 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing the Utilized Rank of Subspaces of Learning in Neural Networks
Jul 05, 2024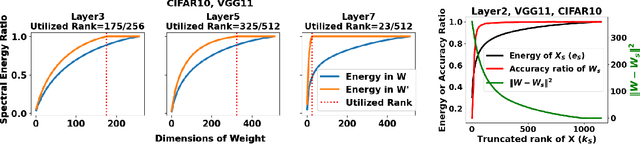
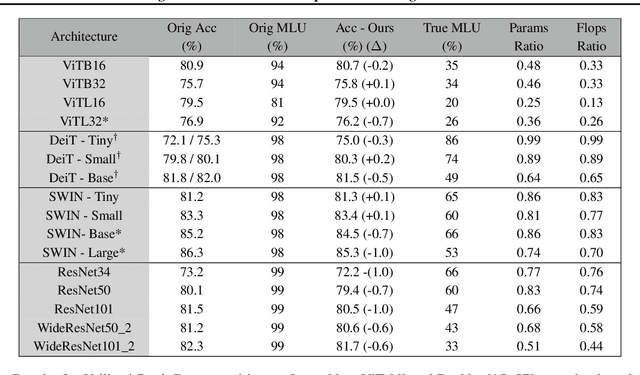
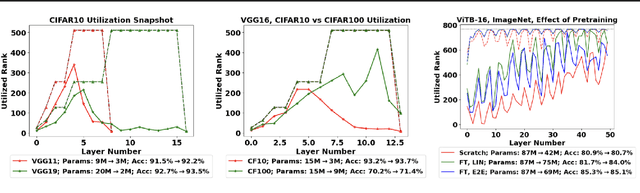
In this work, we study how well the learned weights of a neural network utilize the space available to them. This notion is related to capacity, but additionally incorporates the interaction of the network architecture with the dataset. Most learned weights appear to be full rank, and are therefore not amenable to low rank decomposition. This deceptively implies that the weights are utilizing the entire space available to them. We propose a simple data-driven transformation that projects the weights onto the subspace where the data and the weight interact. This preserves the functional mapping of the layer and reveals its low rank structure. In our findings, we conclude that most models utilize a fraction of the available space. For instance, for ViTB-16 and ViTL-16 trained on ImageNet, the mean layer utilization is 35% and 20% respectively. Our transformation results in reducing the parameters to 50% and 25% respectively, while resulting in less than 0.2% accuracy drop after fine-tuning. We also show that self-supervised pre-training drives this utilization up to 70%, justifying its suitability for downstream tasks.
Pruning for Improved ADC Efficiency in Crossbar-based Analog In-memory Accelerators
Mar 19, 2024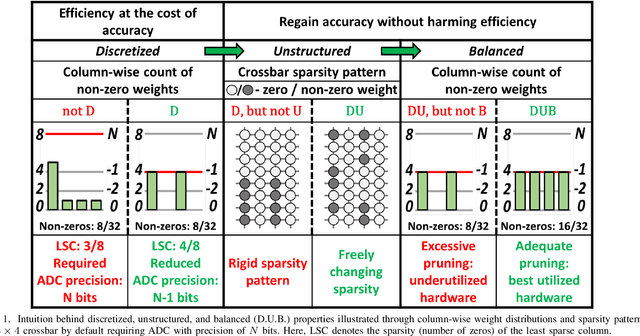
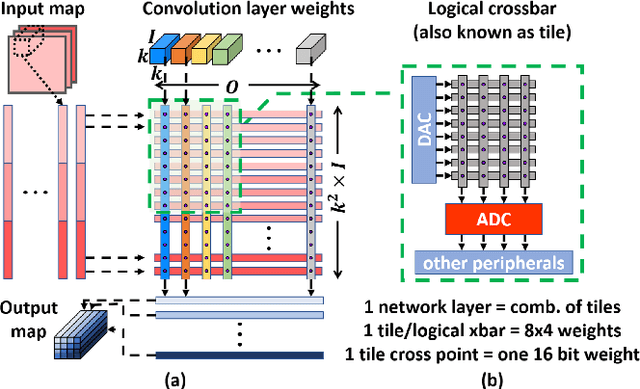
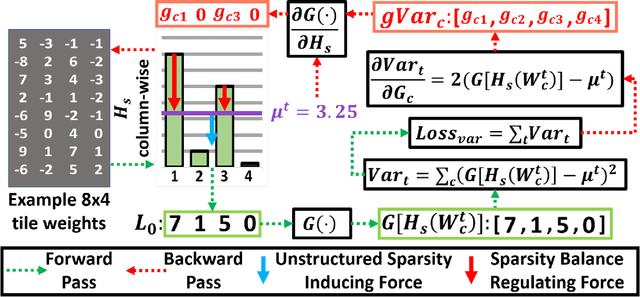
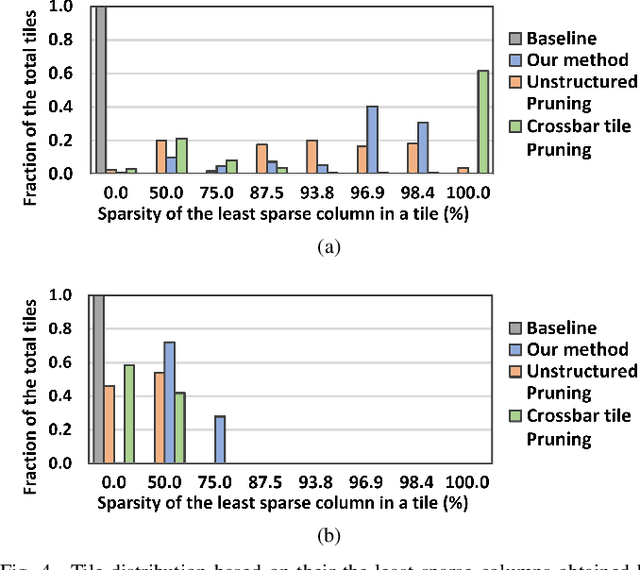
Deep learning has proved successful in many applications but suffers from high computational demands and requires custom accelerators for deployment. Crossbar-based analog in-memory architectures are attractive for acceleration of deep neural networks (DNN), due to their high data reuse and high efficiency enabled by combining storage and computation in memory. However, they require analog-to-digital converters (ADCs) to communicate crossbar outputs. ADCs consume a significant portion of energy and area of every crossbar processing unit, thus diminishing the potential efficiency