 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning for Improved ADC Efficiency in Crossbar-based Analog In-memory Accelerators
Mar 19, 2024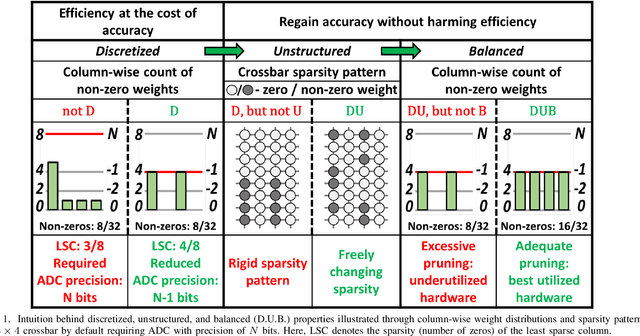
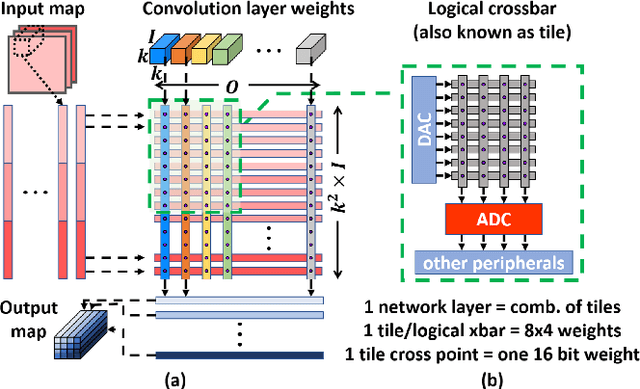
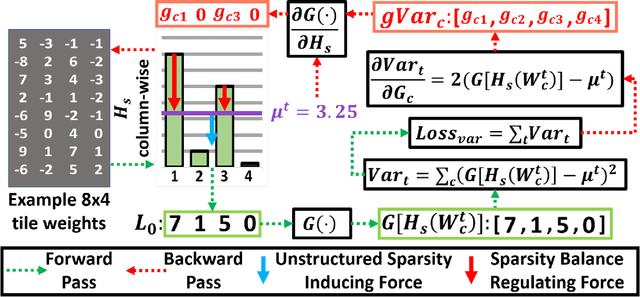
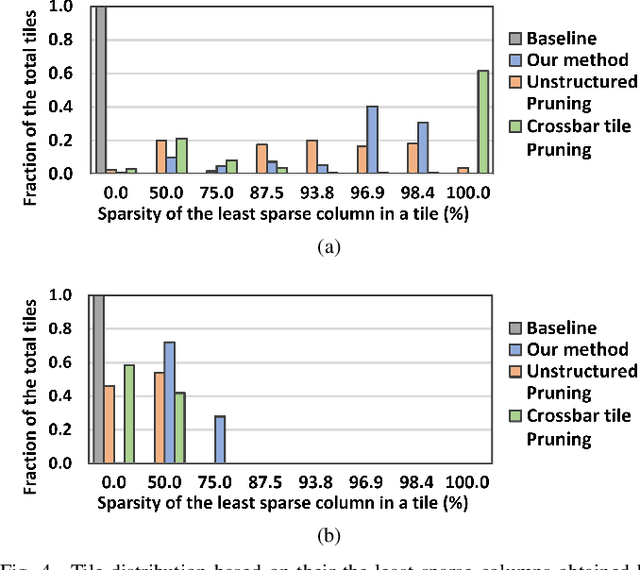
Deep learning has proved successful in many applications but suffers from high computational demands and requires custom accelerators for deployment. Crossbar-based analog in-memory architectures are attractive for acceleration of deep neural networks (DNN), due to their high data reuse and high efficiency enabled by combining storage and computation in memory. However, they require analog-to-digital converters (ADCs) to communicate crossbar outputs. ADCs consume a significant portion of energy and area of every crossbar processing unit, thus diminishing the potential efficiency benefits. Pruning is a well-studied technique to improve the efficiency of DNNs but requires modifications to be effective for crossbars. In this paper, we motivate crossbar-attuned pruning to target ADC-specific inefficiencies. This is achieved by identifying three key properties (dubbed D.U.B.) that induce sparsity that can be utilized to reduce ADC energy without sacrificing accuracy. The first property ensures that sparsity translates effectively to hardware efficiency by restricting sparsity levels to Discrete powers of 2. The other 2 properties encourage columns in the same crossbar to achieve both Unstructured and Balanced sparsity in order to amortize the accuracy drop. The desired D.U.B. sparsity is then achieved by regularizing the variance of $L_{0}$ norms of neighboring columns within the same crossbar. Our proposed implementation allows it to be directly used in end-to-end gradient-based training. We apply the proposed algorithm to convolutional layers of VGG11 and ResNet18 models, trained on CIFAR-10 and ImageNet datasets, and achieve up to 7.13x and 1.27x improvement, respectively, in ADC energy with less than 1% drop in accuracy.
