 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifix: Post-Training Correction to Improve Label Noise Robustness with Verified Samples
Mar 13, 2024
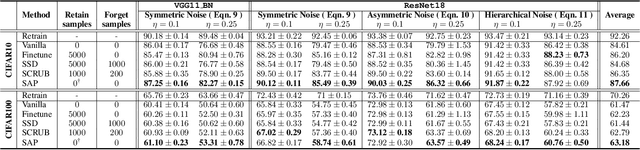

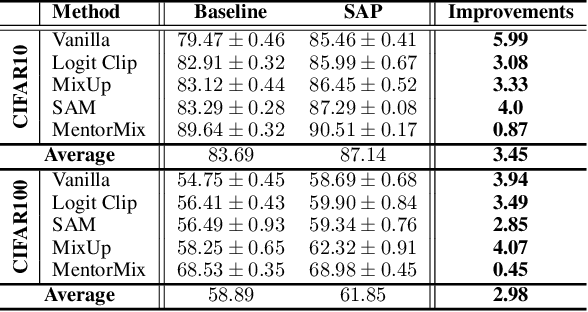
Label corruption, where training samples have incorrect labels, can significantly degrade the performance of machine learning models. This corruption often arises from non-expert labeling or adversarial attacks. Acquiring large, perfectly labeled datasets is costly, and retraining large models from scratch when a clean dataset becomes available is computationally expensive. To address this challenge, we propose Post-Training Correction, a new paradigm that adjusts model parameters after initial training to mitigate label noise, eliminating the need for retraining. We introduce Verifix, a novel Singular Value Decomposition (SVD) based algorithm that leverages a small, verified dataset to correct the model weights using a single update. Verifix uses SVD to estimate a Clean Activation Space and then projects the model's weights onto this space to suppress activations corresponding to corrupted data. We demonstrate Verifix's effectiveness on both synthetic and real-world label noise. Experiments on the CIFAR dataset with 25% synthetic corruption show 7.36% generalization improvements on average. Additionally, we observe generalization improvements of up to 2.63% on naturally corrupted datasets like WebVision1.0 and Clothing1M.
Deep Unlearning: Fast and Efficient Training-free Approach to Controlled Forgetting
Dec 04, 2023Machine unlearning has emerged as a prominent and challenging area of interest, driven in large part by the rising regulatory demands for industries to delete user data upon request and the heightened awareness of privacy. Existing approaches either retrain models from scratch or use several finetuning steps for every deletion request, often constrained by computational resource limitations and restricted access to the original training data. In this work, we introduce a novel class unlearning algorithm designed to strategically eliminate an entire class or a group of classes from the learned model. To that end, our algorithm first estimates the Retain Space and the Forget Space, representing the feature or activation spaces for samples from classes to be retained and unlearned, respectively. To obtain these spaces, we propose a novel singular value decomposition-based technique that requires layer wise collection of network activations from a few forward passes through the network. We then compute the shared information between these spaces and remove it from the forget space to isolate class-discriminatory feature space for unlearning. Finally, we project the model weights in the orthogonal direction of the class-discriminatory space to obtain the unlearned model. We demonstrate our algorithm's efficacy on ImageNet using a Vision Transformer with only $\sim$1.5% drop in retain accuracy compared to the original model while maintaining under 1% accuracy on the unlearned class samples. Further, our algorithm consistently performs well when subject to Membership Inference Attacks showing 7.8% improvement on average across a variety of image classification datasets and network architectures, as compared to other baselines while being $\sim$6x more computationally efficient.