benefits. Pruning is a well-studied technique to improve the efficiency of DNNs but requires modifications to be effective for crossbars. In this paper, we motivate crossbar-attuned pruning to target ADC-specific inefficiencies. This is achieved by identifying three key properties (dubbed D.U.B.) that induce sparsity that can be utilized to reduce ADC energy without sacrificing accuracy. The first property ensures that sparsity translates effectively to hardware efficiency by restricting sparsity levels to Discrete powers of 2. The other 2 properties encourage columns in the same crossbar to achieve both Unstructured and Balanced sparsity in order to amortize the accuracy drop. The desired D.U.B. sparsity is then achieved by regularizing the variance of $L_{0}$ norms of neighboring columns within the same crossbar. Our proposed implementation allows it to be directly used in end-to-end gradient-based training. We apply the proposed algorithm to convolutional layers of VGG11 and ResNet18 models, trained on CIFAR-10 and ImageNet datasets, and achieve up to 7.13x and 1.27x improvement, respectively, in ADC energy with less than 1% drop in accuracy.
Memorization Through the Lens of Curvature of Loss Function Around Samples
Jul 11, 2023



Neural networks are overparametrized and easily overfit the datasets they train on. In the extreme case, it is shown that they can memorize a training set with fully randomized labels. We propose using the curvature of loss function around the training sample as a measure of its memorization, averaged over all training epochs. We use this to study the generalization versus memorization properties of different samples in popular image datasets. We visualize samples with the highest curvature of loss around them, and show that these visually correspond to long-tailed, mislabeled or conflicting samples. This analysis helps us find a, to the best of our knowledge, novel failure model on the CIFAR100 dataset, that of duplicated images with different labels. We also synthetically mislabel a proportion of the dataset by randomly corrupting the labels of a few samples, and show that sorting by curvature yields high AUROC values for identifying the mislabeled samples.