WWW: What, When, Where to Compute-in-Memory
Dec 26, 2023



Compute-in-memory (CiM) has emerged as a compelling solution to alleviate high data movement costs in von Neumann machines. CiM can perform massively parallel general matrix multiplication (GEMM) operations in memory, the dominant computation in Machine Learning (ML) inference. However, re-purposing memory for compute poses key questions on 1) What type of CiM to use: Given a multitude of analog and digital CiMs, determining their suitability from systems perspective is needed. 2) When to use CiM: ML inference includes workloads with a variety of memory and compute requirements, making it difficult to identify when CiM is more beneficial than standard processing cores. 3) Where to integrate CiM: Each memory level has different bandwidth and capacity, that affects the data movement and locality benefits of CiM integration. In this paper, we explore answers to these questions regarding CiM integration for ML inference acceleration. We use Timeloop-Accelergy for early system-level evaluation of CiM prototypes, including both analog and digital primitives. We integrate CiM into different cache memory levels in an Nvidia A100-like baseline architecture and tailor the dataflow for various ML workloads. Our experiments show CiM architectures improve energy efficiency, achieving up to 0.12x lower energy than the established baseline with INT-8 precision, and upto 4x performance gains with weight interleaving and duplication. The proposed work provides insights into what type of CiM to use, and when and where to optimally integrate it in the cache hierarchy for GEMM acceleration.
On the Noise Stability and Robustness of Adversarially Trained Networks on NVM Crossbars
Sep 19, 2021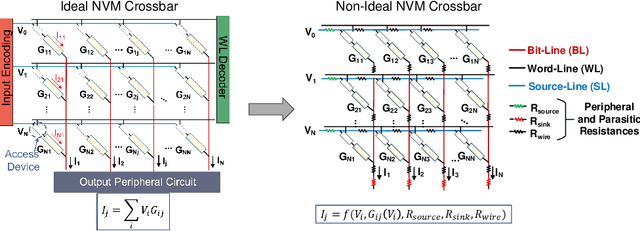
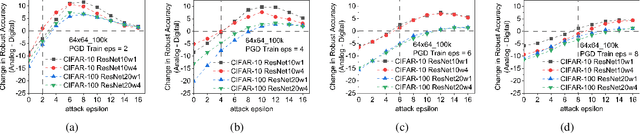
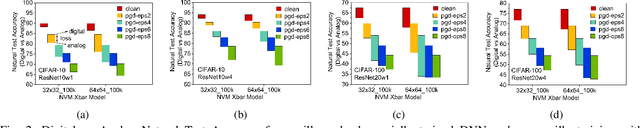
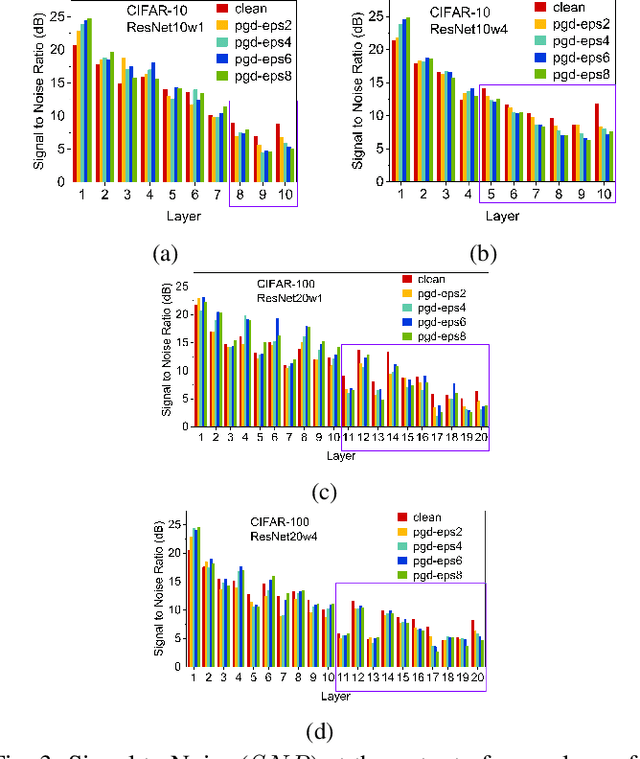
Applications based on Deep Neural Networks (DNNs) have grown exponentially in the past decade. To match their increasing computational needs, several Non-Volatile Memory (NVM) crossbar-based accelerators have been proposed. Apart from improved energy efficiency and performance, these approximate hardware also possess intrinsic robustness for defense against Adversarial Attacks, which is an important security concern for DNNs. Prior works have focused on quantifying this intrinsic robustness for vanilla