Neighborhood Gradient Clustering: An Efficient Decentralized Learning Method for Non-IID Data Distributions
Sep 30, 2022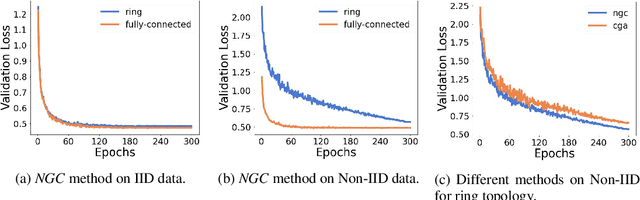
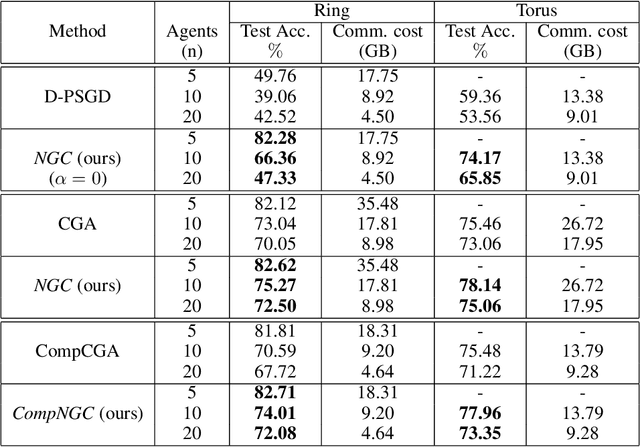
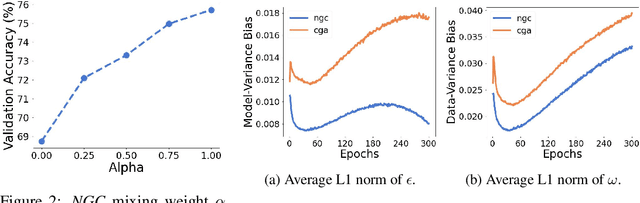
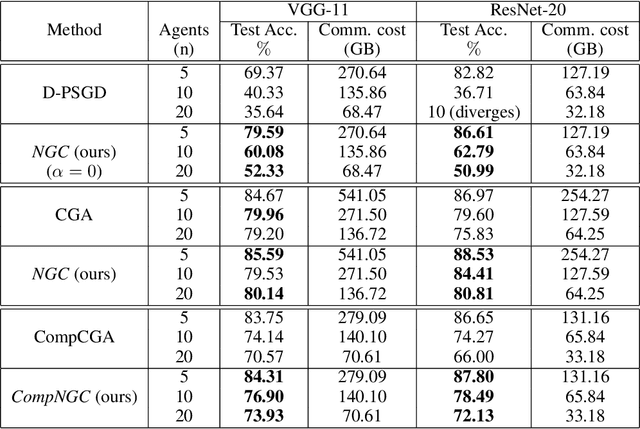
Decentralized learning algorithms enable the training of deep learning models over large distributed datasets generated at different devices and locations, without the need for a central server. In practical scenarios, the distributed datasets can have significantly different data distributions across the agents. The current state-of-the-art decentralized algorithms mostly assume the data distributions to be Independent and Identically Distributed (IID). This paper focuses on improving decentralized learning over non-IID data distributions with minimal compute and memory overheads. We propose Neighborhood Gradient Clustering (NGC), a novel decentralized learning algorithm that modifies the local gradients of each agent using self- and cross-gradient information. In particular, the proposed method replaces the local gradients of the model with the weighted mean of the self-gradients, model-variant cross-gradients (derivatives of the received neighbors' model parameters with respect to the local dataset), and data-variant cross-gradients (derivatives of the local model with respect to its neighbors' datasets). Further, we present CompNGC, a compressed version of NGC that reduces the communication overhead by $32 \times$ by compressing the cross-gradients. We demonstrate the empirical convergence and efficiency of the proposed technique over non-IID data distributions sampled from the CIFAR-10 dataset on various model architectures and graph topologies. Our experiments demonstrate that NGC and CompNGC outperform the existing state-of-the-art (SoTA) decentralized learning algorithm over non-IID data by $1-5\%$ with significantly less compute and memory requirements. Further, we also show that the proposed NGC method outperforms the baseline by $5-40\%$ with no additional communication.
