 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSADDLe: Sharpness-Aware Decentralized Deep Learning with Heterogeneous Data
May 22, 2024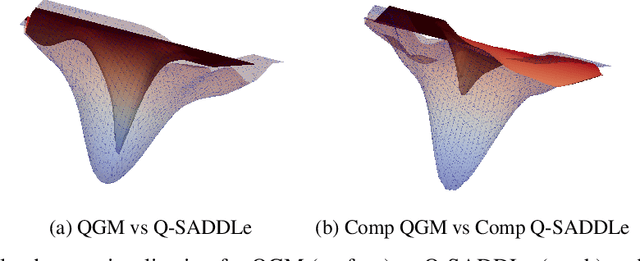
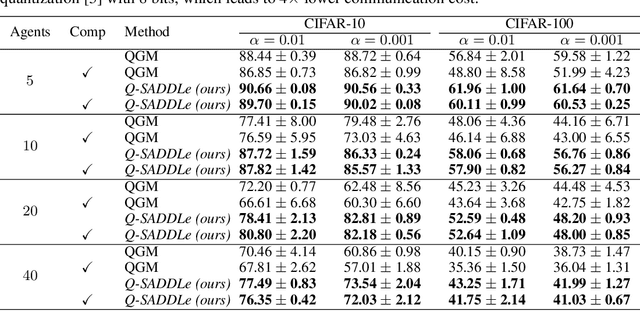
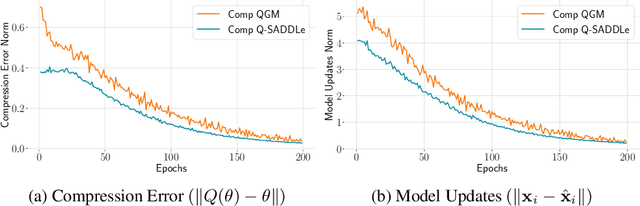
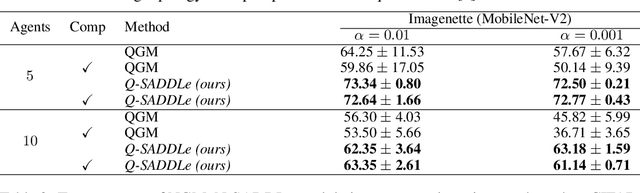
Decentralized training enables learning with distributed datasets generated at different locations without relying on a central server. In realistic scenarios, the data distribution across these sparsely connected learning agents can be significantly heterogeneous, leading to local model over-fitting and poor global model generalization. Another challenge is the high communication cost of training models in such a peer-to-peer fashion without any central coordination. In this paper, we jointly tackle these two-fold practical challenges by proposing SADDLe, a set of sharpness-aware decentralized deep learning algorithms. SADDLe leverages Sharpness-Aware Minimization (SAM) to seek a flatter loss landscape during training, resulting in better model generalization as well as enhanced robustness to communication compression. We present two versions of our approach and conduct extensive experiments to show that SADDLe leads to 1-20% improvement in test accuracy compared to other existing techniques. Additionally, our proposed approach is robust to communication compression, with an average drop of only 1% in the presence of up to 4x compression.