networks, that is DNNs trained on unperturbed inputs. However, adversarial training of DNNs is the benchmark technique for robustness, and sole reliance on intrinsic robustness of the hardware may not be sufficient. In this work, we explore the design of robust DNNs through the amalgamation of adversarial training and the intrinsic robustness offered by NVM crossbar-based analog hardware. First, we study the noise stability of such networks on unperturbed inputs and observe that internal activations of adversarially trained networks have lower Signal-to-Noise Ratio (SNR), and are sensitive to noise than vanilla networks. As a result, they suffer significantly higher performance degradation due to the non-ideal computations; on an average 2x accuracy drop. On the other hand, for adversarial images generated using Projected-Gradient-Descent (PGD) White-Box attacks, ResNet-10/20 adversarially trained on CIFAR-10/100 display a 5-10% gain in robust accuracy due to the underlying NVM crossbar when the attack epsilon ($\epsilon_{attack}$, the degree of input perturbations) is greater than the epsilon of the adversarial training ($\epsilon_{train}$). Our results indicate that implementing adversarially trained networks on analog hardware requires careful calibration between hardware non-idealities and $\epsilon_{train}$ to achieve optimum robustness and performance.
Complexity-aware Adaptive Training and Inference for Edge-Cloud Distributed AI Systems
Sep 14, 2021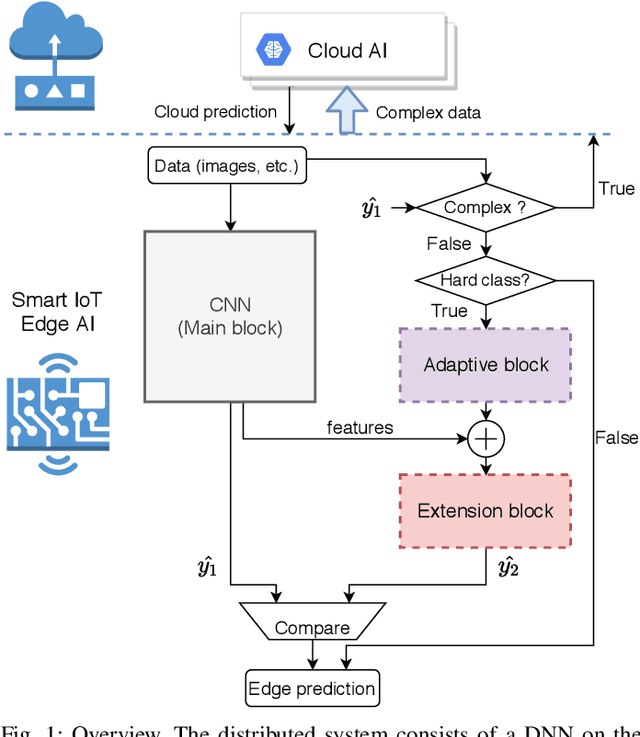
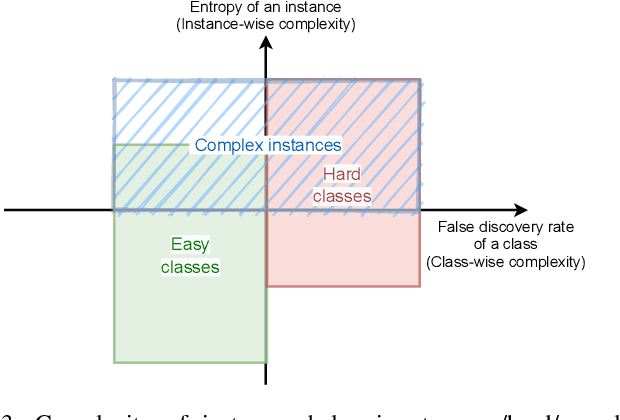
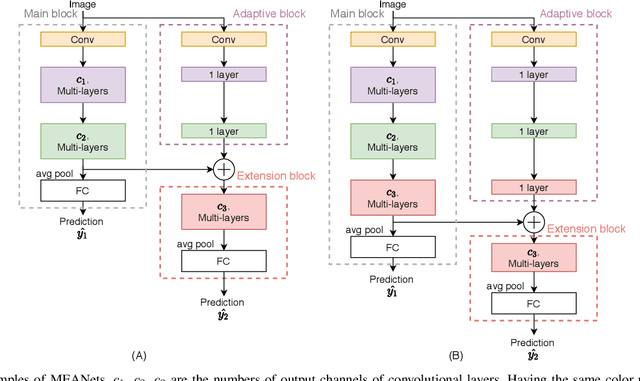
The ubiquitous use of IoT and machine learning applications is creating large amounts of data that require accurate and real-time processing. Although edge-based smart data processing can be enabled by deploying pretrained models, the energy and memory constraints of edge devices necessitate distributed deep learning between the edge and the cloud for complex data. In this paper, we propose a distributed AI system to exploit both the edge and the cloud for training and inference. We propose a new architecture, MEANet, with a main block, an extension block, and an adaptive block for the edge. The inference process can terminate at either the main block, the extension block, or the cloud. The MEANet is trained to categorize inputs into easy/hard/complex classes. The main block identifies instances of easy/hard classes and classifies