 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBADGR: Bundle Adjustment Diffusion Conditioned by GRadients for Wide-Baseline Floor Plan Reconstruction
Mar 25, 2025



Reconstructing precise camera poses and floor plan layouts from wide-baseline RGB panoramas is a difficult and unsolved problem. We introduce BADGR, a novel diffusion model that jointly performs reconstruction and bundle adjustment (BA) to refine poses and layouts from a coarse state, using 1D floor boundary predictions from dozens of images of varying input densities. Unlike a guided diffusion model, BADGR is conditioned on dense per-entity outputs from a single-step Levenberg Marquardt (LM) optimizer and is trained to predict camera and wall positions while minimizing reprojection errors for view-consistency. The objective of layout generation from denoising diffusion process complements BA optimization by providing additional learned layout-structural constraints on top of the co-visible features across images. These constraints help BADGR to make plausible guesses on spatial relations which help constrain pose graph, such as wall adjacency, collinearity, and learn to mitigate errors from dense boundary observations with global contexts. BADGR trains exclusively on 2D floor plans, simplifying data acquisition, enabling robust augmentation, and supporting variety of input densities. Our experiments and analysis validate our method, which significantly outperforms the state-of-the-art pose and floor plan layout reconstruction with different input densities.
StableDreamer: Taming Noisy Score Distillation Sampling for Text-to-3D
Dec 02, 2023



In the realm of text-to-3D generation, utilizing 2D diffusion models through score distillation sampling (SDS) frequently leads to issues such as blurred appearances and multi-faced geometry, primarily due to the intrinsically noisy nature of the SDS loss. Our analysis identifies the core of these challenges as the interaction among noise levels in the 2D diffusion process, the architecture of the diffusion network, and the 3D model representation. To overcome these limitations, we present StableDreamer, a methodology incorporating three advances. First, inspired by InstructNeRF2NeRF, we formalize the equivalence of the SDS generative prior and a simple supervised L2 reconstruction loss. This finding provides a novel tool to debug SDS, which we use to show the impact of time-annealing noise levels on reducing multi-faced geometries. Second, our analysis shows that while image-space diffusion contributes to geometric precision, latent-space diffusion is crucial for vivid color rendition. Based on this observation, StableDreamer introduces a two-stage training strategy that effectively combines these aspects, resulting in high-fidelity 3D models. Third, we adopt an anisotropic 3D Gaussians representation, replacing Neural Radiance Fields (NeRFs), to enhance the overall quality, reduce memory usage during training, and accelerate rendering speeds, and better capture semi-transparent objects. StableDreamer reduces multi-face geometries, generates fine details, and converges stably.
Is Generalized Dynamic Novel View Synthesis from Monocular Videos Possible Today?
Oct 12, 2023



Rendering scenes observed in a monocular video from novel viewpoints is a challenging problem. For static scenes the community has studied both scene-specific optimization techniques, which optimize on every test scene, and generalized techniques, which only run a deep net forward pass on a test scene. In contrast, for dynamic scenes, scene-specific optimization techniques exist, but, to our best knowledge, there is currently no generalized method for dynamic novel view synthesis from a given monocular video. To answer whether generalized dynamic novel view synthesis from monocular videos is possible today, we establish an analysis framework based on existing techniques and work toward the generalized approach. We find a pseudo-generalized process without scene-specific appearance optimization is possible, but geometrically and temporally consistent depth estimates are needed. Despite no scene-specific appearance optimization, the pseudo-generalized approach improves upon some scene-specific methods.
AutoFocusFormer: Image Segmentation off the Grid
Apr 24, 2023Real world images often have highly imbalanced content density. Some areas are very uniform, e.g., large patches of blue sky, while other areas are scattered with many small objects. Yet, the commonly used successive grid downsampling strategy in convolutional deep networks treats all areas equally. Hence, small objects are represented in very few spatial locations, leading to worse results in tasks such as segmentation. Intuitively, retaining more pixels representing small objects during downsampling helps to preserve important information. To achieve this, we propose AutoFocusFormer (AFF), a local-attention transformer image recognition backbone, which performs adaptive downsampling by learning to retain the most important pixels for the task. Since adaptive downsampling generates a set of pixels irregularly distributed on the image plane, we abandon the classic grid structure. Instead, we develop a novel point-based local attention block, facilitated by a balanced clustering module and a learnable neighborhood merging module, which yields representations for our point-based versions of state-of-the-art segmentation heads. Experiments show that our AutoFocusFormer (AFF) improves significantly over baseline models of similar sizes.
FineRecon: Depth-aware Feed-forward Network for Detailed 3D Reconstruction
Apr 04, 2023



