 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Eigen Attention: Attention in Low-Rank Space for KV Cache Compression
Aug 10, 2024



Large language models (LLMs) represent a groundbreaking advancement in the domain of natural language processing due to their impressive reasoning abilities. Recently, there has been considerable interest in increasing the context lengths for these models to enhance their applicability to complex tasks. However, at long context lengths and large batch sizes, the key-value (KV) cache, which stores the attention keys and values, emerges as the new bottleneck in memory usage during inference. To address this, we propose Eigen Attention, which performs the attention operation in a low-rank space, thereby reducing the KV cache memory overhead. Our proposed approach is orthogonal to existing KV cache compression techniques and can be used synergistically with them. Through extensive experiments over OPT, MPT, and Llama model families, we demonstrate that Eigen Attention results in up to 40% reduction in KV cache sizes and up to 60% reduction in attention operation latency with minimal drop in performance.
Verifix: Post-Training Correction to Improve Label Noise Robustness with Verified Samples
Mar 13, 2024
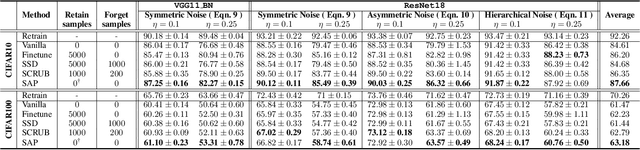

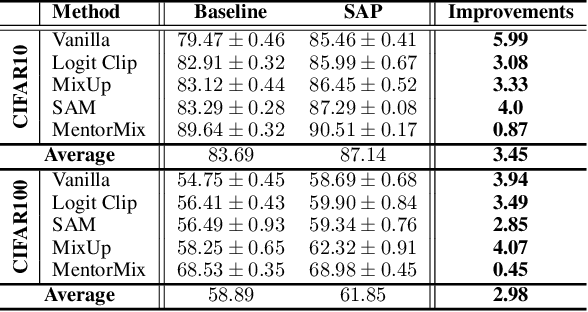
Label corruption, where training samples have incorrect labels, can significantly degrade the performance of machine learning models. This corruption often arises from non-expert labeling or adversarial attacks. Acquiring large, perfectly labeled datasets is costly, and retraining large models from scratch when a clean dataset becomes available is computationally expensive. To address this challenge, we propose Post-Training Correction, a new paradigm that adjusts model parameters after initial training to mitigate label noise, eliminating the need for retraining. We introduce Verifix, a novel Singular Value Decomposition (SVD) based algorithm that leverages a small, verified dataset to correct the model weights using a single update. Verifix uses SVD to estimate a Clean Activation Space and then projects the model's weights onto this space to suppress activations corresponding to corrupted data. We demonstrate Verifix's effectiveness on both synthetic and real-world label noise. Experiments on the CIFAR dataset with 25% synthetic corruption show 7.36% generalization improvements on average. Additionally, we observe generalization improvements of up to 2.63% on naturally corrupted datasets like WebVision1.0 and Clothing1M.
Deep Unlearning: Fast and Efficient Training-free Approach to Controlled Forgetting
Dec 04, 2023Machine unlearning has emerged as a prominent and challenging area of interest, driven in large part by the rising regulatory demands for industries to delete user data upon request and the heightened awareness of privacy. Existing approaches either retrain models from scratch or use several finetuning steps for every deletion request, often constrained by computational resource limitations and restricted access to the original training data. In this work, we introduce a novel class unlearning algorithm designed to strategically eliminate an entire class or a group of classes from the learned model. To that end, our algorithm first estimates the Retain Space and the Forget Space, representing the feature or activation spaces for samples from classes to be retained and unlearned, respectively. To obtain these spaces, we propose a novel singular value decomposition-based technique that requires layer wise collection of network activations from a few forward passes through the network. We then compute the shared information between these spaces and remove it from the forget space to isolate class-discriminatory feature space for unlearning. Finally, we project the model weights in the orthogonal direction of the class-discriminatory space to obtain the unlearned model. We demonstrate our algorithm's efficacy on ImageNet using a Vision Transformer with only $\sim$1.5% drop in retain accuracy compared to the original model while maintaining under 1% accuracy on the unlearned class samples. Further, our algorithm consistently performs well when subject to Membership Inference Attacks showing 7.8% improvement on average across a variety of image classification datasets and network architectures, as compared to other baselines while being $\sim$6x more computationally efficient.