easy classes with high confidence. Only data with high probabilities of belonging to hard classes would be sent to the extension block for prediction. Further, only if the neural network at the edge shows low confidence in the prediction, the instance is considered complex and sent to the cloud for further processing. The training technique lends to the majority of inference on edge devices while going to the cloud only for a small set of complex jobs, as determined by the edge. The performance of the proposed system is evaluated via extensive experiments using modified models of ResNets and MobileNetV2 on CIFAR-100 and ImageNet datasets. The results show that the proposed distributed model has improved accuracy and energy consumption, indicating its capacity to adapt.
NAX: Co-Designing Neural Network and Hardware Architecture for Memristive Xbar based Computing Systems
Jun 23, 2021
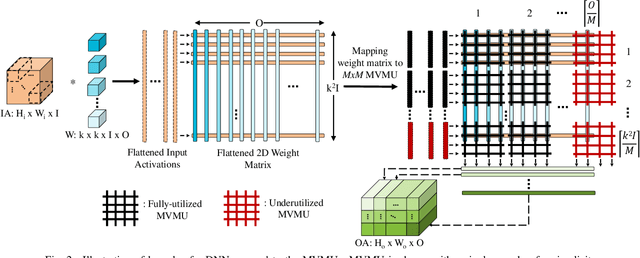
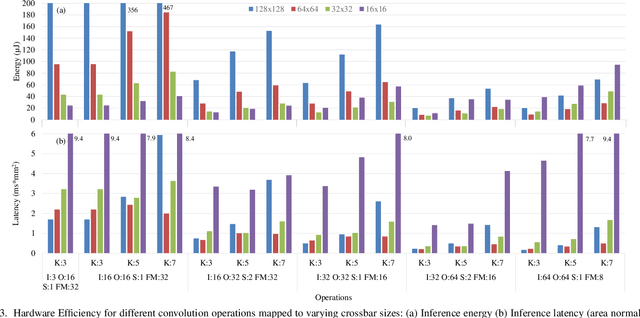

In-Memory Computing (IMC) hardware using Memristive Crossbar Arrays (MCAs) are gaining popularity to accelerate Deep Neural Networks (DNNs) since it alleviates the "memory wall" problem associated with von-Neumann architecture. The hardware efficiency (energy, latency and area) as well as application accuracy (considering device and circuit non-idealities) of DNNs mapped to such hardware are co-dependent on network parameters, such as kernel size, depth etc. and hardware architecture parameters such as crossbar size. However, co-optimization of both network and hardware parameters presents a challenging search space comprising of different kernel sizes mapped to varying crossbar sizes. To that effect, we propose NAX -- an efficient neural architecture search engine that co-designs neural network and IMC based hardware architecture. NAX explores the aforementioned search space to determine kernel and corresponding crossbar sizes for each DNN layer to achieve optimal tradeoffs between hardware efficiency and application accuracy. Our results from NAX show that the networks have heterogeneous crossbar sizes across different network layers, and achieves optimal hardware efficiency and accuracy considering the non-idealities in crossbars. On CIFAR-10 and Tiny ImageNet, our models achieve 0.8%, 0.2% higher accuracy, and 17%, 4% lower EDAP (energy-delay-area product) compared to a baseline ResNet-20 and ResNet-18 models, respectively.
