantic-SAM by over 14 IoU on NUDT and 4 IoU on IRSTD1k. The source code and models will be released at https://github.com/O937-blip/SimIR.
IRSAM: Advancing Segment Anything Model for Infrared Small Target Detection
Jul 10, 2024



The recent Segment Anything Model (SAM) is a significant advancement in natural image segmentation, exhibiting potent zero-shot performance suitable for various downstream image segmentation tasks. However, directly utilizing the pretrained SAM for Infrared Small Target Detection (IRSTD) task falls short in achieving satisfying performance due to a notable domain gap between natural and infrared images. Unlike a visible light camera, a thermal imager reveals an object's temperature distribution by capturing infrared radiation. Small targets often show a subtle temperature transition at the object's boundaries. To address this issue, we propose the IRSAM model for IRSTD, which improves SAM's encoder-decoder architecture to learn better feature representation of infrared small objects. Specifically, we design a Perona-Malik diffusion (PMD)-based block and incorporate it into multiple levels of SAM's encoder to help it capture essential structural features while suppressing noise. Additionally, we devise a Granularity-Aware Decoder (GAD) to fuse the multi-granularity feature from the encoder to capture structural information that may be lost in long-distance modeling. Extensive experiments on the public datasets, including NUAA-SIRST, NUDT-SIRST, and IRSTD-1K, validate the design choice of IRSAM and its significant superiority over representative state-of-the-art methods. The source code are available at: github.com/IPIC-Lab/IRSAM.
Digital Twin-assisted Reinforcement Learning for Resource-aware Microservice Offloading in Edge Computing
Mar 13, 2024



Collaborative edge computing (CEC) has emerged as a promising paradigm, enabling edge nodes to collaborate and execute microservices from end devices. Microservice offloading, a fundamentally important problem, decides when and where microservices are executed upon the arrival of services. However, the dynamic nature of the real-world CEC environment often leads to inefficient microservice offloading strategies, resulting in underutilized resources and network congestion. To address this challenge, we formulate an online joint microservice offloading and bandwidth allocation problem, JMOBA, to minimize the average completion time of services. In this paper, we introduce a novel microservice offloading algorithm, DTDRLMO, which leverages deep reinforcement learning (DRL) and digital twin technology. Specifically, we employ digital twin techniques to predict and adapt to changing edge node loads and network conditions of CEC in real-time. Furthermore, this approach enables the generation of an efficient offloading plan, selecting the most suitable edge node for each microservice. Simulation results on real-world and synthetic datasets demonstrate that DTDRLMO outperforms heuristic and learning-based methods in average service completion time.
* 9 pages, 5 figures
ESSAformer: Efficient Transformer for Hyperspectral Image Super-resolution
Jul 26, 2023



