 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSADDLe: Sharpness-Aware Decentralized Deep Learning with Heterogeneous Data
Paper and Code
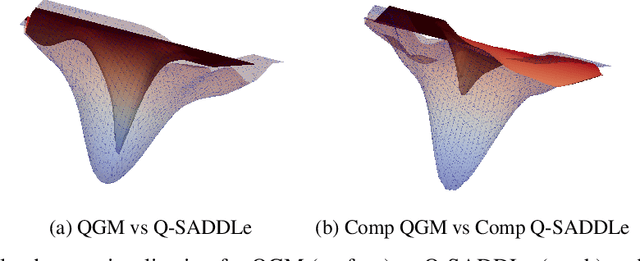
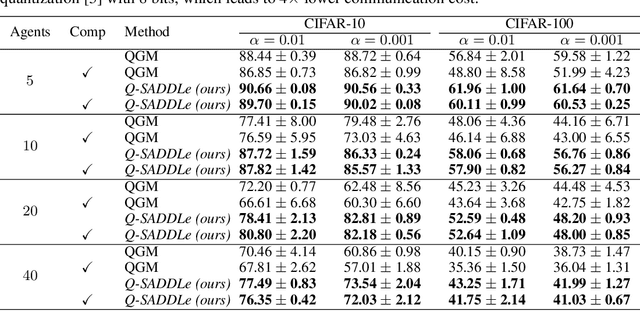
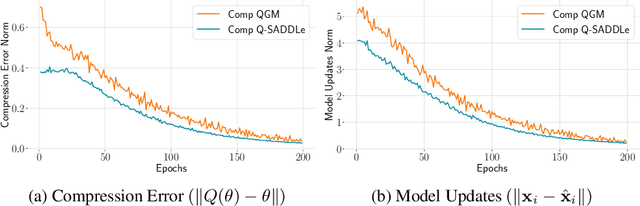
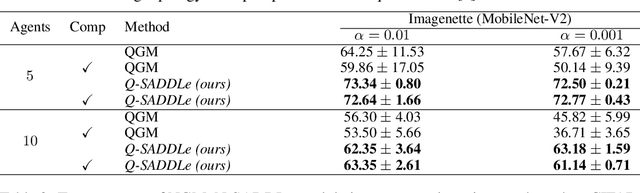
Decentralized training enables learning with distributed datasets generated at different locations without relying on a central server. In realistic scenarios, the data distribution across these sparsely connected learning agents can be significantly heterogeneous, leading to local model over-fitting and poor global model generalization. Another challenge is the high communication cost of training models in such a peer-to-peer fashion without any central coordination. In this paper, we jointly tackle these two-fold practical challenges by proposing SADDLe, a set of sharpness-aware decentralized deep learning algorithms. SADDLe leverages Sharpness-Aware Minimization (SAM) to seek a flatter loss landscape during training, resulting in better model generalization as well as enhanced robustness to communication compression. We present two versions of our approach and conduct extensive experiments to show that SADDLe leads to 1-20% improvement in test accuracy compared to other existing techniques. Additionally, our proposed approach is robust to communication compression, with an average drop of only 1% in the presence of up to 4x compression.