Robustness Hidden in Plain Sight: Can Analog Computing Defend Against Adversarial Attacks?
Aug 27, 2020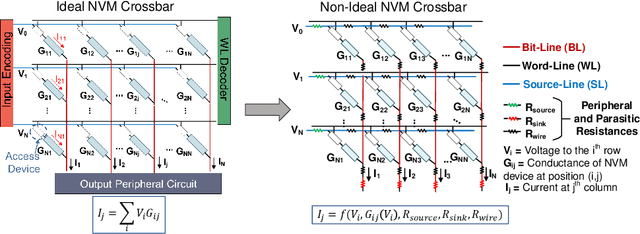
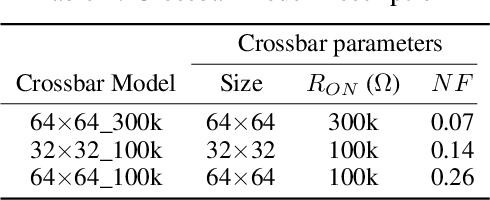
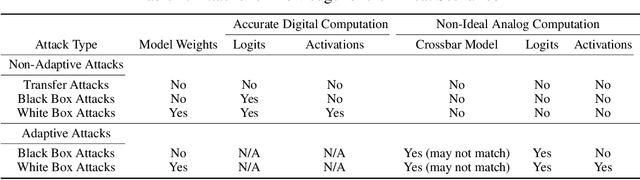
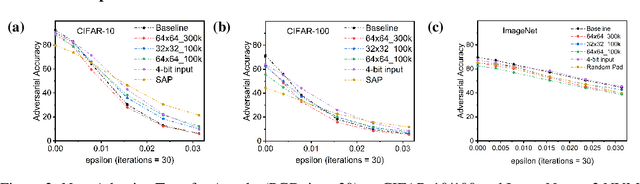
The ever-increasing computational demand of Deep Learning has propelled research in special-purpose inference accelerators based on emerging non-volatile memory (NVM) technologies. Such NVM crossbars promise fast and energy-efficient in-situ matrix vector multiplications (MVM) thus alleviating the long-standing von Neuman bottleneck in today's digital hardware. However the analog nature of computing in these NVM crossbars introduces approximations in the MVM operations. In this paper, we study the impact of these non-idealities on the performance of DNNs under adversarial attacks. The non-ideal behavior interferes with the computation of the exact gradient of the model, which is required for adversarial image generation. In a non-adaptive attack, where the attacker is unaware of the analog hardware, we show that analog computing offers a varying degree of intrinsic robustness, with a peak adversarial accuracy improvement of 35.34%, 22.69%, and 31.70% for white box PGD ($\epsilon$=1/255, iter=30) for CIFAR-10, CIFAR-100, and ImageNet(top-5) respectively. We also demonstrate "hardware-in-loop" adaptive attacks that circumvent this robustness by utilizing the knowledge of the NVM model. To the best of our knowledge, this is the first work that explores the non-idealities of analog computing for adversarial robustness at the time of submission to NeurIPS 2020.
Conditionally Deep Hybrid Neural Networks Across Edge and Cloud
May 21, 2020

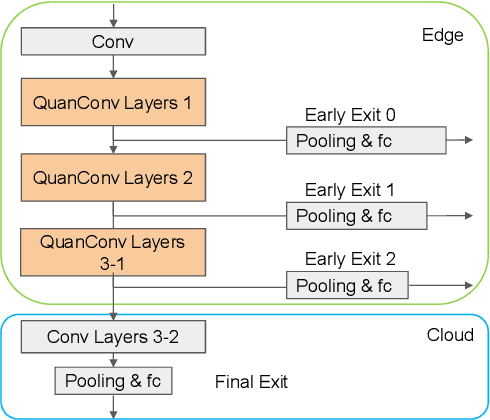

The pervasiveness of "Internet-of-Things" in our daily life has led to a recent surge in fog computing, encompassing a collaboration of cloud computing and edge intelligence. To that effect, deep learning has been a major driving force towards enabling such intelligent systems. However, growing model sizes in deep learning pose a significant challenge towards deployment in resource-constrained edge devices. Moreover, in a distributed intelligence environment, efficient workload distribution is necessary between edge and cloud systems. To address these challenges, we propose a conditionally deep hybrid neural network for enabling AI-based fog computing. The proposed network can be deployed in a distributed manner, consisting of quantized layers and early exits at the edge and full-precision layers on the cloud. During inference, if an early exit has high confidence in the classification results, it would allow samples to exit at the edge, and the deeper layers on the cloud are activated conditionally, which can lead to improved energy efficiency and inference latency. We perform an extensive design space exploration with the goal of minimizing energy consumption at the edge while achieving state-of-the-art classification accuracies on image classification tasks. We show that with binarized layers at the edge, the proposed conditional hybrid network can process 65% of inferences at the edge, leading to 5.5x computational energy reduction with minimal accuracy degradation on CIFAR-10 dataset. For the more complex dataset CIFAR-100, we observe that the proposed network with 4-bit quantization at the edge achieves 52% early classification at the edge with 4.8x energy reduction. The analysis gives us insights on designing efficient hybrid networks which achieve significantly higher energy efficiency than full-precision networks for edge-cloud based distributed intelligence systems.
