 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multimodal Understanding via Stable Diffusion as a Task-Aware Feature Extractor
Jul 09, 2025Recent advances in multimodal large language models (MLLMs) have enabled image-based question-answering capabilities. However, a key limitation is the use of CLIP as the visual encoder; while it can capture coarse global information, it often can miss fine-grained details that are relevant to the input query. To address these shortcomings, this work studies whether pre-trained text-to-image diffusion models can serve as instruction-aware visual encoders. Through an analysis of their internal representations, we find diffusion features are both rich in semantics and can encode strong image-text alignment. Moreover, we find that we can leverage text conditioning to focus the model on regions relevant to the input question. We then investigate how to align these features with large language models and uncover a leakage phenomenon, where the LLM can inadvertently recover information from the original diffusion prompt. We analyze the causes of this leakage and propose a mitigation strategy. Based on these insights, we explore a simple fusion strategy that utilizes both CLIP and conditional diffusion features. We evaluate our approach on both general VQA and specialized MLLM benchmarks, demonstrating the promise of diffusion models for visual understanding, particularly in vision-centric tasks that require spatial and compositional reasoning. Our project page can be found https://vatsalag99.github.io/mustafar/.
Revealing the Utilized Rank of Subspaces of Learning in Neural Networks
Jul 05, 2024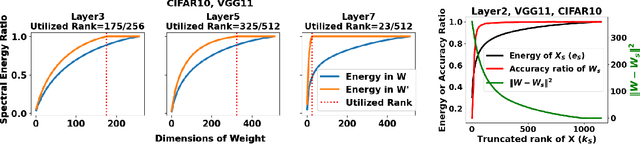
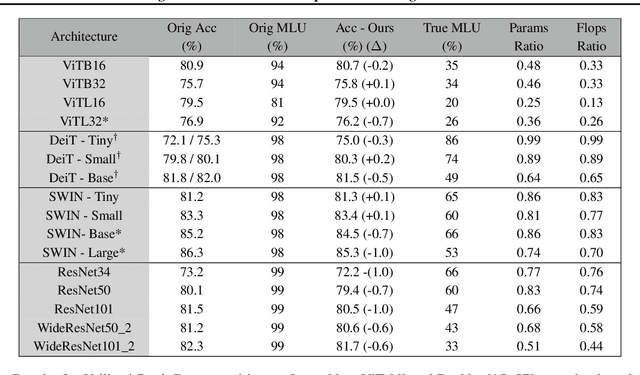
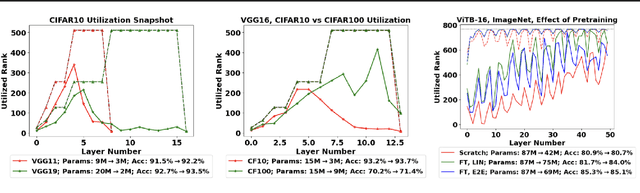
In this work, we study how well the learned weights of a neural network utilize the space available to them. This notion is related to capacity, but additionally incorporates the interaction of the network architecture with the dataset. Most learned weights appear to be full rank, and are therefore not amenable to low rank decomposition. This deceptively implies that the weights are utilizing the entire space available to them. We propose a simple data-driven transformation that projects the weights onto the subspace where the data and the weight interact. This preserves the functional mapping of the layer and reveals its low rank structure. In our findings, we conclude that most models utilize a fraction of the available space. For instance, for ViTB-16 and ViTL-16 trained on ImageNet, the mean layer utilization is 35% and 20% respectively. Our transformation results in reducing the parameters to 50% and 25% respectively, while resulting in less than 0.2% accuracy drop after fine-tuning. We also show that self-supervised pre-training drives this utilization up to 70%, justifying its suitability for downstream tasks.