Homogenizing Non-IID datasets via In-Distribution Knowledge Distillation for Decentralized Learning
Apr 09, 2023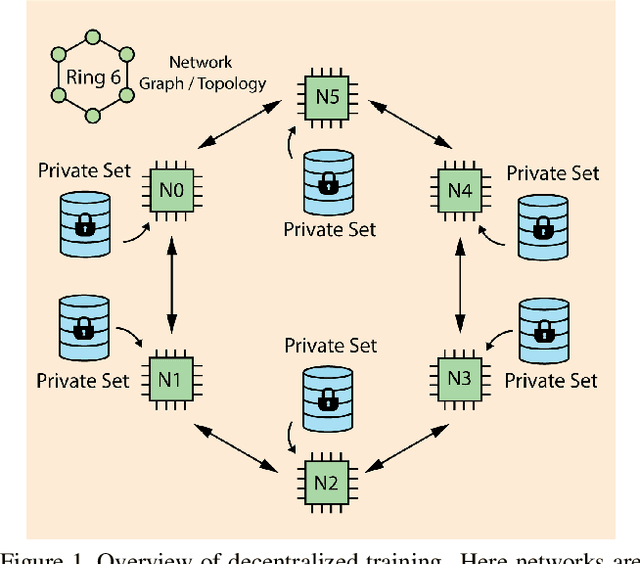

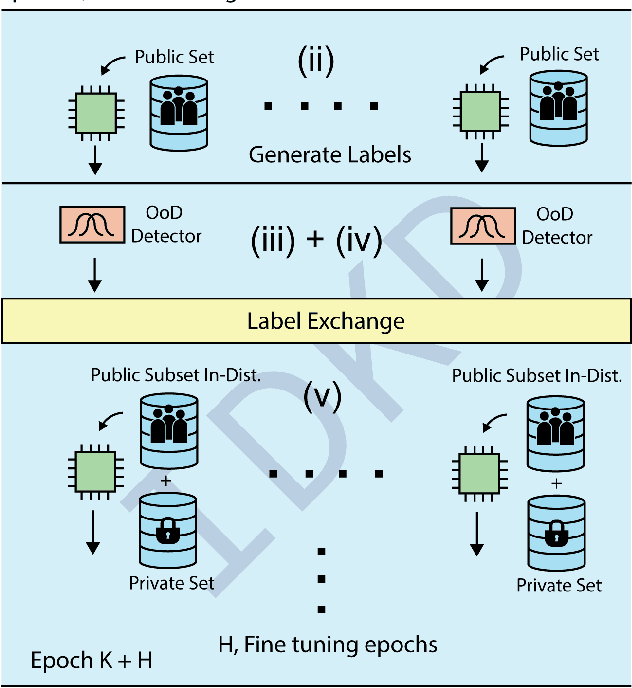

Decentralized learning enables serverless training of deep neural networks (DNNs) in a distributed manner on multiple nodes. This allows for the use of large datasets, as well as the ability to train with a wide variety of data sources. However, one of the key challenges with decentralized learning is heterogeneity in the data distribution across the nodes. In this paper, we propose In-Distribution Knowledge Distillation (IDKD) to address the challenge of heterogeneous data distribution. The goal of IDKD is to homogenize the data distribution across the nodes. While such data homogenization can be achieved by exchanging data among the nodes sacrificing privacy, IDKD achieves the same objective using a common public dataset across nodes without breaking the privacy constraint. This public dataset is different from the training dataset and is used to distill the knowledge from each node and communicate it to its neighbors through the generated labels. With traditional knowledge distillation, the generalization of the distilled model is reduced because all the public dataset samples are used irrespective of their similarity to the local dataset. Thus, we introduce an Out-of-Distribution (OoD) detector at each node to label a subset of the public dataset that maps close to the local training data distribution. Finally, only labels corresponding to these subsets are exchanged among the nodes and with appropriate label averaging each node is finetuned on these data subsets along with its local data. Our experiments on multiple image classification datasets and graph topologies show that the proposed IDKD scheme is more effective than traditional knowledge distillation and achieves state-of-the-art generalization performance on heterogeneously distributed data with minimal communication overhead.