Low Precision Decentralized Distributed Training with Heterogeneous Data
Nov 17, 2021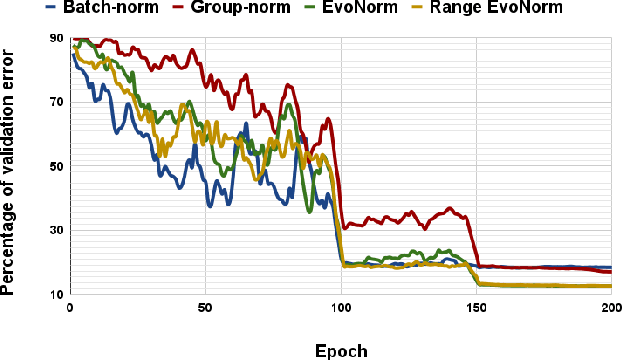
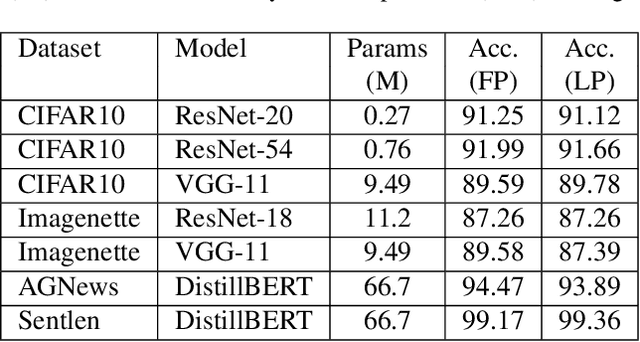
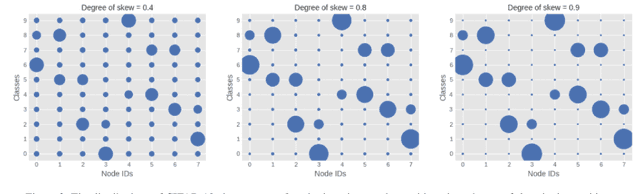
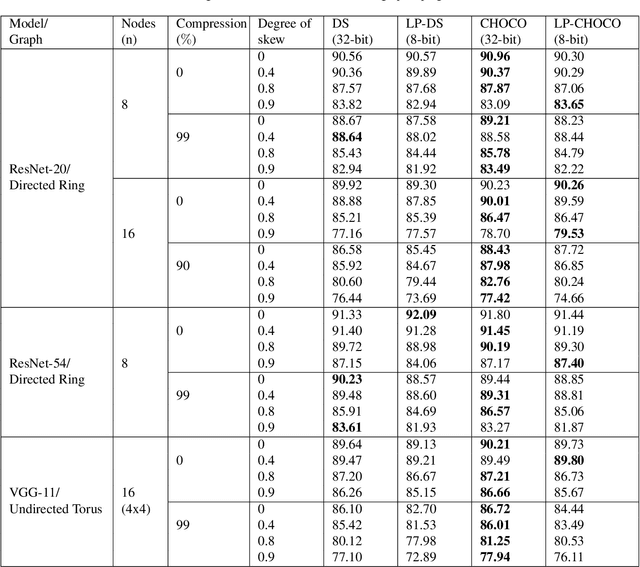
Decentralized distributed learning is the key to enabling large-scale machine learning (training) on the edge devices utilizing private user-generated local data, without relying on the cloud. However, practical realization of such on-device training is limited by the communication bottleneck, computation complexity of training deep models and significant data distribution skew across devices. Many feedback-based compression techniques have been proposed in the literature to reduce the communication cost and a few works propose algorithmic changes to aid the performance in the presence of skewed data distribution by improving convergence rate. To the best of our knowledge, there is no work in the literature that applies and shows compute efficient training techniques such quantization, pruning etc., for peer-to-peer decentralized learning setups. In this paper, we analyze and show the convergence of low precision decentralized training that aims to reduce the computational complexity of training and inference. Further, We study the effect of degree of skew and communication compression on the low precision decentralized training over various computer vision and Natural Language Processing (NLP) tasks. Our experiments indicate that 8-bit decentralized training has minimal accuracy loss compared to its full precision counterpart even with heterogeneous data. However, when low precision training is accompanied by communication compression through sparsification we observe 1-2% drop in accuracy. The proposed low precision decentralized training decreases computational complexity, memory usage, and communication cost by ~4x while trading off less than a 1% accuracy for both IID and non-IID data. In particular, with higher skew values, we observe an increase in accuracy (by ~0.5%) with low precision training, indicating the regularization effect of the quantization.