Single hyperspectral image super-resolution (single-HSI-SR) aims to restore a high-resolution hyperspectral image from a low-resolution observation. However, the prevailing CNN-based approaches have shown limitations in building long-range dependencies and capturing interaction information between spectral features. This results in inadequate utilization of spectral information and artifacts after upsampling. To address this issue, we propose ESSAformer, an ESSA attention-embedded Transformer network for single-HSI-SR with an iterative refining structure. Specifically, we first introduce a robust and spectral-friendly similarity metric, \ie, the spectral correlation coefficient of the spectrum (SCC), to replace the original attention matrix and incorporates inductive biases into the model to facilitate training. Built upon it, we further utilize the kernelizable attention technique with theoretical support to form a novel efficient SCC-kernel-based self-attention (ESSA) and reduce attention computation to linear complexity. ESSA enlarges the receptive field for features after upsampling without bringing much computation and allows the model to effectively utilize spatial-spectral information from different scales, resulting in the generation of more natural high-resolution images. Without the need for pretraining on large-scale datasets, our experiments demonstrate ESSA's effectiveness in both visual quality and quantitative results.
SAR-to-Optical Image Translation via Thermodynamics-inspired Network
May 23, 2023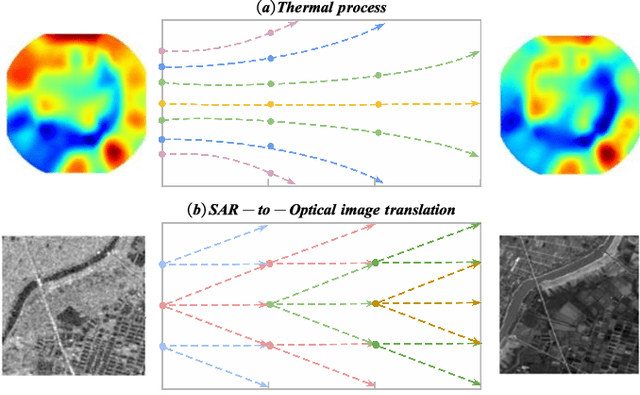
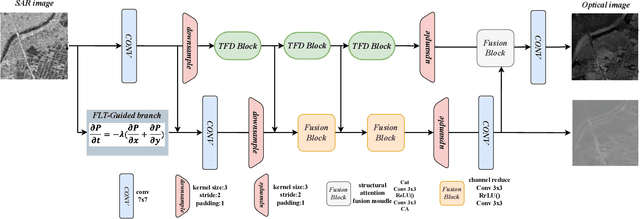
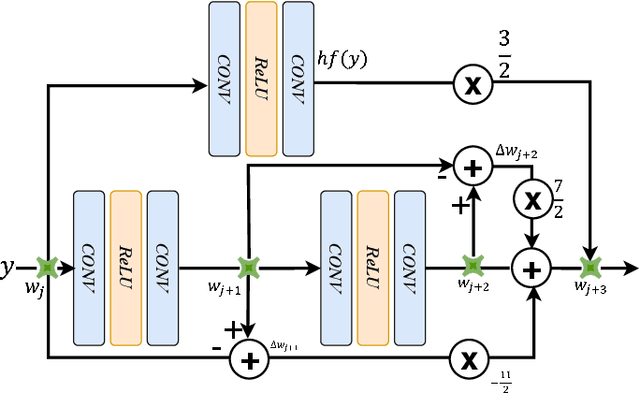
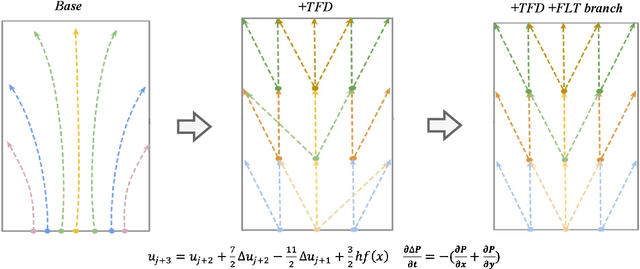
Synthetic aperture radar (SAR) is prevalent in the remote sensing field but is difficult to interpret in human visual perception. Recently, SAR-to-optical (S2O) image conversion methods have provided a prospective solution for interpretation. However, since there is a huge domain difference between optical and SAR images, they suffer from low image quality and geometric distortion in the produced optical images. Motivated by the analogy between pixels during the S2O image translation and molecules in a heat field, Thermodynamics-inspired Network for SAR-to-Optical Image Translation (S2O-TDN) is proposed in this paper. Specifically, we design a Third-order Finite Difference (TFD) residual structure in light of the TFD equation of thermodynamics, which allows us to efficiently extract inter-domain invariant features and facilitate the learning of the nonlinear translation mapping. In addition, we exploit the first law of thermodynamics (FLT) to devise an FLT-guided branch that promotes the state transition of the feature values from the unstable diffusion state to the stable one, aiming to regularize the feature diffusion and preserve image structures during S2O image translation. S2O-TDN follows an explicit design principle derived from thermodynamic theory and enjoys the advantage of explainability. Experiments on the public SEN1-2 dataset show the advantages of the proposed S2O-TDN over the current methods with more delicate textures and higher quantitative results.
E-Tree Learning: A Novel Decentralized Model Learning Framework for Edge AI
Aug 04, 2020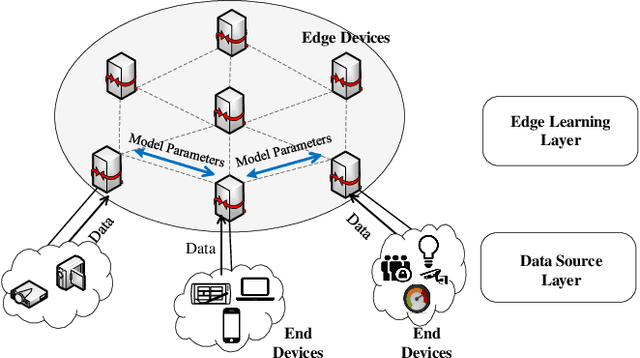

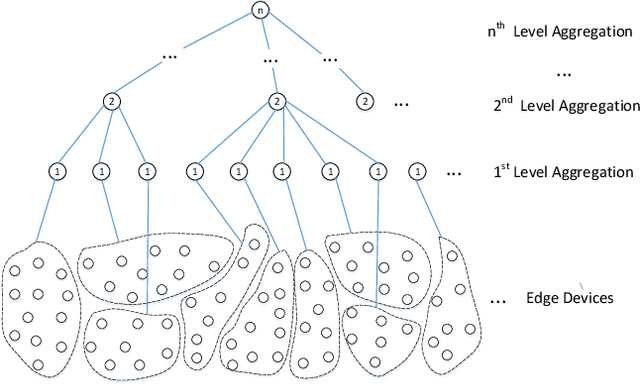
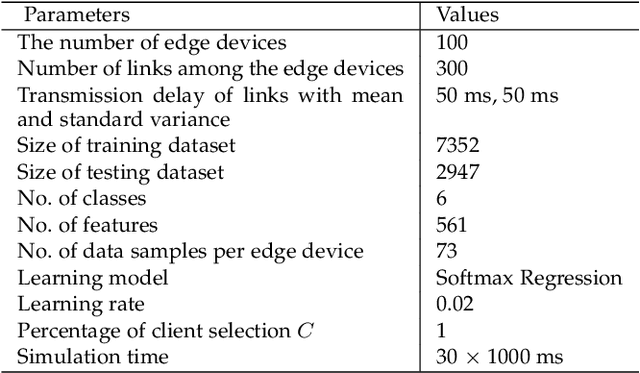
Traditionally, AI models are trained on the central cloud with data collected from end devices. This leads to high communication cost, long response time and privacy concerns. Recently Edge empowered AI, namely Edge AI, has been proposed to support AI model learning and deployment at the network edge closer to the data sources. Existing research including federated learning adopts a centralized architecture for model learning where a central server aggregates the model updates from the clients/workers. The centralized architecture has drawbacks such as performance bottleneck, poor scalability and single point of failure. In this paper, we propose a novel decentralized model learning approach, namely E-Tree, which makes use of a well-designed tree structure imposed on the edge devices. The tree structure and the locations and orders of aggregation on the tree are optimally designed to improve the training convergency and model accuracy. In particular, we design an efficient device clustering algorithm, named by KMA, for E-Tree by taking into account the data distribution on the devices as well as the the network distance. Evaluation results show E-Tree significantly outperforms the benchmark approaches such as federated learning and Gossip learning under NonIID data in terms of model accuracy and convergency.