TOFU: Towards Obfuscated Federated Updates by Encoding Weight Updates into Gradients from Proxy Data
Jan 21, 2022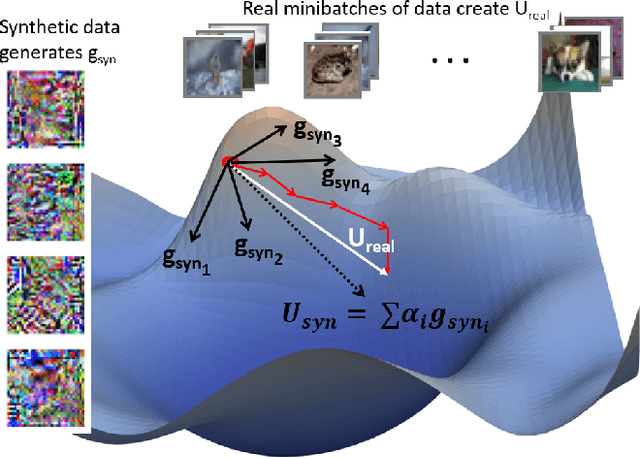
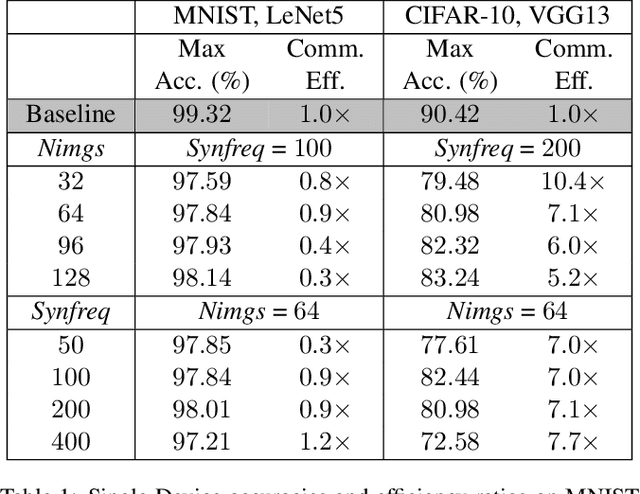

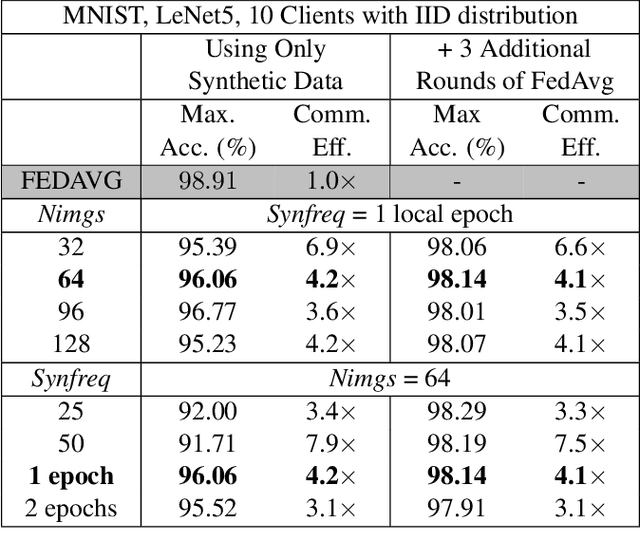
Advances in Federated Learning and an abundance of user data have enabled rich collaborative learning between multiple clients, without sharing user data. This is done via a central server that aggregates learning in the form of weight updates. However, this comes at the cost of repeated expensive communication between the clients and the server, and concerns about compromised user privacy. The inversion of gradients into the data that generated them is termed data leakage. Encryption techniques can be used to counter this leakage, but at added expense. To address these challenges of communication efficiency and privacy, we propose TOFU, a novel algorithm which generates proxy data that encodes the weight updates for each client in its gradients. Instead of weight updates, this proxy data is now shared. Since input data is far lower in dimensional complexity than weights, this encoding allows us to send much lesser data per communication round. Additionally, the proxy data resembles noise, and even perfect reconstruction from data leakage attacks would invert the decoded gradients into unrecognizable noise, enhancing privacy. We show that TOFU enables learning with less than 1% and 7% accuracy drops on MNIST and on CIFAR-10 datasets, respectively. This drop can be recovered via a few rounds of expensive encrypted gradient exchange. This enables us to learn to near-full accuracy in a federated setup, while being 4x and 6.6x more communication efficient than the standard Federated Averaging algorithm on MNIST and CIFAR-10, respectively.