IMAC: In-memory multi-bit Multiplication andACcumulation in 6T SRAM Array
Mar 27, 2020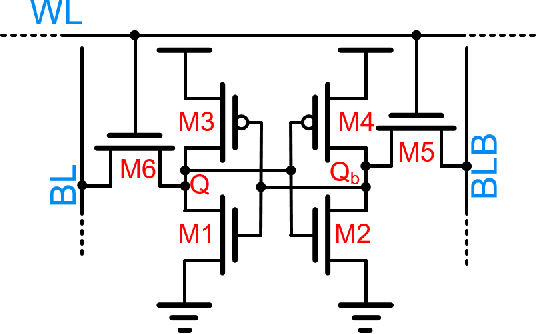
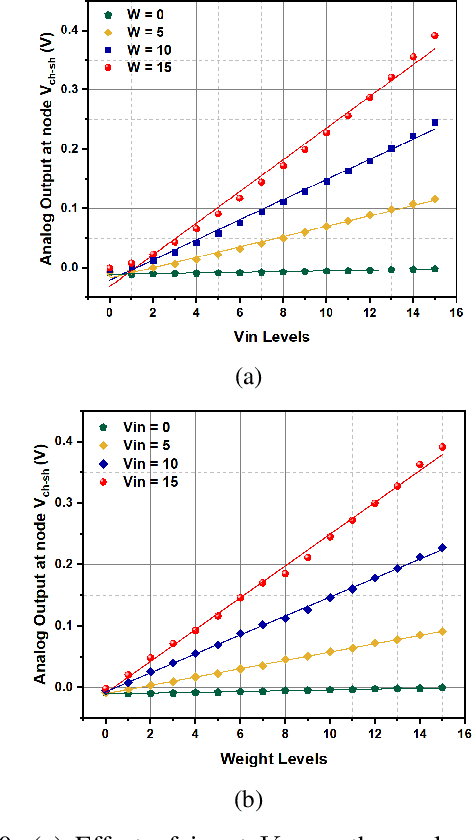

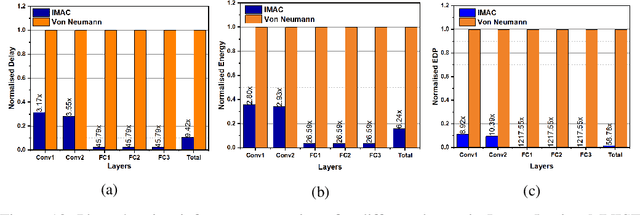
`In-memory computing' is being widely explored as a novel computing paradigm to mitigate the well known memory bottleneck. This emerging paradigm aims at embedding some aspects of computations inside the memory array, thereby avoiding frequent and expensive movement of data between the compute unit and the storage memory. In-memory computing with respect to Silicon memories has been widely explored on various memory bit-cells. Embedding computation inside the 6 transistor (6T) SRAM array is of special interest since it is the most widely used on-chip memory. In this paper, we present a novel in-memory multiplication followed by accumulation operation capable of performing parallel dot products within 6T SRAM without any changes to the standard bitcell. We, further, study the effect of circuit non-idealities and process variations on the accuracy of the LeNet-5 and VGG neural network architectures against the MNIST and CIFAR-10 datasets, respectively. The proposed in-memory dot-product mechanism achieves 88.8% and 99% accuracy for the CIFAR-10 and MNIST, respectively. Compared to the standard von Neumann system, the proposed system is 6.24x better in energy consumption and 9.42x better in delay.