CoDeC: Communication-Efficient Decentralized Continual Learning
Mar 27, 2023



Training at the edge utilizes continuously evolving data generated at different locations. Privacy concerns prohibit the co-location of this spatially as well as temporally distributed data, deeming it crucial to design training algorithms that enable efficient continual learning over decentralized private data. Decentralized learning allows serverless training with spatially distributed data. A fundamental barrier in such distributed learning is the high bandwidth cost of communicating model updates between agents. Moreover, existing works under this training paradigm are not inherently suitable for learning a temporal sequence of tasks while retaining the previously acquired knowledge. In this work, we propose CoDeC, a novel communication-efficient decentralized continual learning algorithm which addresses these challenges. We mitigate catastrophic forgetting while learning a task sequence in a decentralized learning setup by combining orthogonal gradient projection with gossip averaging across decentralized agents. Further, CoDeC includes a novel lossless communication compression scheme based on the gradient subspaces. We express layer-wise gradients as a linear combination of the basis vectors of these gradient subspaces and communicate the associated coefficients. We theoretically analyze the convergence rate for our algorithm and demonstrate through an extensive set of experiments that CoDeC successfully learns distributed continual tasks with minimal forgetting. The proposed compression scheme results in up to 4.8x reduction in communication costs with iso-performance as the full communication baseline.
Continual Learning with Scaled Gradient Projection
Feb 02, 2023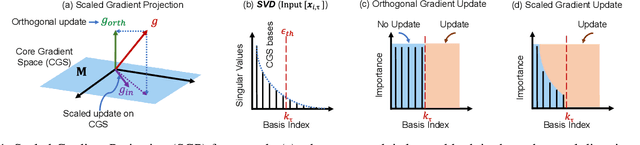
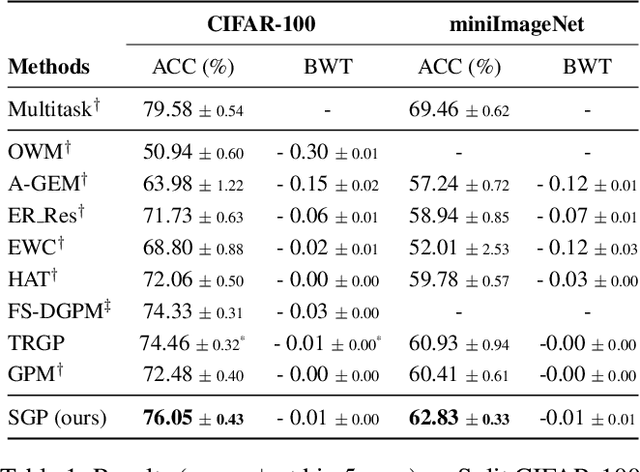
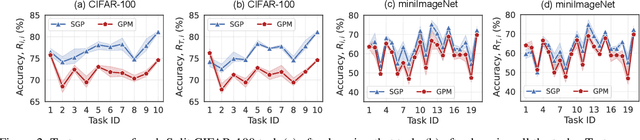

In neural networks, continual learning results in gradient interference among sequential tasks, leading to catastrophic forgetting of old tasks while learning new ones. This issue is addressed in recent methods by storing the important gradient spaces for old tasks and updating the model orthogonally during new tasks. However, such restrictive orthogonal gradient updates hamper the learning capability of the new tasks resulting in sub-optimal performance. To improve new learning while minimizing forgetting, in this paper we propose a Scaled Gradient Projection (SGP) method, where we combine the orthogonal gradient projections with scaled gradient steps along the important gradient spaces for the past tasks. The degree of gradient scaling along these spaces depends on the importance of the bases spanning them. We propose an efficient method for computing and accumulating importance of these bases using the singular value decomposition of the input representations for each task. We conduct extensive experiments ranging from continual image classification to reinforcement learning tasks and report better performance with less training overhead than the state-of-the-art approaches.