AdaGossip: Adaptive Consensus Step-size for Decentralized Deep Learning with Communication Compression
Apr 09, 2024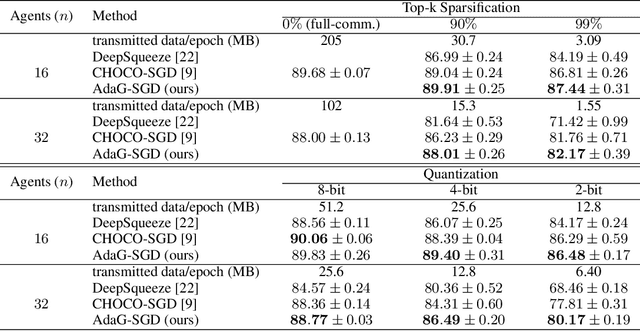
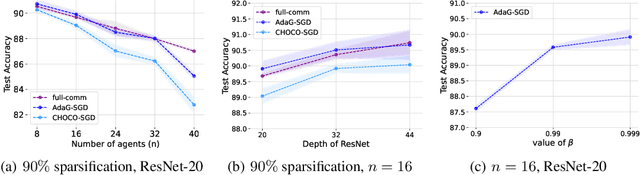


Decentralized learning is crucial in supporting on-device learning over large distributed datasets, eliminating the need for a central server. However, the communication overhead remains a major bottleneck for the practical realization of such decentralized setups. To tackle this issue, several algorithms for decentralized training with compressed communication have been proposed in the literature. Most of these algorithms introduce an additional hyper-parameter referred to as consensus step-size which is tuned based on the compression ratio at the beginning of the training. In this work, we propose AdaGossip, a novel technique that adaptively adjusts the consensus step-size based on the compressed model differences between neighboring agents. We demonstrate the effectiveness of the proposed method through an exhaustive set of experiments on various Computer Vision datasets (CIFAR-10, CIFAR-100, Fashion MNIST, Imagenette, and ImageNet), model architectures, and network topologies. Our experiments show that the proposed method achieves superior performance ($0-2\%$ improvement in test accuracy) compared to the current state-of-the-art method for decentralized learning with communication compression.
Towards Two-Stream Foveation-based Active Vision Learning
Mar 24, 2024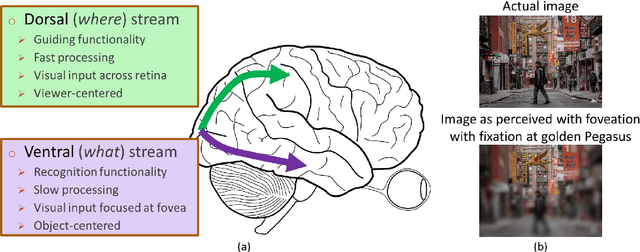
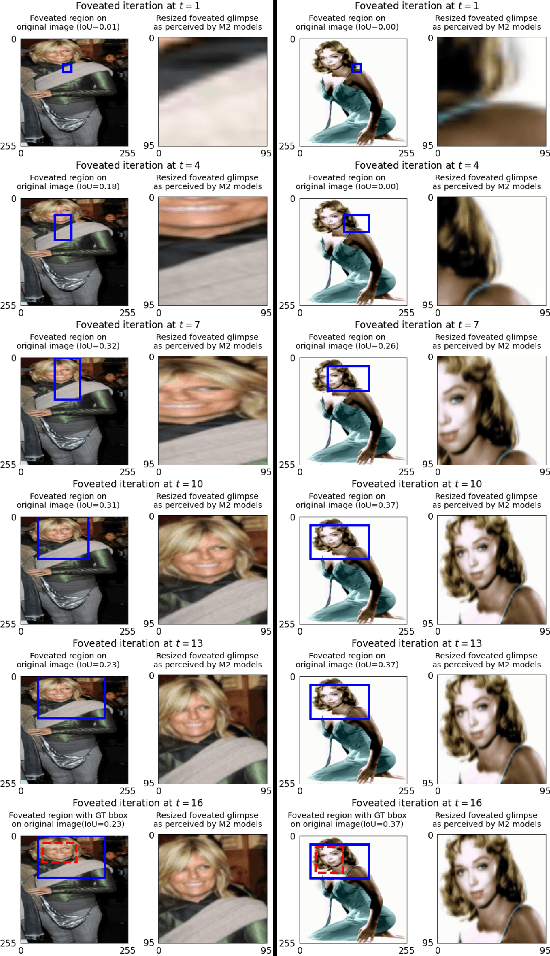

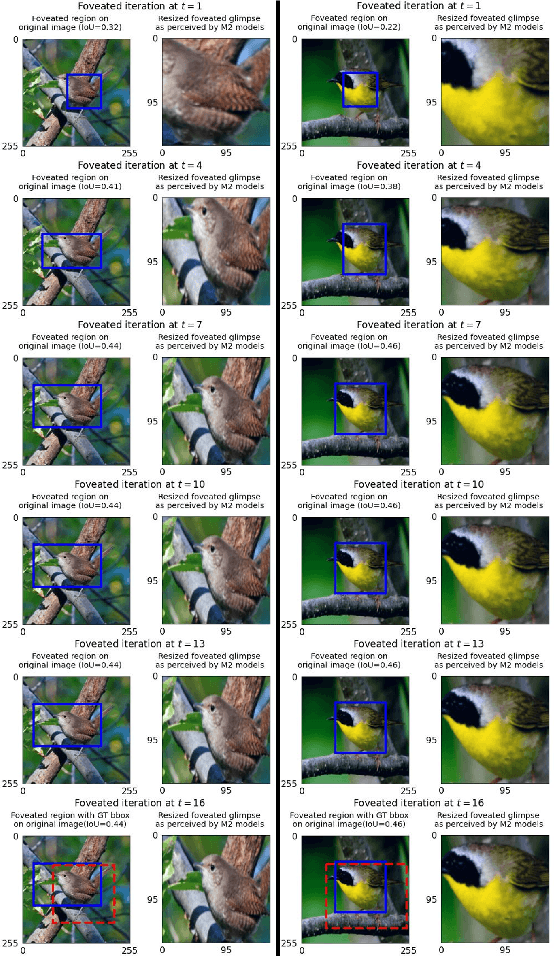
Deep neural network (DNN) based machine perception frameworks process the entire input in a one-shot manner to provide answers to both "what object is being observed" and "where it is located". In contrast, the "two-stream hypothesis" from neuroscience explains the neural processing in the human visual cortex as an active vision system that utilizes two separate regions of the brain to answer the what and the where questions. In this work, we propose a machine learning framework inspired by the "two-stream hypothesis" and explore the potential benefits that it offers. Specifically, the proposed framework models the following mechanisms: 1) ventral (what) stream focusing on the input regions perceived by the fovea part of an eye (foveation), 2) dorsal (where) stream providing visual guidance, and 3) iterative processing of the two streams to calibrate visual focus and process the sequence of focused image patches. The training of the proposed framework is accomplished