PCA-driven Hybrid network design for enabling Intelligence at the Edge
Jun 04, 2019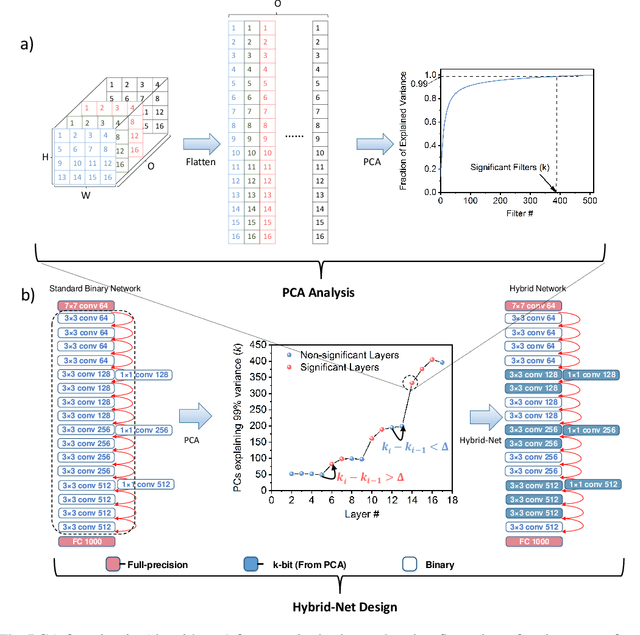

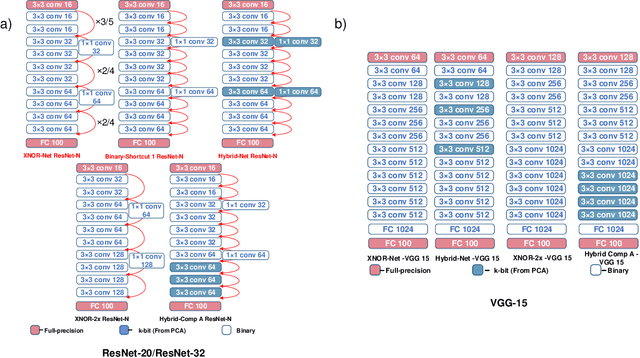
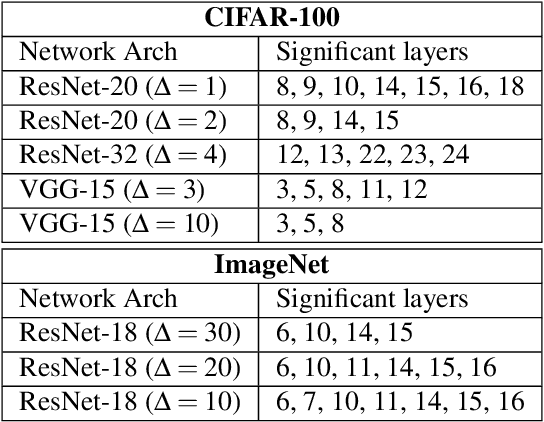
The recent advent of IOT has increased the demand for enabling AI-based edge computing in several applications including healthcare monitoring systems, autonomous vehicles etc. This has necessitated the search for efficient implementations of neural networks in terms of both computation and storage. Although extreme quantization has proven to be a powerful tool to achieve significant compression over full-precision networks, it can result in significant degradation in performance for complex image classification tasks. In this work, we propose a Principal Component Analysis (PCA) driven methodology to design mixed-precision, hybrid networks. Unlike standard practices of using PCA for dimensionality reduction, we leverage PCA to identify significant layers in a binary network which contribute relevant transformations on the input data by increasing the number of significant dimensions. Subsequently, we propose Hybrid-Net, a network with increased bit-precision of the weights and activations of the significant layers in a binary network. We show that the proposed Hybrid-Net achieves over 10% improvement in classification accuracy over binary networks such as XNOR-Net for ResNet and VGG architectures on CIFAR-100 and ImageNet datasets while still achieving upto 94% of the energy-efficiency of XNOR-Nets. The proposed design methodology allows us to move closer to the accuracy of standard full-precision networks by keeping more than half of the network binary. This work demonstrates an effective, one-shot methodology for designing hybrid, mixed-precision networks which significantly improve the classification performance of binary networks while attaining remarkable compression. The proposed hybrid networks further the feasibility of using highly compressed neural networks for energy-efficient neural computing in IOT-based edge devices.