* Accepted at AAAI 2023
Synthetic Dataset Generation for Privacy-Preserving Machine Learning
Oct 10, 2022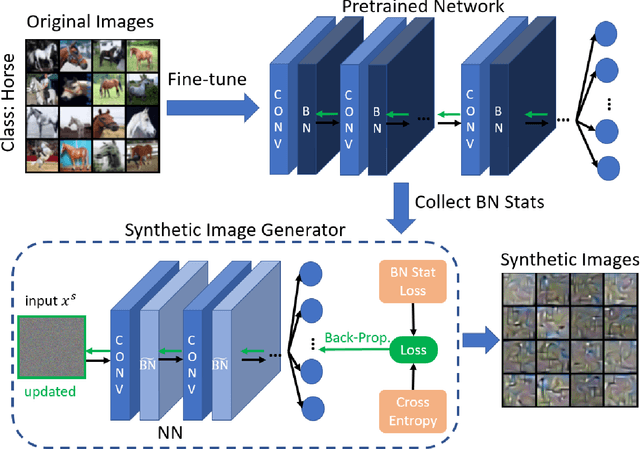



Machine Learning (ML) has achieved enormous success in solving a variety of problems in computer vision, speech recognition, object detection, to name a few. The principal reason for this success is the availability of huge datasets for training deep neural networks (DNNs). However, datasets cannot be publicly released if they contain sensitive information such as medical records, and data privacy becomes a major concern. Encryption methods could be a possible solution, however their deployment on ML applications seriously impacts classification accuracy and results in substantial computational overhead. Alternatively, obfuscation techniques could be used, but maintaining a good trade-off between visual privacy and accuracy is challenging. In this paper, we propose a method to generate secure synthetic datasets from the original private datasets. Given a network with Batch Normalization (BN) layers pretrained on the original dataset, we first record the class-wise BN layer statistics. Next, we generate the synthetic dataset by optimizing random noise such that the synthetic data match the layer-wise statistical distribution of original images. We evaluate our method on image classification datasets (CIFAR10, ImageNet) and show that synthetic data can be used in place of the original CIFAR10/ImageNet data for training networks from scratch, producing comparable classification performance. Further, to analyze visual privacy provided by our method, we use Image Quality Metrics and show high degree of visual dissimilarity between the original and synthetic images. Moreover, we show that our proposed method preserves data-privacy under various privacy-leakage attacks including Gradient Matching Attack, Model Memorization Attack, and GAN-based Attack.