Encoding Hierarchical Information in Neural Networks helps in Subpopulation Shift
Dec 20, 2021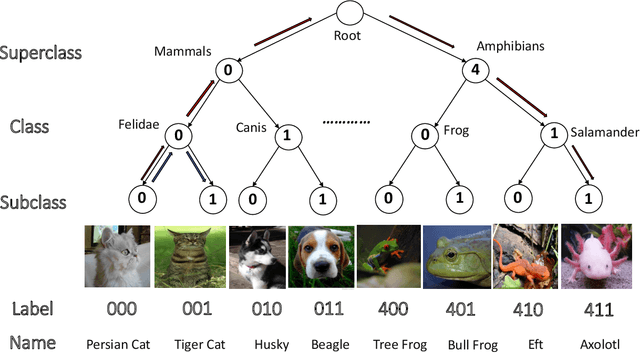
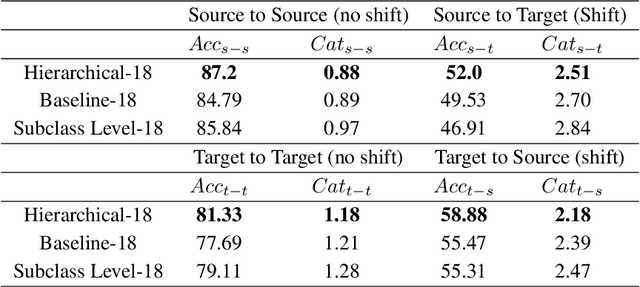
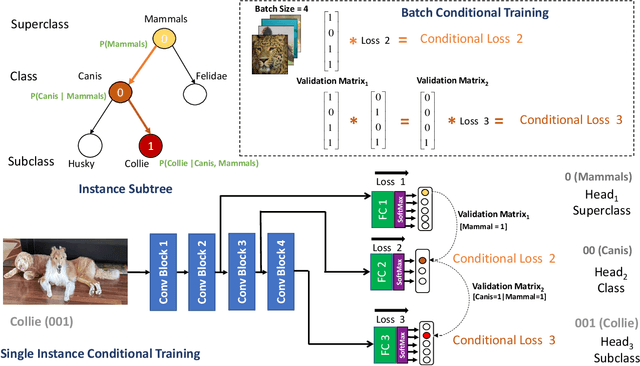
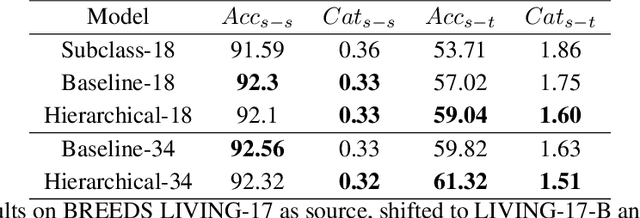
Over the past decade, deep neural networks have proven to be adept in image classification tasks, often surpassing humans in terms of accuracy. However, standard neural networks often fail to understand the concept of hierarchical structures and dependencies among different classes for vision related tasks. Humans on the other hand, seem to learn categories conceptually, progressively growing from understanding high-level concepts down to granular levels of categories. One of the issues arising from the inability of neural networks to encode such dependencies within its learned structure is that of subpopulation shift -- where models are queried with novel unseen classes taken from a shifted population of the training set categories. Since the neural network treats each class as independent from all others, it struggles to categorize shifting populations that are dependent at higher levels of the hierarchy. In this work, we study the aforementioned problems through the lens of a novel conditional supervised training framework. We tackle subpopulation shift by a structured learning procedure that incorporates hierarchical information conditionally through labels. Furthermore, we introduce a notion of graphical distance to model the catastrophic effect of mispredictions. We show that learning in this structured hierarchical manner results in networks that are more robust against subpopulation shifts, with an improvement of around ~2% in terms of accuracy and around 8.5\% in terms of graphical distance over standard models on subpopulation shift benchmarks.