Recent works on 3D reconstruction from posed images have demonstrated that direct inference of scene-level 3D geometry without iterative optimization is feasible using a deep neural network, showing remarkable promise and high efficiency. However, the reconstructed geometries, typically represented as a 3D truncated signed distance function (TSDF), are often coarse without fine geometric details. To address this problem, we propose three effective solutions for improving the fidelity of inference-based 3D reconstructions. We first present a resolution-agnostic TSDF supervision strategy to provide the network with a more accurate learning signal during training, avoiding the pitfalls of TSDF interpolation seen in previous work. We then introduce a depth guidance strategy using multi-view depth estimates to enhance the scene representation and recover more accurate surfaces. Finally, we develop a novel architecture for the final layers of the network, conditioning the output TSDF prediction on high-resolution image features in addition to coarse voxel features, enabling sharper reconstruction of fine details. Our method produces smooth and highly accurate reconstructions, showing significant improvements across multiple depth and 3D reconstruction metrics.
LivePose: Online 3D Reconstruction from Monocular Video with Dynamic Camera Poses
Mar 31, 2023



Dense 3D reconstruction from RGB images traditionally assumes static camera pose estimates. This assumption has endured, even as recent works have increasingly focused on real-time methods for mobile devices. However, the assumption of one pose per image does not hold for online execution: poses from real-time SLAM are dynamic and may be updated following events such as bundle adjustment and loop closure. This has been addressed in the RGB-D setting, by de-integrating past views and re-integrating them with updated poses, but it remains largely untreated in the RGB-only setting. We formalize this problem to define the new task of online reconstruction from dynamically-posed images. To support further research, we introduce a dataset called LivePose containing the dynamic poses from a SLAM system running on ScanNet. We select three recent reconstruction systems and apply a framework based on de-integration to adapt each one to the dynamic-pose setting. In addition, we propose a novel, non-linear de-integration module that learns to remove stale scene content. We show that responding to pose updates is critical for high-quality reconstruction, and that our de-integration framework is an effective solution.
Generative Multiplane Images: Making a 2D GAN 3D-Aware
Jul 21, 2022
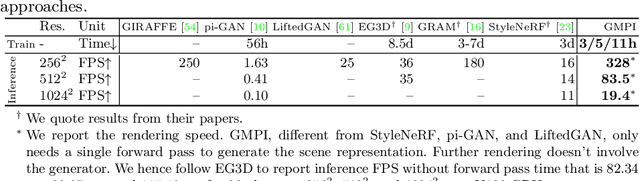
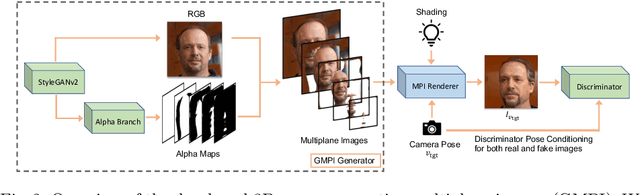
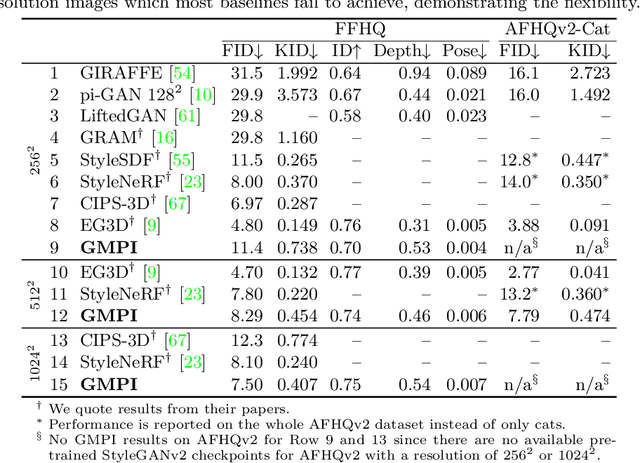
What is really needed to make an existing 2D GAN 3D-aware? To answer this question, we modify a classical GAN, i.e., StyleGANv2, as little as possible. We find that only two modifications are absolutely necessary: 1) a multiplane image style generator branch which produces a set of alpha maps conditioned on their depth; 2) a pose-conditioned discriminator. We refer to the generated output as a 'generative multiplane image' (GMPI) and emphasize that its renderings are not only high-quality but also guaranteed to be view-consistent, which makes GMPIs different from many prior works. Importantly, the number of alpha maps can be dynamically adjusted and can differ between training and inference, alleviating memory concerns and enabling fast training of GMPIs in less than half a day at a resolution of $1024^2$. Our findings are consistent across three challenging and common high-resolution datasets, including FFHQ, AFHQv2, and MetFaces.
Fast and Explicit Neural View Synthesis
Jul 12, 2021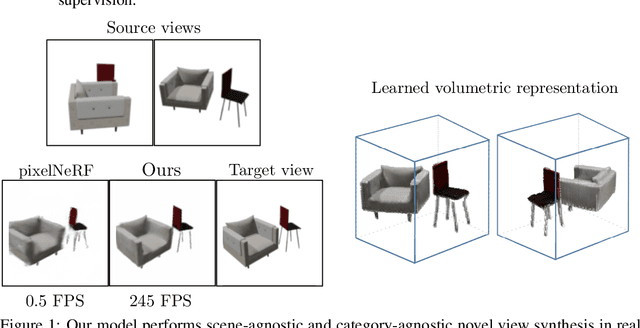
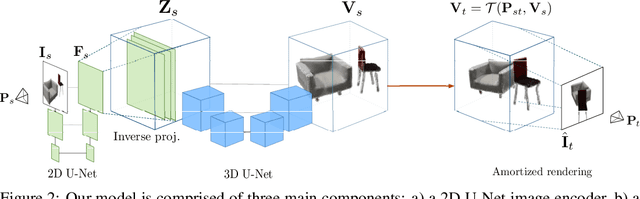
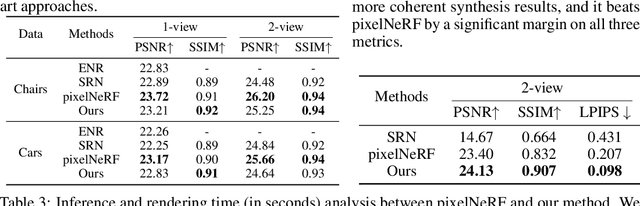