Saliency Guided Experience Packing for Replay in Continual Learning
Sep 10, 2021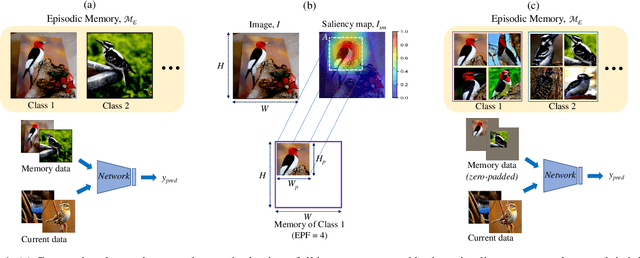
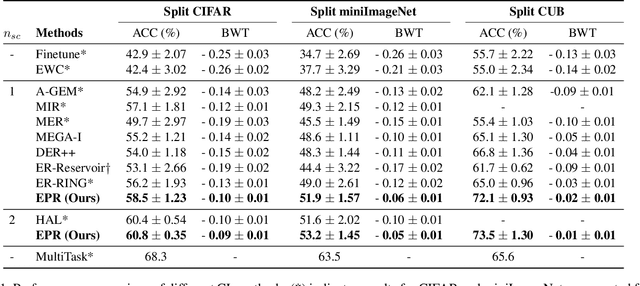
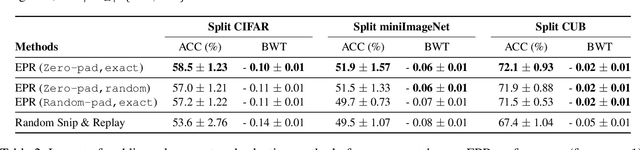

Artificial learning systems aspire to mimic human intelligence by continually learning from a stream of tasks without forgetting past knowledge. One way to enable such learning is to store past experiences in the form of input examples in episodic memory and replay them when learning new tasks. However, performance of such method suffers as the size of the memory becomes smaller. In this paper, we propose a new approach for experience replay, where we select the past experiences by looking at the saliency maps which provide visual explanations for the model's decision. Guided by these saliency maps, we pack the memory with only the parts or patches of the input images important for the model's prediction. While learning a new task, we replay these memory patches with appropriate zero-padding to remind the model about its past decisions. We evaluate our algorithm on diverse image classification datasets and report better performance than the state-of-the-art approaches. With qualitative and quantitative analyses we show that our method captures richer summary of past experiences without any memory increase, and hence performs well with small episodic memory.
Gradient Projection Memory for Continual Learning
Mar 17, 2021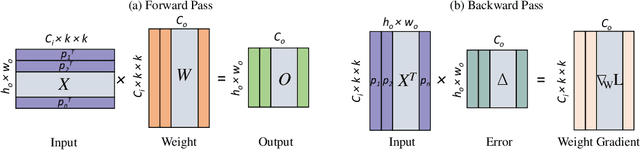
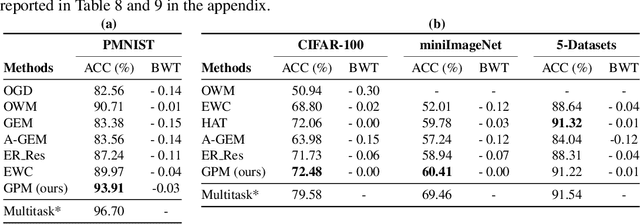
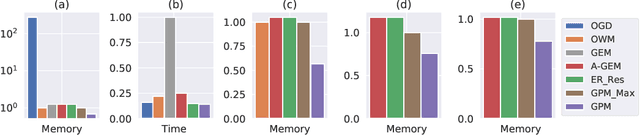
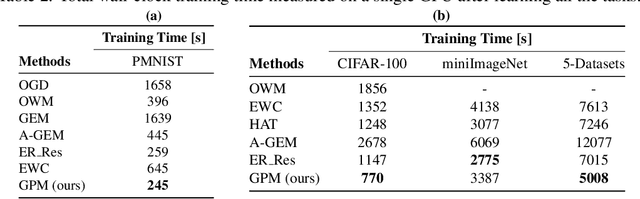
The ability to learn continually without forgetting the past tasks is a desired attribute for artificial learning systems. Existing approaches to enable such learning in artificial neural networks usually rely on network growth, importance based weight update or replay of old data from the memory. In contrast, we propose a novel approach where a neural network learns new tasks by taking gradient steps in the orthogonal direction to the gradient subspaces deemed important for the past tasks. We find the bases of these subspaces by analyzing network representations (activations) after learning each task with Singular Value Decomposition (SVD) in a single shot manner and store them in the memory as Gradient Projection Memory (GPM). With qualitative and quantitative analyses, we show that such orthogonal gradient descent induces minimum to no interference with the past tasks, thereby mitigates forgetting. We evaluate our algorithm on diverse image classification datasets with short and long sequences of tasks and report better or on-par performance compared to the state-of-the-art approaches.
* Accepted for Oral Presentation at ICLR 2021 https://openreview.net/forum?id=3AOj0RCNC2