GAUDI: A Neural Architect for Immersive 3D Scene Generation
Jul 27, 2022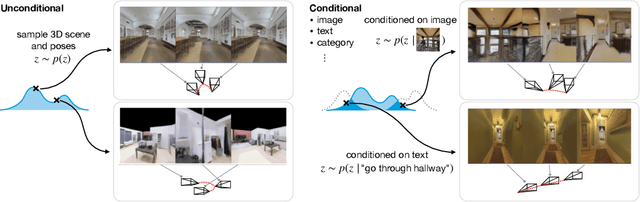
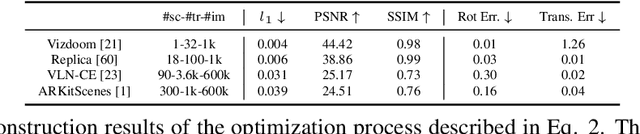

We introduce GAUDI, a generative model capable of capturing the distribution of complex and realistic 3D scenes that can be rendered immersively from a moving camera. We tackle this challenging problem with a scalable yet powerful approach, where we first optimize a latent representation that disentangles radiance fields and camera poses. This latent representation is then used to learn a generative model that enables both unconditional and conditional generation of 3D scenes. Our model generalizes previous works that focus on single objects by removing the assumption that the camera pose distribution can be shared across samples. We show that GAUDI obtains state-of-the-art performance in the unconditional generative setting across multiple datasets and allows for conditional generation of 3D scenes given conditioning variables like sparse image observations or text that describes the scene.
Fast and Explicit Neural View Synthesis
Jul 12, 2021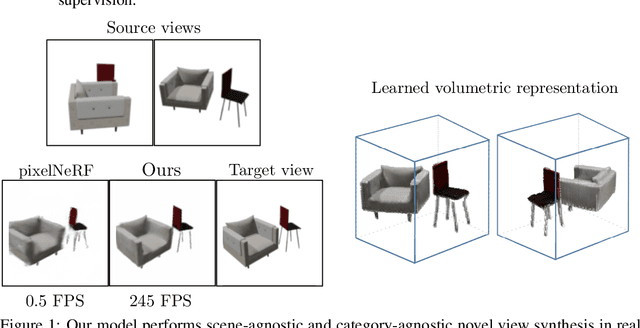
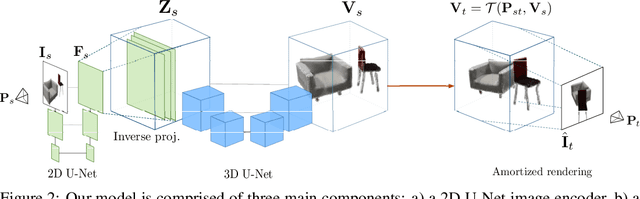
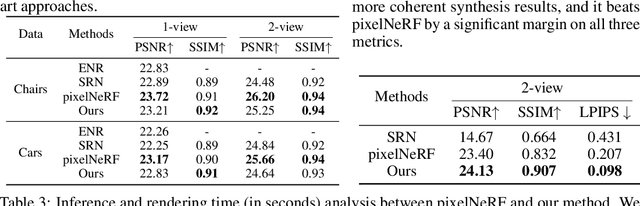

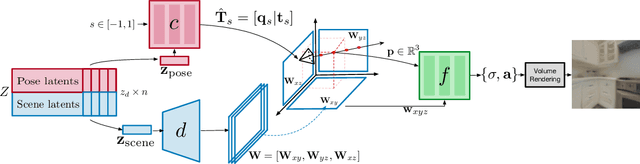
We study the problem of novel view synthesis of a scene comprised of 3D objects. We propose a simple yet effective approach that is neither continuous nor implicit, challenging recent trends on view synthesis. We demonstrate that although continuous radiance field representations have gained a lot of attention due to their expressive power, our simple approach obtains comparable or even better novel view reconstruction quality comparing with state-of-the-art baselines while increasing rendering speed by over 400x. Our model is trained in a category-agnostic manner and does not require scene-specific optimization. Therefore, it is able to generalize novel view synthesis to object categories not seen during training. In addition, we show that with our simple formulation, we can use view synthesis as a self-supervision signal for efficient learning of 3D geometry without explicit 3D supervision.