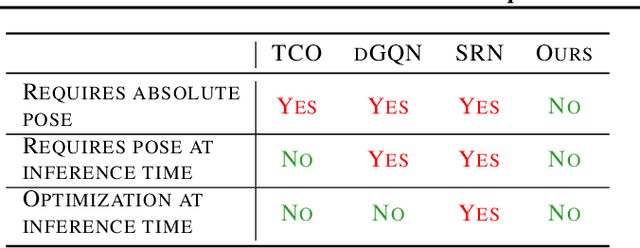
We study the problem of novel view synthesis of a scene comprised of 3D objects. We propose a simple yet effective approach that is neither continuous nor implicit, challenging recent trends on view synthesis. We demonstrate that although continuous radiance field representations have gained a lot of attention due to their expressive power, our simple approach obtains comparable or even better novel view reconstruction quality comparing with state-of-the-art baselines while increasing rendering speed by over 400x. Our model is trained in a category-agnostic manner and does not require scene-specific optimization. Therefore, it is able to generalize novel view synthesis to object categories not seen during training. In addition, we show that with our simple formulation, we can use view synthesis as a self-supervision signal for efficient learning of 3D geometry without explicit 3D supervision.
Deep Neural Network Approach for Annual Luminance Simulations
Sep 14, 2020Annual luminance maps provide meaningful evaluations for occupants' visual comfort, preferences, and perception. However, acquiring long-term luminance maps require labor-intensive and time-consuming simulations or impracticable long-term field measurements. This paper presents a novel data-driven machine learning approach that makes annual luminance-based evaluations more efficient and accessible. The methodology is based on predicting the annual luminance maps from a limited number of point-in-time high dynamic range imagery by utilizing a deep neural network (DNN). Panoramic views are utilized, as they can be post-processed to study multiple view directions. The proposed DNN model can faithfully predict high-quality annual panoramic luminance maps from one of the three options within 30 minutes training time: a) point-in-time luminance imagery spanning 5% of the year, when evenly distributed during daylight hours, b) one-month hourly imagery generated or collected continuously during daylight hours around the equinoxes (8% of the year); or c) 9 days of hourly data collected around the spring equinox, summer and winter solstices (2.5% of the year) all suffice to predict the luminance maps for the rest of the year. The DNN predicted high-quality panoramas are validated against Radiance (RPICT) renderings using a series of quantitative and qualitative metrics. The most efficient predictions are achieved with 9 days of hourly data collected around the spring equinox, summer and winter solstices. The results clearly show that practitioners and researchers can efficiently incorporate long-term luminance-based metrics over multiple view directions into the design and research processes using the proposed DNN workflow.
Equivariant Neural Rendering
Jun 13, 2020
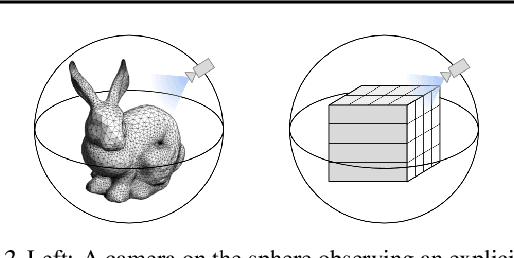

We propose a framework for learning neural scene representations directly from images, without 3D supervision. Our key insight is that 3D structure can be imposed by ensuring that the learned representation transforms like a real 3D scene. Specifically, we introduce a loss which enforces equivariance of the scene representation with respect to 3D transformations. Our formulation allows us to infer and render scenes in real time while achieving comparable results to models requiring minutes for inference. In addition, we introduce two challenging new datasets for scene representation and neural rendering, including scenes with complex lighting and backgrounds. Through experiments, we show that our model achieves compelling results on these datasets as well as on standard ShapeNet benchmarks.