by label-based DNN training for the ventral stream model and reinforcement learning for the dorsal stream model. We show that the two-stream foveation-based learning is applicable to the challenging task of weakly-supervised object localization (WSOL), where the training data is limited to the object class or its attributes. The framework is capable of both predicting the properties of an object and successfully localizing it by predicting its bounding box. We also show that, due to the independent nature of the two streams, the dorsal model can be applied on its own to unseen images to localize objects from different datasets.
Averaging Rate Scheduler for Decentralized Learning on Heterogeneous Data
Mar 05, 2024



State-of-the-art decentralized learning algorithms typically require the data distribution to be Independent and Identically Distributed (IID). However, in practical scenarios, the data distribution across the agents can have significant heterogeneity. In this work, we propose averaging rate scheduling as a simple yet effective way to reduce the impact of heterogeneity in decentralized learning. Our experiments illustrate the superiority of the proposed method (~3% improvement in test accuracy) compared to the conventional approach of employing a constant averaging rate.
Cross-feature Contrastive Loss for Decentralized Deep Learning on Heterogeneous Data
Oct 26, 2023


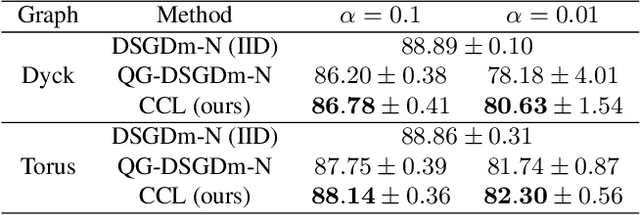
The current state-of-the-art decentralized learning algorithms mostly assume the data distribution to be Independent and Identically Distributed (IID). However, in practical scenarios, the distributed datasets can have significantly heterogeneous data distributions across the agents. In this work, we present a novel approach for decentralized learning on heterogeneous data, where data-free knowledge distillation through contrastive loss on cross-features is utilized to improve performance. Cross-features for a pair of neighboring agents are the features (i.e., last hidden layer activations) obtained from the data of an agent with respect to the model parameters of the other agent. We demonstrate the effectiveness of the proposed technique through an exhaustive set of experiments on various Computer Vision datasets (CIFAR-10, CIFAR-100, Fashion MNIST, Imagenette, and ImageNet), model architectures, and network topologies. Our experiments show that the proposed method achieves superior performance (0.2-4% improvement in test accuracy) compared to other existing techniques for decentralized learning on heterogeneous data.
