 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiDR: A Reconfigurable Digital Compute-in-Memory Spiking Neural Network Accelerator for Event-based Perception
Nov 05, 2024



Spiking Neural Networks (SNNs), with their inherent recurrence, offer an efficient method for processing the asynchronous temporal data generated by Dynamic Vision Sensors (DVS), making them well-suited for event-based vision applications. However, existing SNN accelerators suffer from limitations in adaptability to diverse neuron models, bit precisions and network sizes, inefficient membrane potential (Vmem) handling, and limited sparse optimizations. In response to these challenges, we propose a scalable and reconfigurable digital compute-in-memory (CIM) SNN accelerator \chipname with a set of key features: 1) It uses in-memory computations and reconfigurable operating modes to minimize data movement associated with weight and Vmem data structures while efficiently adapting to different workloads. 2) It supports multiple weight/Vmem bit precision values, enabling a trade-off between accuracy and energy efficiency and enhancing adaptability to diverse application demands. 3) A zero-skipping mechanism for sparse inputs significantly reduces energy usage by leveraging the inherent sparsity of spikes without introducing high overheads for low sparsity. 4) Finally, the asynchronous handshaking mechanism maintains the computational efficiency of the pipeline for variable execution times of different computation units. We fabricated \chipname in 65 nm Taiwan Semiconductor Manufacturing Company (TSMC) low-power (LP) technology. It demonstrates competitive performance (scaled to the same technology node) to other digital SNN accelerators proposed in the recent literature and supports advanced reconfigurability. It achieves up to 5 TOPS/W energy efficiency at 95% input sparsity with 4-bit weights and 7-bit Vmem precision.
IMAC: In-memory multi-bit Multiplication andACcumulation in 6T SRAM Array
Mar 27, 2020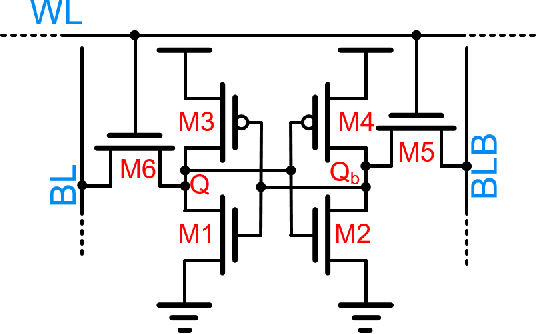
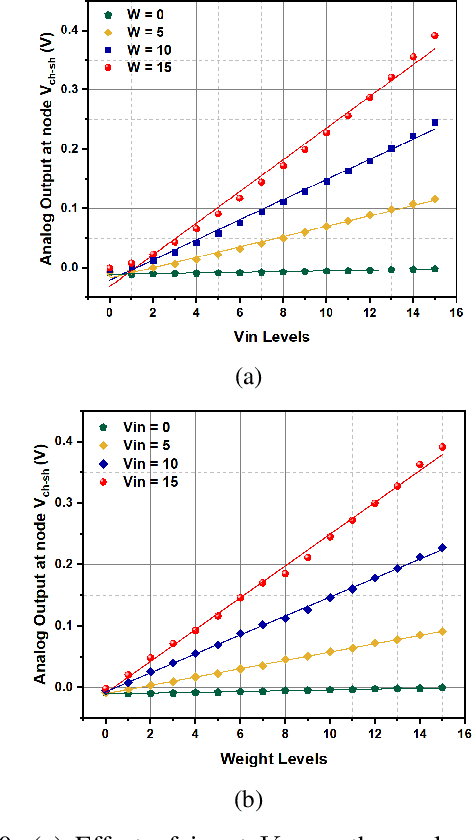

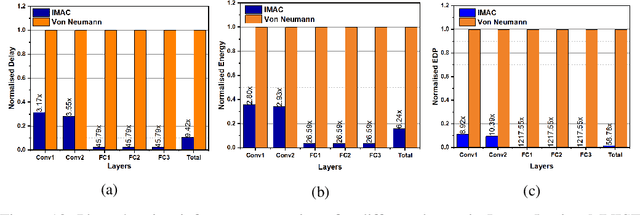
`In-memory computing' is being widely explored as a novel computing paradigm to mitigate the well known memory bottleneck. This emerging paradigm aims at embedding some aspects of computations inside the memory array, thereby avoiding frequent and expensive movement of data between the compute unit and the storage memory. In-memory computing with respect to Silicon memories has been widely explored on various memory bit-cells. Embedding computation inside the 6 transistor (6T) SRAM array is of special interest since it is the most widely used on-chip memory. In this paper, we present a novel in-memory multiplication followed by accumulation operation capable of performing parallel dot products within 6T SRAM without any changes to the standard bitcell. We, further, study the effect of circuit non-idealities and process variations on the accuracy of the LeNet-5 and VGG neural network architectures against the MNIST and CIFAR-10 datasets, respectively. The proposed in-memory dot-product mechanism achieves 88.8% and 99% accuracy for the CIFAR-10 and MNIST, respectively. Compared to the standard von Neumann system, the proposed system is 6.24x better in energy consumption and 9.42x better in delay.
Voltage-Driven Domain-Wall Motion based Neuro-Synaptic Devices for Dynamic On-line Learning
Nov 23, 2017
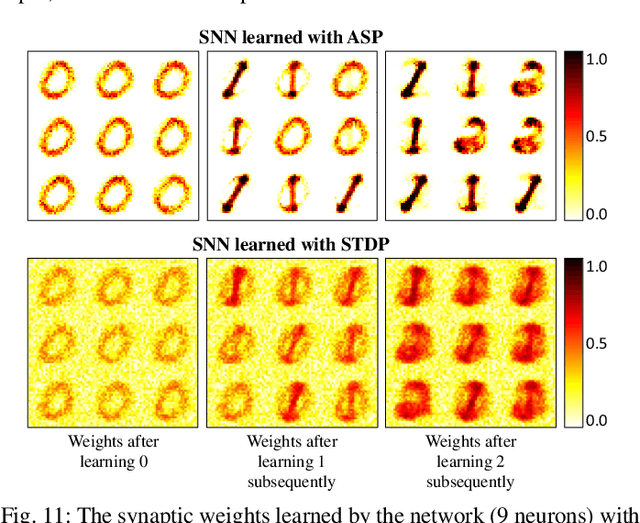

Conventional von-Neumann computing models have achieved remarkable feats for the past few decades. However, they fail to deliver the required efficiency for certain basic tasks like image and speech recognition when compared to biological systems. As such, taking cues from biological systems, novel computing paradigms are being explored for efficient hardware implementations of recognition/classification tasks. The basic building blocks of such neuromorphic systems are neurons and synapses. Towards that end, we propose a leaky-integrate-fire (LIF) neuron and a programmable non-volatile synapse using domain wall motion induced by magneto-electric effect. Due to a strong elastic pinning between the ferro-magnetic domain wall (FM-DW) and the underlying ferro-electric domain wall (FE-DW), the FM-DW gets dragged by the FE-DW on application of a voltage pulse. The fact that FE materials are insulators allows for pure voltage-driven FM-DW motion, which in turn can be used to mimic the behaviors of biological spiking neurons and synapses. The voltage driven nature of the proposed devices allows energy-efficient operation. A detailed device to system level simulation framework based on micromagnetic simulations has been developed to analyze the feasibility of the proposed neuro-synaptic devices. We also demonstrate that the energy-efficient voltage-controlled behavior of the proposed devices make them suitable for dynamic on-line and lifelong learning in spiking neural networks (SNNs).