Learning to Branch for Multi-Task Learning
Jun 09, 2020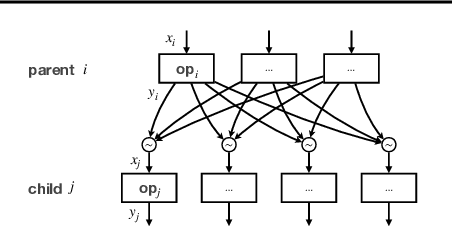
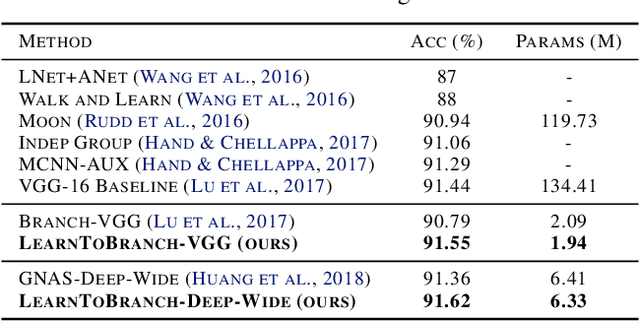

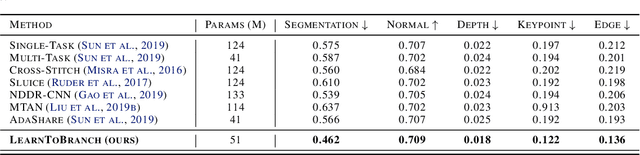
Training multiple tasks jointly in one deep network yields reduced latency during inference and better performance over the single-task counterpart by sharing certain layers of a network. However, over-sharing a network could erroneously enforce over-generalization, causing negative knowledge transfer across tasks. Prior works rely on human intuition or pre-computed task relatedness scores for ad hoc branching structures. They provide sub-optimal end results and often require huge efforts for the trial-and-error process. In this work, we present an automated multi-task learning algorithm that learns where to share or branch within a network, designing an effective network topology that is directly optimized for multiple objectives across tasks. Specifically, we propose a novel tree-structured design space that casts a tree branching operation as a gumbel-softmax sampling procedure. This enables differentiable network splitting that is end-to-end trainable. We validate the proposed method on controlled synthetic data, CelebA, and Taskonomy.
Sliced Wasserstein Discrepancy for Unsupervised Domain Adaptation
Mar 10, 2019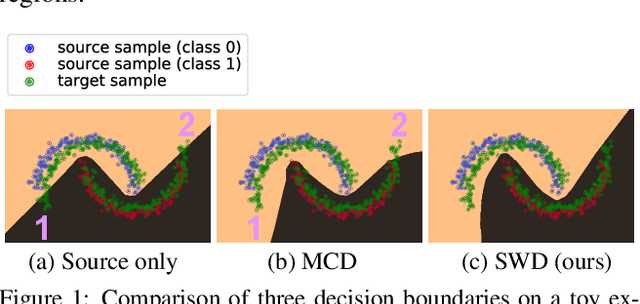
In this work, we connect two distinct concepts for unsupervised domain adaptation: feature distribution alignment between domains by utilizing the task-specific decision boundary and the Wasserstein metric. Our proposed sliced Wasserstein discrepancy (SWD) is designed to capture the natural notion of dissimilarity between the outputs of task-specific classifiers. It provides a geometrically meaningful guidance to detect target samples that are far from the support of the source and enables efficient distribution alignment in an end-to-end trainable fashion. In the experiments, we validate the effectiveness and genericness of our method on digit and sign recognition, image classification, semantic segmentation, and object detection.