Spatio-Temporal Pruning and Quantization for Low-latency Spiking Neural Networks
Apr 29, 2021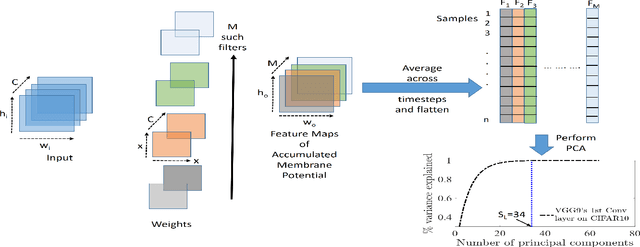
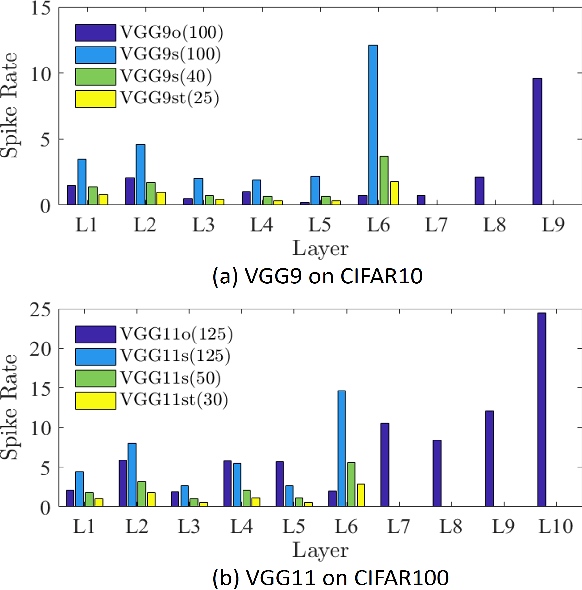
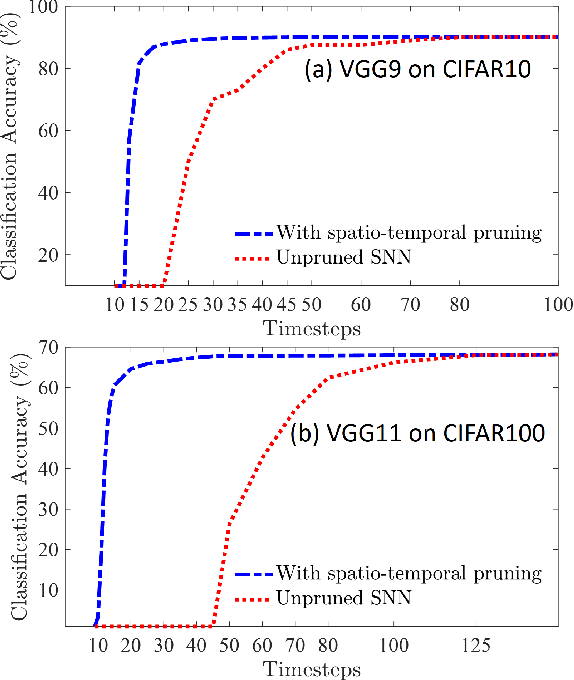
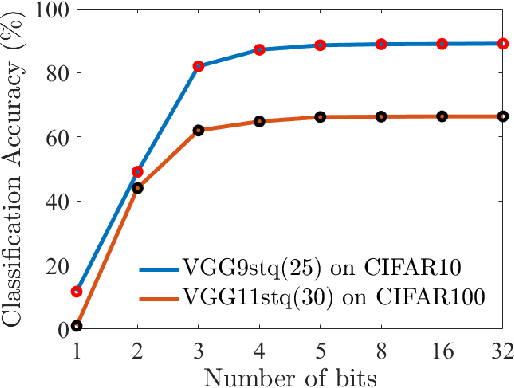
Spiking Neural Networks (SNNs) are a promising alternative to traditional deep learning methods since they perform event-driven information processing. However, a major drawback of SNNs is high inference latency. The efficiency of SNNs could be enhanced using compression methods such as pruning and quantization. Notably, SNNs, unlike their non-spiking counterparts, consist of a temporal dimension, the compression of which can lead to latency reduction. In this paper, we propose spatial and temporal pruning of SNNs. First, structured spatial pruning is performed by determining the layer-wise significant dimensions using principal component analysis of the average accumulated membrane potential of the neurons. This step leads to 10-14X model compression. Additionally, it enables inference with lower latency and decreases the spike count per inference. To further reduce latency, temporal pruning is performed by gradually reducing the timesteps while training. The networks are trained using surrogate gradient descent based backpropagation and we validate the results on CIFAR10 and CIFAR100, using VGG architectures. The spatiotemporally pruned SNNs achieve 89.04% and 66.4% accuracy on CIFAR10 and CIFAR100, respectively, while performing inference with 3-30X reduced latency compared to state-of-the-art SNNs. Moreover, they require 8-14X lesser compute energy compared to their unpruned standard deep learning counterparts. The energy numbers are obtained by multiplying the number of operations with energy per operation. These SNNs also provide 1-4% higher robustness against Gaussian noise corrupted inputs. Furthermore, we perform weight quantization and find that performance remains reasonably stable up to 5-bit quantization.