BERMo: What can BERT learn from ELMo?
Oct 18, 2021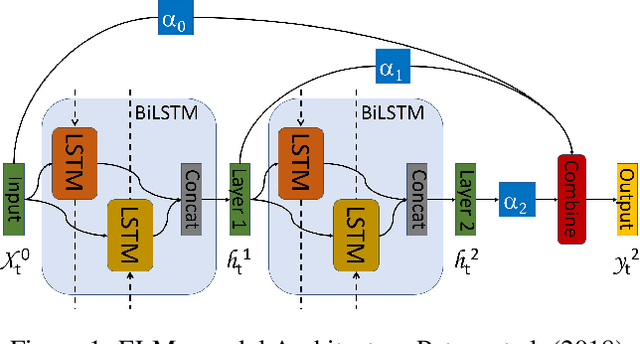


We propose BERMo, an architectural modification to BERT, which makes predictions based on a hierarchy of surface, syntactic and semantic language features. We use linear combination scheme proposed in Embeddings from Language Models (ELMo) to combine the scaled internal representations from different network depths. Our approach has two-fold benefits: (1) improved gradient flow for the downstream task as every layer has a direct connection to the gradients of the loss function and (2) increased representative power as the model no longer needs to copy the features learned in the shallower layer which are necessary for the downstream task. Further, our model has a negligible parameter overhead as there is a single scalar parameter associated with each layer in the network. Experiments on the probing task from SentEval dataset show that our model performs up to $4.65\%$ better in accuracy than the baseline with an average improvement of $2.67\%$ on the semantic tasks. When subject to compression techniques, we find that our model enables stable pruning for compressing small datasets like SST-2, where the BERT model commonly diverges. We observe that our approach converges $1.67\times$ and $1.15\times$ faster than the baseline on MNLI and QQP tasks from GLUE dataset. Moreover, our results show that our approach can obtain better parameter efficiency for penalty based pruning approaches on QQP task.
Exploring Vicinal Risk Minimization for Lightweight Out-of-Distribution Detection
Dec 15, 2020
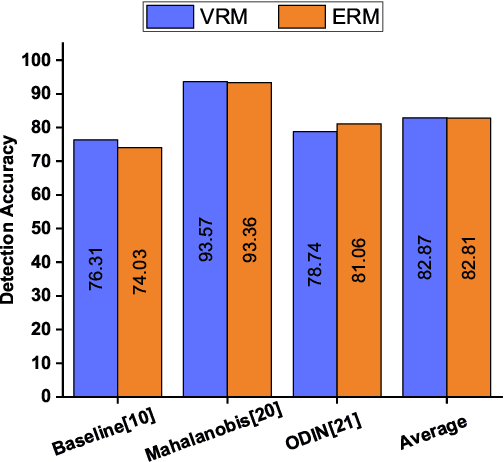
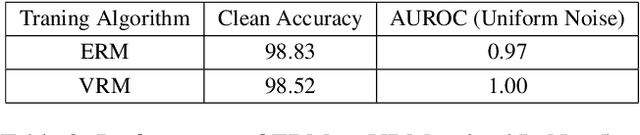
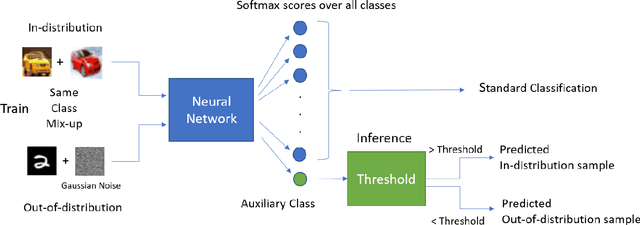
Deep neural networks have found widespread adoption in solving complex tasks ranging from image recognition to natural language processing. However, these networks make confident mispredictions when presented with data that does not belong to the training distribution, i.e. out-of-distribution (OoD) samples. In this paper we explore whether the property of Vicinal Risk Minimization (VRM) to smoothly interpolate between different class boundaries helps to train better OoD detectors. We apply VRM to existing OoD detection techniques and show their improved performance. We observe that existing OoD detectors have significant memory and compute overhead, hence we leverage VRM to develop an OoD detector with minimal overheard. Our detection method introduces an auxiliary class for classifying OoD samples. We utilize mixup in two ways to implement Vicinal Risk Minimization. First, we perform mixup within the same class and second, we perform mixup with Gaussian noise when training the auxiliary class. Our method achieves near competitive performance with significantly less compute and memory overhead when compared to existing OoD detection techniques. This facilitates the deployment of OoD detection on edge devices and expands our understanding of Vicinal Risk Minimization for use in training OoD detectors.