* 12 pages, 7 figures, 11 tables. arXiv admin note: text overlap with arXiv:2305.04792
Global Update Tracking: A Decentralized Learning Algorithm for Heterogeneous Data
May 08, 2023Decentralized learning enables the training of deep learning models over large distributed datasets generated at different locations, without the need for a central server. However, in practical scenarios, the data distribution across these devices can be significantly different, leading to a degradation in model performance. In this paper, we focus on designing a decentralized learning algorithm that is less susceptible to variations in data distribution across devices. We propose Global Update Tracking (GUT), a novel tracking-based method that aims to mitigate the impact of heterogeneous data in decentralized learning without introducing any communication overhead. We demonstrate the effectiveness of the proposed technique through an exhaustive set of experiments on various Computer Vision datasets (CIFAR-10, CIFAR-100, Fashion MNIST, and ImageNette), model architectures, and network topologies. Our experiments show that the proposed method achieves state-of-the-art performance for decentralized learning on heterogeneous data via a $1-6\%$ improvement in test accuracy compared to other existing techniques.
Homogenizing Non-IID datasets via In-Distribution Knowledge Distillation for Decentralized Learning
Apr 09, 2023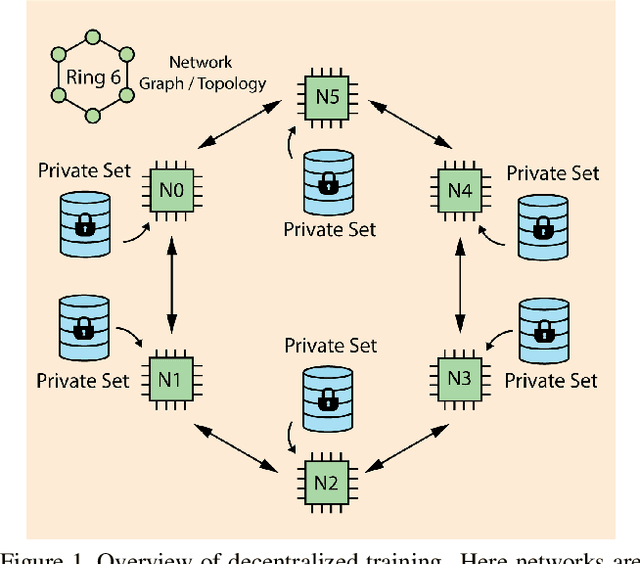

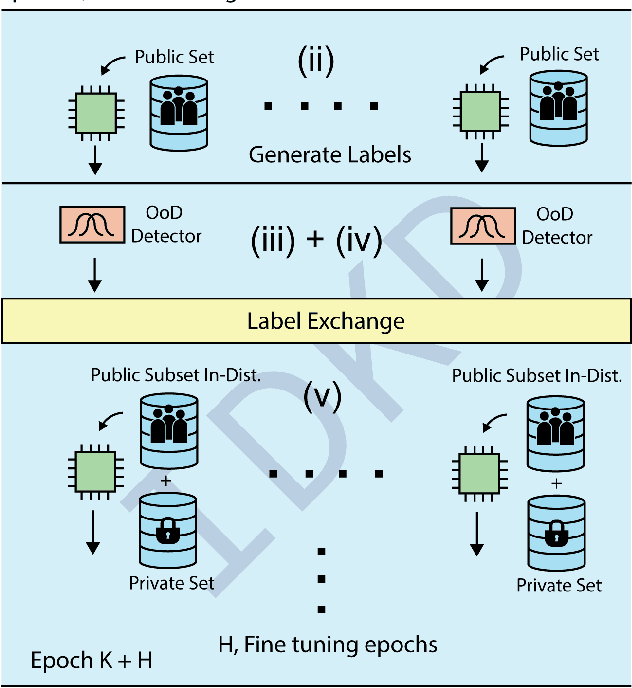

Decentralized learning enables serverless training of deep neural networks (DNNs) in a distributed manner on multiple nodes. This allows for the use of large datasets, as well as the ability to train with a wide variety of data sources. However, one of the key challenges with decentralized learning is heterogeneity in the data distribution across the nodes. In this paper, we propose In-Distribution Knowledge Distillation (IDKD) to address the challenge of heterogeneous data distribution. The goal of IDKD is to homogenize the data distribution across the nodes. While such data homogenization can be achieved by exchanging data among the nodes sacrificing privacy, IDKD achieves the same objective using a common public dataset across nodes without breaking the privacy constraint. This public dataset is different from the training dataset and is used to distill the knowledge from each node and communicate it to its neighbors through the generated labels. With traditional knowledge distillation, the generalization