Gradient Projection Memory for Continual Learning
Mar 17, 2021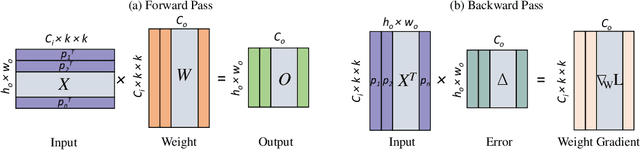
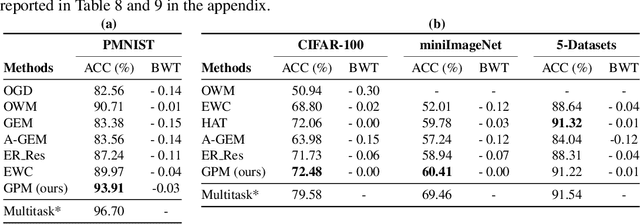
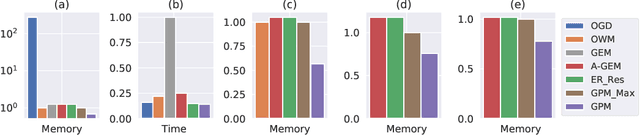
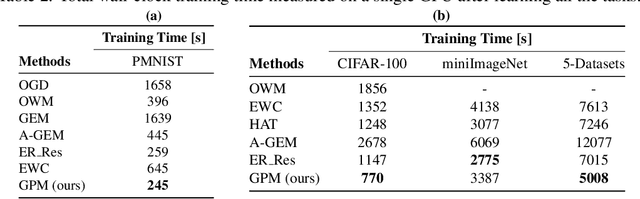
The ability to learn continually without forgetting the past tasks is a desired attribute for artificial learning systems. Existing approaches to enable such learning in artificial neural networks usually rely on network growth, importance based weight update or replay of old data from the memory. In contrast, we propose a novel approach where a neural network learns new tasks by taking gradient steps in the orthogonal direction to the gradient subspaces deemed important for the past tasks. We find the bases of these subspaces by analyzing network representations (activations) after learning each task with Singular Value Decomposition (SVD) in a single shot manner and store them in the memory as Gradient Projection Memory (GPM). With qualitative and quantitative analyses, we show that such orthogonal gradient descent induces minimum to no interference with the past tasks, thereby mitigates forgetting. We evaluate our algorithm on diverse image classification datasets with short and long sequences of tasks and report better or on-par performance compared to the state-of-the-art approaches.
* Accepted for Oral Presentation at ICLR 2021 https://openreview.net/forum?id=3AOj0RCNC2
Exploring Vicinal Risk Minimization for Lightweight Out-of-Distribution Detection
Dec 15, 2020
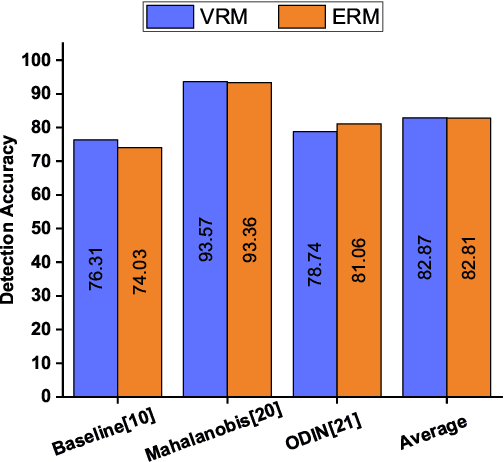
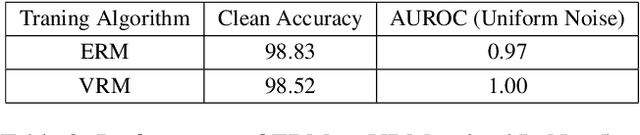
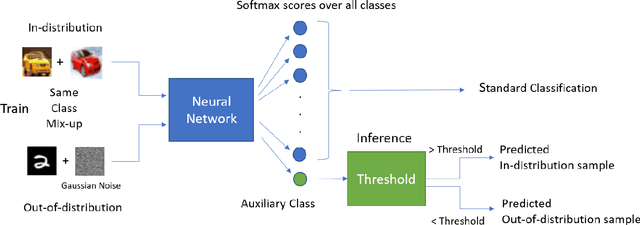
Deep neural networks have found widespread adoption in solving complex tasks ranging from image recognition to natural language processing. However, these networks make confident mispredictions when presented with data that does not belong to the training distribution, i.e. out-of-distribution (OoD) samples. In this paper we explore whether the property of Vicinal Risk Minimization (VRM) to smoothly interpolate between different class boundaries helps to train better OoD detectors. We apply VRM to existing OoD detection techniques and show their improved performance. We observe that existing OoD detectors have significant memory and compute overhead, hence we leverage VRM to develop an OoD detector with minimal overheard. Our detection method introduces an auxiliary class for classifying OoD samples. We utilize mixup in two ways to implement Vicinal Risk Minimization. First, we perform mixup within the same class and second, we perform mixup with Gaussian noise when training the auxiliary class. Our method achieves near competitive performance with significantly less compute and memory overhead when compared to existing OoD detection techniques. This facilitates the deployment of OoD detection on edge devices and expands our understanding of Vicinal Risk Minimization for use in training OoD detectors.