TREND: Transferability based Robust ENsemble Design
Aug 04, 2020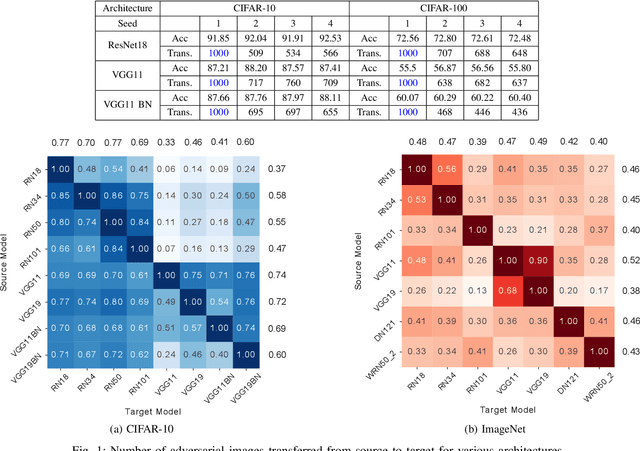
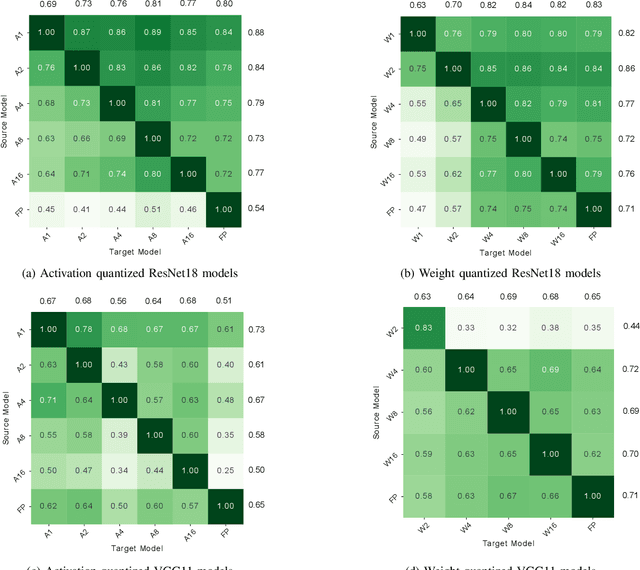

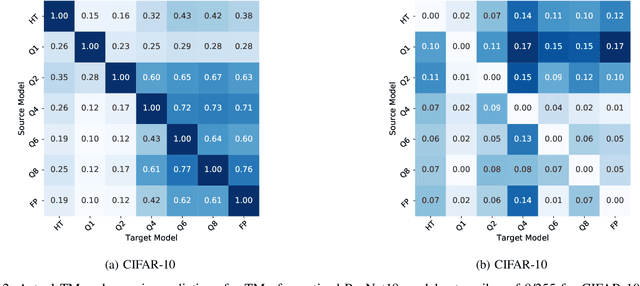
Deep Learning models hold state-of-the-art performance in many fields, but their vulnerability to adversarial examples poses a threat to their ubiquitous deployment in practical settings. Additionally, adversarial inputs generated on one classifier have been shown to transfer to other classifiers trained on similar data, which makes the attacks possible even if the model parameters are not revealed to the adversary. This property of transferability has not yet been systematically studied, leading to a gap in our understanding of robustness of neural networks to adversarial inputs. In this work, we study the effect of network architecture, initialization, input, weight and activation quantization on transferability. Our experiments reveal that transferability is significantly hampered by input quantization and architectural mismatch between source and target, is unaffected by initialization and is architecture-dependent for both weight and activation quantization. To quantify transferability, we propose a simple metric, which is a function of the attack strength. We demonstrate the utility of the proposed metric in designing a methodology to build ensembles with improved adversarial robustness. Finally, we show that an ensemble consisting of carefully chosen input quantized networks achieves better adversarial robustness than would otherwise be possible with a single network.