of the distilled model is reduced because all the public dataset samples are used irrespective of their similarity to the local dataset. Thus, we introduce an Out-of-Distribution (OoD) detector at each node to label a subset of the public dataset that maps close to the local training data distribution. Finally, only labels corresponding to these subsets are exchanged among the nodes and with appropriate label averaging each node is finetuned on these data subsets along with its local data. Our experiments on multiple image classification datasets and graph topologies show that the proposed IDKD scheme is more effective than traditional knowledge distillation and achieves state-of-the-art generalization performance on heterogeneously distributed data with minimal communication overhead.
CoDeC: Communication-Efficient Decentralized Continual Learning
Mar 27, 2023



Training at the edge utilizes continuously evolving data generated at different locations. Privacy concerns prohibit the co-location of this spatially as well as temporally distributed data, deeming it crucial to design training algorithms that enable efficient continual learning over decentralized private data. Decentralized learning allows serverless training with spatially distributed data. A fundamental barrier in such distributed learning is the high bandwidth cost of communicating model updates between agents. Moreover, existing works under this training paradigm are not inherently suitable for learning a temporal sequence of tasks while retaining the previously acquired knowledge. In this work, we propose CoDeC, a novel communication-efficient decentralized continual learning algorithm which addresses these challenges. We mitigate catastrophic forgetting while learning a task sequence in a decentralized learning setup by combining orthogonal gradient projection with gossip averaging across decentralized agents. Further, CoDeC includes a novel lossless communication compression scheme based on the gradient subspaces. We express layer-wise gradients as a linear combination of the basis vectors of these gradient subspaces and communicate the associated coefficients. We theoretically analyze the convergence rate for our algorithm and demonstrate through an extensive set of experiments that CoDeC successfully learns distributed continual tasks with minimal forgetting. The proposed compression scheme results in up to 4.8x reduction in communication costs with iso-performance as the full communication baseline.