DCT-SNN: Using DCT to Distribute Spatial Information over Time for Learning Low-Latency Spiking Neural Networks
Oct 05, 2020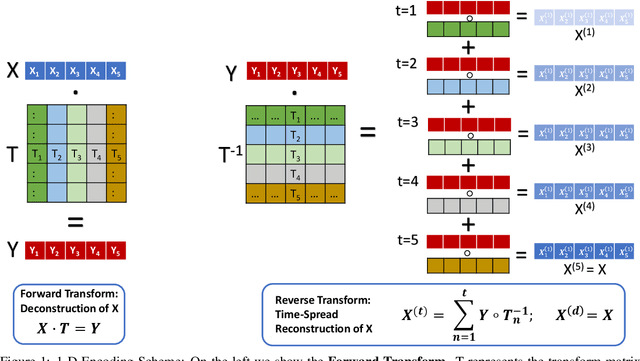
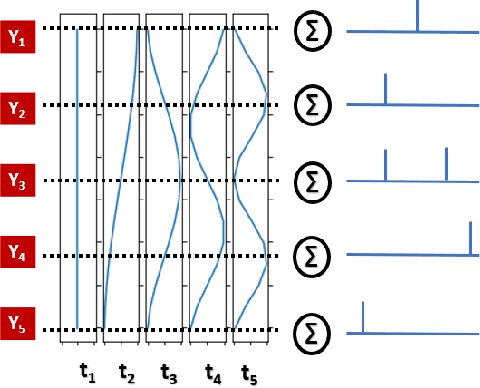
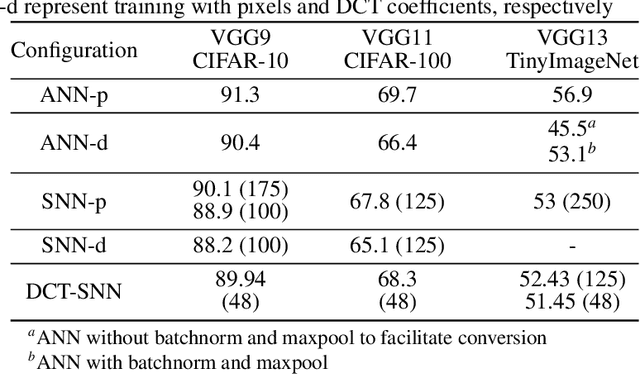

Spiking Neural Networks (SNNs) offer a promising alternative to traditional deep learning frameworks, since they provide higher computational efficiency due to event-driven information processing. SNNs distribute the analog values of pixel intensities into binary spikes over time. However, the most widely used input coding schemes, such as Poisson based rate-coding, do not leverage the additional temporal learning capability of SNNs effectively. Moreover, these SNNs suffer from high inference latency which is a major bottleneck to their deployment. To overcome this, we propose a scalable time-based encoding scheme that utilizes the Discrete Cosine Transform (DCT) to reduce the number of timesteps required for inference. DCT decomposes an image into a weighted sum of sinusoidal basis images. At each time step, the Hadamard product of the DCT coefficients and a single frequency base, taken in order, is given to an accumulator that generates spikes upon crossing a threshold. We use the proposed scheme to learn DCT-SNN, a low-latency deep SNN with leaky-integrate-and-fire neurons, trained using surrogate gradient descent based backpropagation. We achieve top-1 accuracy of 89.94%, 68.3% and 52.43% on CIFAR-10, CIFAR-100 and TinyImageNet, respectively using VGG architectures. Notably, DCT-SNN performs inference with 2-14X reduced latency compared to other state-of-the-art SNNs, while achieving comparable accuracy to their standard deep learning counterparts. The dimension of the transform allows us to control the number of timesteps required for inference. Additionally, we can trade-off accuracy with latency in a principled manner by dropping the highest frequency components during inference.
