 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOASIS: Online Activation Subspace Learning for Memory-Efficient Training
Apr 10, 2026Training large language models (LLMs) is constrained by memory requirements, with activations accounting for a substantial fraction of the total footprint. Existing approaches reduce memory using low-rank weight parameterizations or low-rank gradient subspaces for optimizer states, while activation memory is addressed through architectural modifications or compression schemes based on periodically updated projections. We propose OASIS, an online activation subspace learning algorithm for memory-efficient training that tracks and continuously updates a low-dimensional activation subspace during training. Intermediate activations are projected onto this evolving subspace, reducing memory without modifying forward-pass computations. The evolving activation subspace induces low-rank gradient representations, enabling both gradients and optimizer states to be maintained directly in this subspace, while a projection-aware optimizer consistently transports optimizer states across subspace updates for stable training. Across various finetuning and pretraining tasks, OASIS achieves up to $2\times$ lower peak memory than full fine-tuning while matching its performance and outperforming prior low-rank methods.
Learning When to Attend: Conditional Memory Access for Long-Context LLMs
Mar 18, 2026Language models struggle to generalize beyond pretraining context lengths, limiting long-horizon reasoning and retrieval. Continued pretraining on long-context data can help but is expensive due to the quadratic scaling of Attention. We observe that most tokens do not require (Global) Attention over the entire sequence and can rely on local context. Based on this, we propose L2A (Learning To Attend), a layer that enables conditional (token-wise) long-range memory access by deciding when to invoke global attention. We evaluate L2A on Qwen 2.5 and Qwen 3 models, extending their effective context length from 32K to 128K tokens. L2A matches the performance of standard long-context training to within 3% while skipping Global Attention for $\sim$80% of tokens, outperforming prior baselines. We also design custom Triton kernels to efficiently implement this token-wise conditional Attention on GPUs, achieving up to $\sim$2x improvements in training throughput and time-to-first-token over FlashAttention. Moreover, L2A enables post-training pruning of highly sparse Global Attention layers, reducing KV cache memory by up to 50% with negligible performance loss.
TRIM: Token-wise Attention-Derived Saliency for Data-Efficient Instruction Tuning
Oct 08, 2025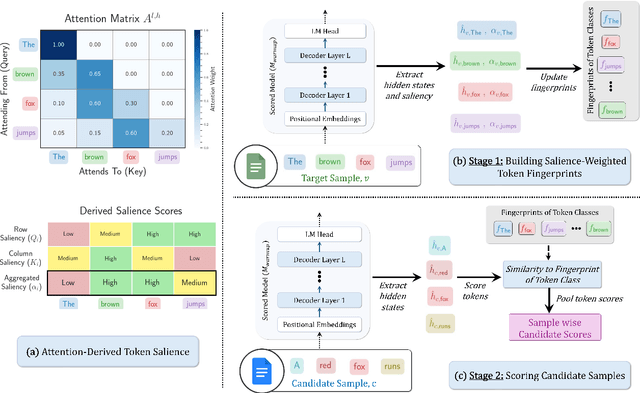
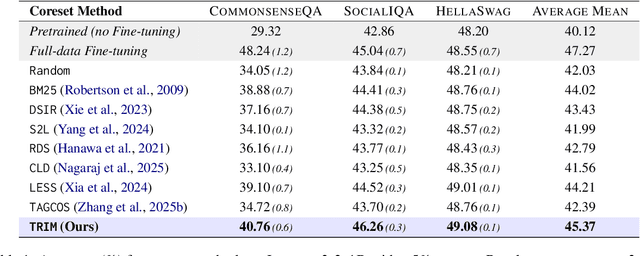
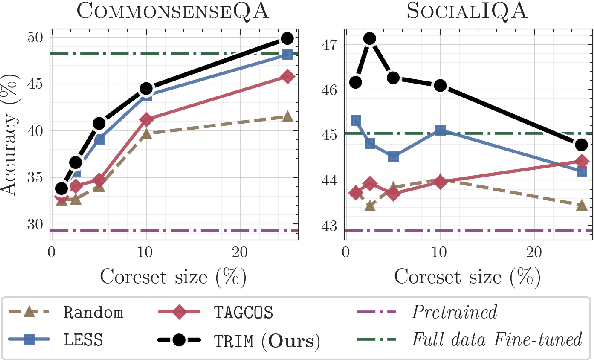

Instruction tuning is essential for aligning large language models (LLMs) to downstream tasks and commonly relies on large, diverse corpora. However, small, high-quality subsets, known as coresets, can deliver comparable or superior results, though curating them remains challenging. Existing methods often rely on coarse, sample-level signals like gradients, an approach that is computationally expensive and overlooks fine-grained features. To address this, we introduce TRIM (Token Relevance via Interpretable Multi-layer Attention), a forward-only, token-centric framework. Instead of using gradients, TRIM operates by matching underlying representational patterns identified via attention-based "fingerprints" from a handful of target samples. Such an approach makes TRIM highly efficient and uniquely sensitive to the structural features that define a task. Coresets selected by our method consistently outperform state-of-the-art baselines by up to 9% on downstream tasks and even surpass the performance of full-data fine-tuning in some settings. By avoiding expensive backward passes, TRIM achieves this at a fraction of the computational cost. These findings establish TRIM as a scalable and efficient alternative for building high-quality instruction-tuning datasets.
Eigen Attention: Attention in Low-Rank Space for KV Cache Compression
Aug 10, 2024