Neighborhood Gradient Clustering: An Efficient Decentralized Learning Method for Non-IID Data Distributions
Sep 30, 2022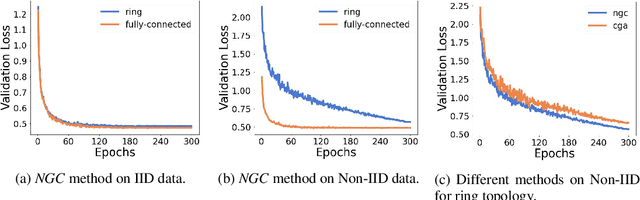
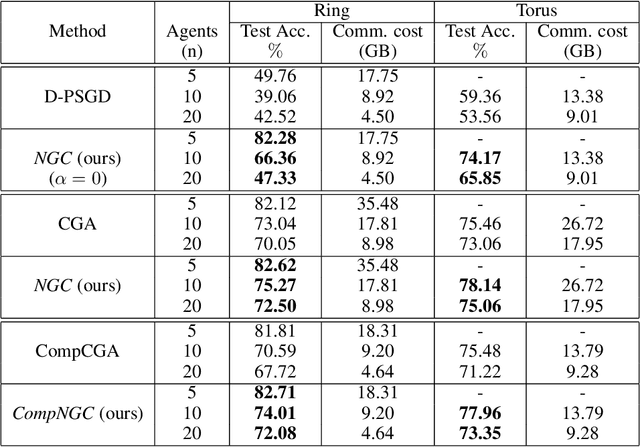
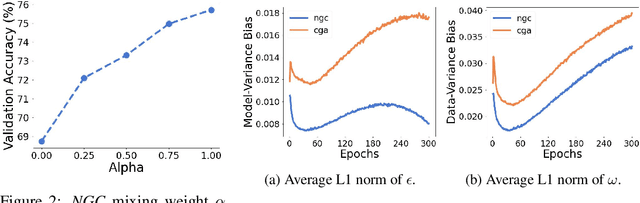
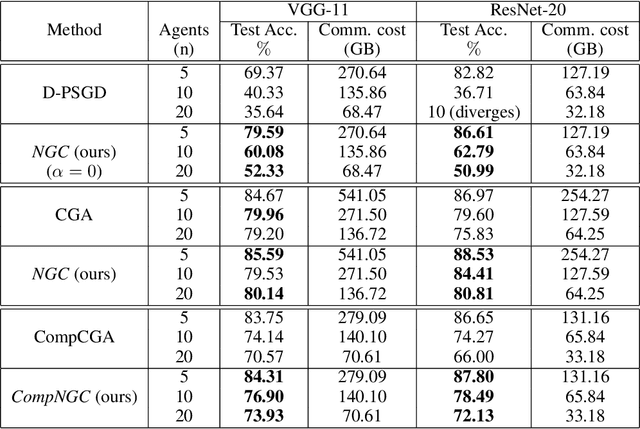
Decentralized learning algorithms enable the training of deep learning models over large distributed datasets generated at different devices and locations, without the need for a central server. In practical scenarios, the distributed datasets can have significantly different data distributions across the agents. The current state-of-the-art decentralized algorithms mostly assume the data distributions to be Independent and Identically Distributed (IID). This paper focuses on improving decentralized learning over non-IID data distributions with minimal compute and memory overheads. We propose Neighborhood Gradient Clustering (NGC), a novel decentralized learning algorithm that modifies the local gradients of each agent using self- and cross-gradient information. In particular, the proposed method replaces the local gradients of the model with the weighted mean of the self-gradients, model-variant cross-gradients (derivatives of the received neighbors' model parameters with respect to the local dataset), and data-variant cross-gradients (derivatives of the local model with respect to its neighbors' datasets). Further, we present CompNGC, a compressed version of NGC that reduces the communication overhead by $32 \times$ by compressing the cross-gradients. We demonstrate the empirical convergence and efficiency of the proposed technique over non-IID data distributions sampled from the CIFAR-10 dataset on various model architectures and graph topologies. Our experiments demonstrate that NGC and CompNGC outperform the existing state-of-the-art (SoTA) decentralized learning algorithm over non-IID data by $1-5\%$ with significantly less compute and memory requirements. Further, we also show that the proposed NGC method outperforms the baseline by $5-40\%$ with no additional communication.