TREND: Transferability based Robust ENsemble Design
Aug 04, 2020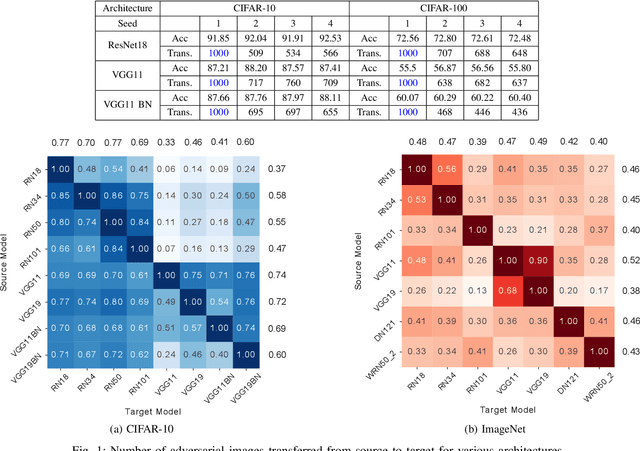
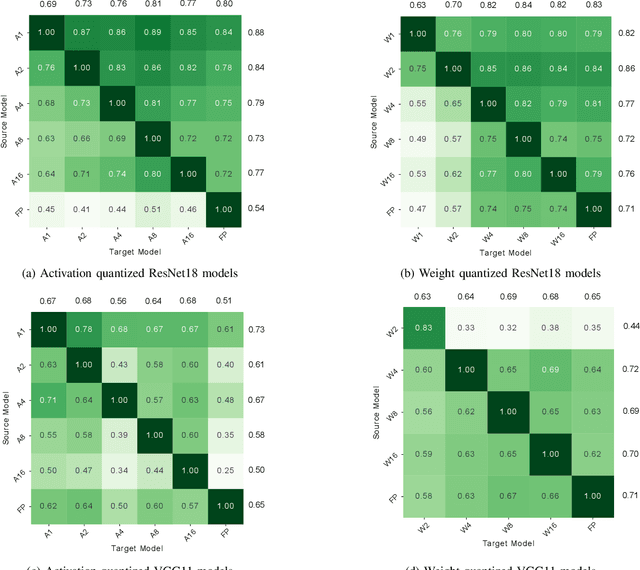

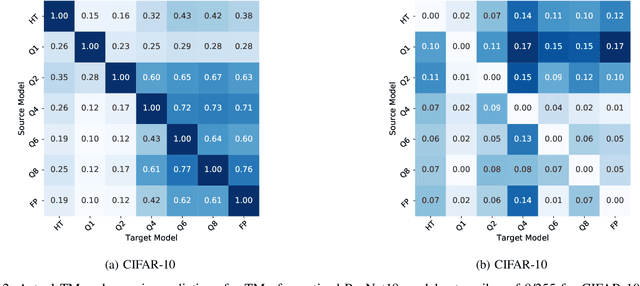
Deep Learning models hold state-of-the-art performance in many fields, but their vulnerability to adversarial examples poses a threat to their ubiquitous deployment in practical settings. Additionally, adversarial inputs generated on one classifier have been shown to transfer to other classifiers trained on similar data, which makes the attacks possible even if the model parameters are not revealed to the adversary. This property of transferability has not yet been systematically studied, leading to a gap in our understanding of robustness of neural networks to adversarial inputs. In this work, we study the effect of network architecture, initialization, input, weight and activation quantization on transferability. Our experiments reveal that transferability is significantly hampered by input quantization and architectural mismatch between source and target, is unaffected by initialization and is architecture-dependent for both weight and activation quantization. To quantify transferability, we propose a simple metric, which is a function of the attack strength. We demonstrate the utility of the proposed metric in designing a methodology to build ensembles with improved adversarial robustness. Finally, we show that an ensemble consisting of carefully chosen input quantized networks achieves better adversarial robustness than would otherwise be possible with a single network.