IMAC: In-memory multi-bit Multiplication andACcumulation in 6T SRAM Array
Mar 27, 2020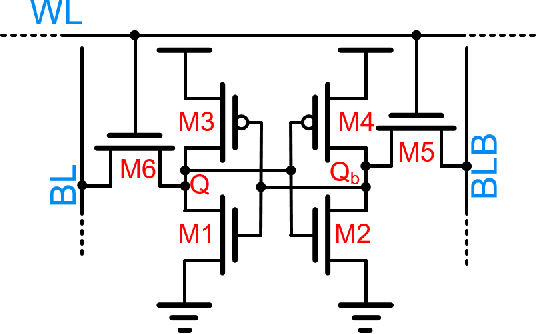
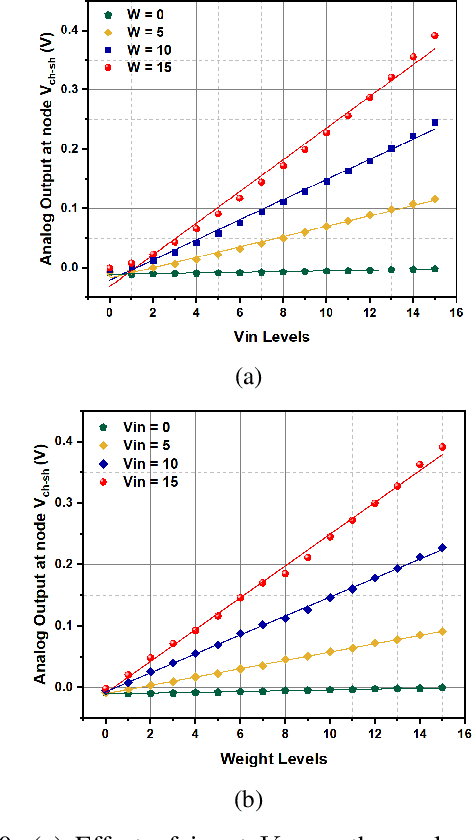

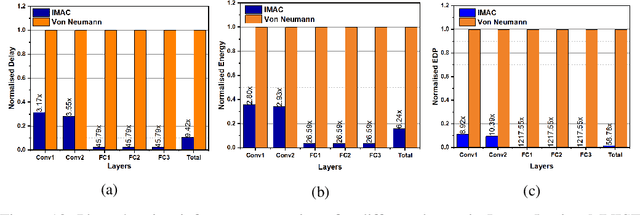
`In-memory computing' is being widely explored as a novel computing paradigm to mitigate the well known memory bottleneck. This emerging paradigm aims at embedding some aspects of computations inside the memory array, thereby avoiding frequent and expensive movement of data between the compute unit and the storage memory. In-memory computing with respect to Silicon memories has been widely explored on various memory bit-cells. Embedding computation inside the 6 transistor (6T) SRAM array is of special interest since it is the most widely used on-chip memory. In this paper, we present a novel in-memory multiplication followed by accumulation operation capable of performing parallel dot products within 6T SRAM without any changes to the standard bitcell. We, further, study the effect of circuit non-idealities and process variations on the accuracy of the LeNet-5 and VGG neural network architectures against the MNIST and CIFAR-10 datasets, respectively. The proposed in-memory dot-product mechanism achieves 88.8% and 99% accuracy for the CIFAR-10 and MNIST, respectively. Compared to the standard von Neumann system, the proposed system is 6.24x better in energy consumption and 9.42x better in delay.