Low Precision Decentralized Distributed Training with Heterogeneous Data
Nov 17, 2021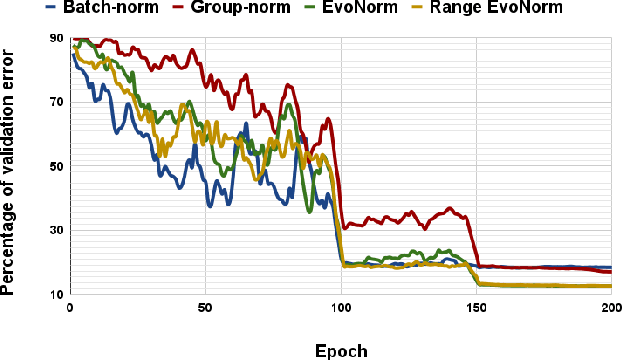
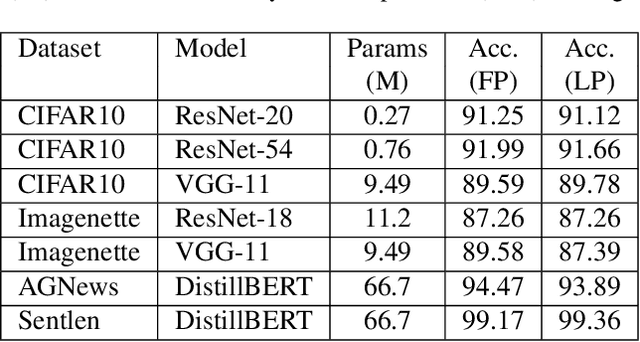
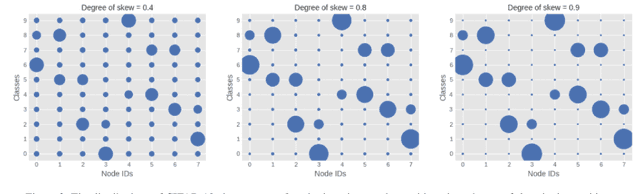
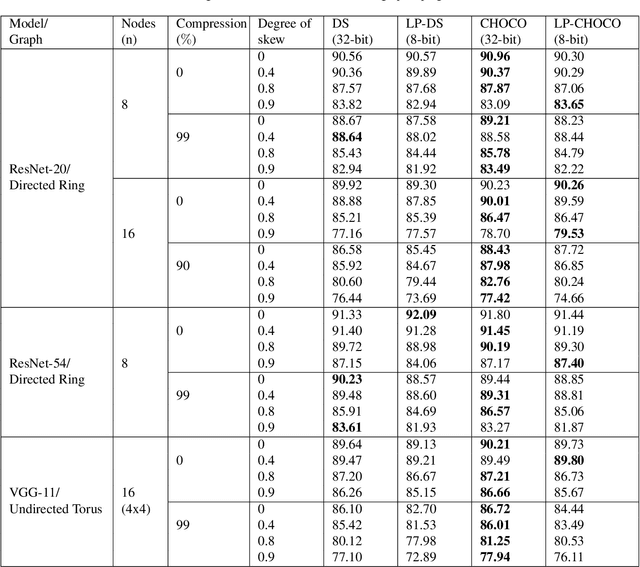
Decentralized distributed learning is the key to enabling large-scale machine learning (training) on the edge devices utilizing private user-generated local data, without relying on the cloud. However, practical realization of such on-device training is limited by the communication bottleneck, computation complexity of training deep models and significant data distribution skew across devices. Many feedback-based compression techniques have been proposed in the literature to reduce the communication cost and a few works propose algorithmic changes to aid the performance in the presence of skewed data distribution by improving convergence rate. To the best of our knowledge, there is no work in the literature that applies and shows compute efficient training techniques such quantization, pruning etc., for peer-to-peer decentralized learning setups. In this paper, we analyze and show the convergence of low precision decentralized training that aims to reduce the computational complexity of training and inference. Further, We study the effect of degree of skew and communication compression on the low precision decentralized training over various computer vision and Natural Language Processing (NLP) tasks. Our experiments indicate that 8-bit decentralized training has minimal accuracy loss compared to its full precision counterpart even with heterogeneous data. However, when low precision training is accompanied by communication compression through sparsification we observe 1-2% drop in accuracy. The proposed low precision decentralized training decreases computational complexity, memory usage, and communication cost by ~4x while trading off less than a 1% accuracy for both IID and non-IID data. In particular, with higher skew values, we observe an increase in accuracy (by ~0.5%) with low precision training, indicating the regularization effect of the quantization.