Discretization based Solutions for Secure Machine Learning against Adversarial Attacks
Feb 11, 2019
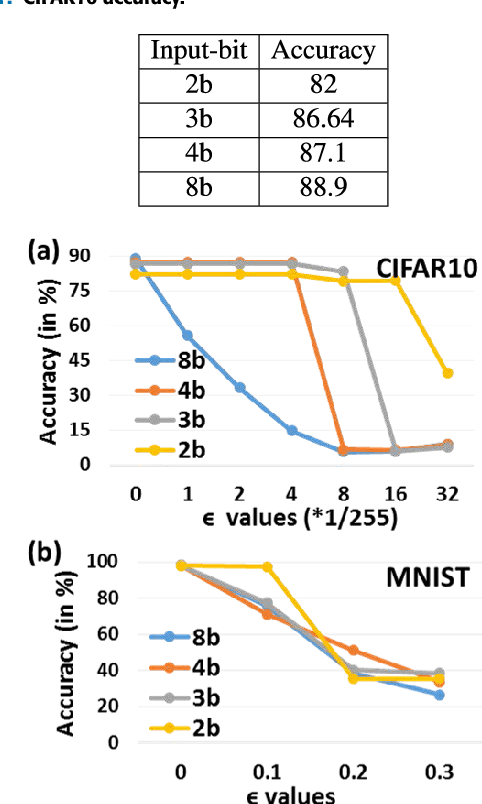
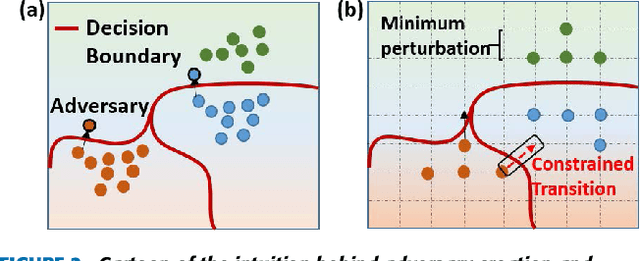
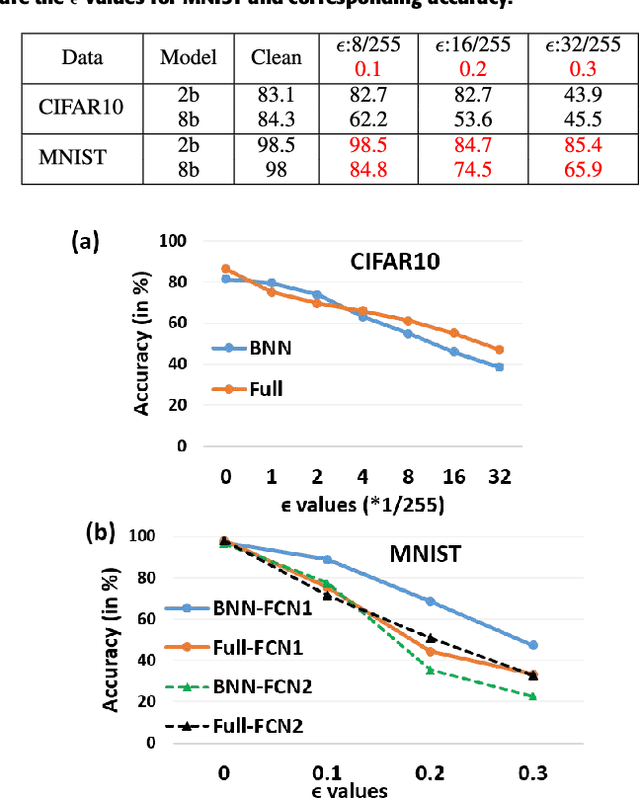
Adversarial examples are perturbed inputs that are designed (from a deep learning network's (DLN) parameter gradients) to mislead the DLN during test time. Intuitively, constraining the dimensionality of inputs or parameters of a network reduces the 'space' in which adversarial examples exist. Guided by this intuition, we demonstrate that discretization greatly improves the robustness of DLNs against adversarial attacks. Specifically, discretizing the input space (or allowed pixel levels from 256 values or 8-bit to 4 values or 2-bit) extensively improves the adversarial robustness of DLNs for a substantial range of perturbations for minimal loss in test accuracy. Furthermore, we find that Binary Neural Networks (BNNs) and related variants are intrinsically more robust than their full precision counterparts in adversarial scenarios. Combining input discretization with BNNs furthers the robustness even waiving the need for adversarial training for certain magnitude of perturbation values. We evaluate the effect of discretization on MNIST, CIFAR10, CIFAR100 and Imagenet datasets. Across all datasets, we observe maximal adversarial resistance with 2-bit input discretization that incurs an adversarial accuracy loss of just ~1-2% as compared to clean test accuracy.