Large language models (LLMs) represent a groundbreaking advancement in the domain of natural language processing due to their impressive reasoning abilities. Recently, there has been considerable interest in increasing the context lengths for these models to enhance their applicability to complex tasks. However, at long context lengths and large batch sizes, the key-value (KV) cache, which stores the attention keys and values, emerges as the new bottleneck in memory usage during inference. To address this, we propose Eigen Attention, which performs the attention operation in a low-rank space, thereby reducing the KV cache memory overhead. Our proposed approach is orthogonal to existing KV cache compression techniques and can be used synergistically with them. Through extensive experiments over OPT, MPT, and Llama model families, we demonstrate that Eigen Attention results in up to 40% reduction in KV cache sizes and up to 60% reduction in attention operation latency with minimal drop in performance.
SADDLe: Sharpness-Aware Decentralized Deep Learning with Heterogeneous Data
May 22, 2024
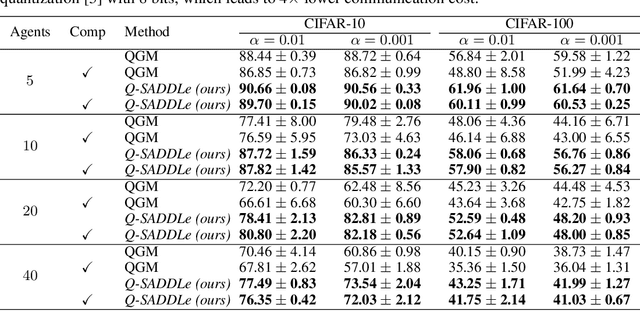
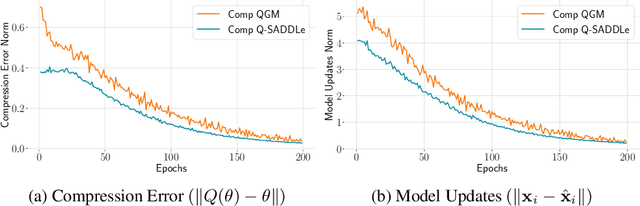
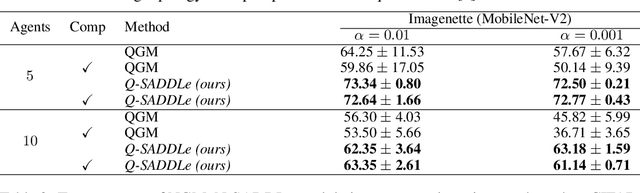
Decentralized training enables learning with distributed datasets generated at different locations without relying on a central server. In realistic scenarios, the data distribution across these sparsely connected learning agents can be significantly heterogeneous, leading to local model over-fitting and poor global model generalization. Another challenge is the high communication cost of training models in such a peer-to-peer fashion without any central coordination. In this paper, we jointly tackle these two-fold practical challenges by proposing SADDLe, a set of sharpness-aware decentralized deep learning algorithms. SADDLe leverages Sharpness-Aware Minimization (SAM) to seek a flatter loss landscape during training, resulting in better model generalization as well as enhanced robustness to communication compression. We present two versions of our approach and conduct extensive experiments to show that SADDLe leads to 1-20% improvement in test accuracy compared to other existing techniques. Additionally, our proposed approach is robust to communication compression, with an average drop of only 1% in the presence of up to 4x compression.
Averaging Rate Scheduler for Decentralized Learning on Heterogeneous Data
Mar 05, 2024



State-of-the-art decentralized learning algorithms typically require the data distribution to be Independent and Identically Distributed (IID). However, in practical scenarios, the data distribution across the agents can have significant heterogeneity. In this work, we propose averaging rate scheduling as a simple yet effective way to reduce the impact of heterogeneity in decentralized learning. Our experiments illustrate the superiority of the proposed method (~3% improvement in test accuracy) compared to the conventional approach of employing a constant averaging rate.
CoDeC: Communication-Efficient Decentralized Continual Learning
Mar 27, 2023



Training at the edge utilizes continuously evolving data generated at different locations. Privacy concerns prohibit the co-location of this spatially as well as temporally distributed data, deeming it crucial to design training algorithms that enable efficient continual learning over decentralized private data. Decentralized learning allows serverless training with spatially distributed data. A fundamental barrier in such distributed learning is the high bandwidth cost of communicating model updates between agents. Moreover, existing works under this training paradigm are not inherently suitable for learning a temporal sequence of tasks while retaining the previously acquired knowledge. In this work, we propose CoDeC, a novel communication-efficient decentralized continual learning algorithm which addresses these challenges. We mitigate catastrophic forgetting while learning a task sequence in a decentralized learning setup by combining orthogonal gradient projection with gossip averaging across decentralized agents. Further, CoDeC includes a novel lossless communication compression scheme based on the gradient subspaces. We express layer-wise gradients as a linear combination of the basis vectors of these gradient subspaces and communicate the associated coefficients. We theoretically analyze the convergence rate for our algorithm and demonstrate through an extensive set of experiments that CoDeC successfully learns distributed continual tasks with minimal forgetting. The proposed compression scheme results in up to 4.8x reduction in communication costs with iso-performance as the full communication baseline.