 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning with Scaled Gradient Projection
Paper and Code
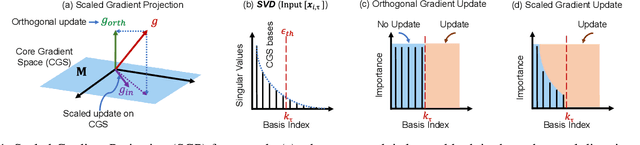
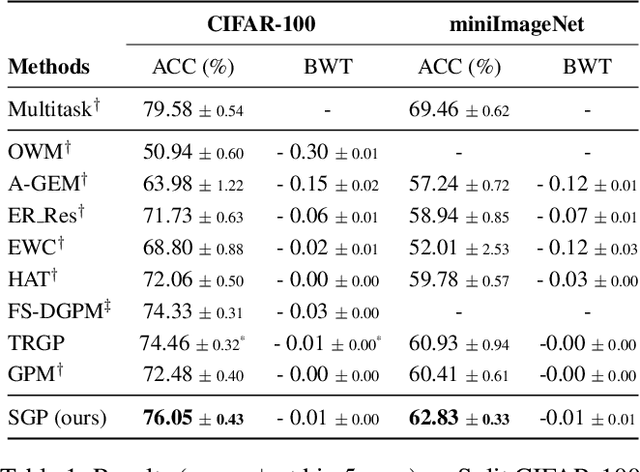
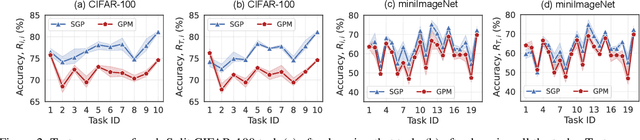

In neural networks, continual learning results in gradient interference among sequential tasks, leading to catastrophic forgetting of old tasks while learning new ones. This issue is addressed in recent methods by storing the important gradient spaces for old tasks and updating the model orthogonally during new tasks. However, such restrictive orthogonal gradient updates hamper the learning capability of the new tasks resulting in sub-optimal performance. To improve new learning while minimizing forgetting, in this paper we propose a Scaled Gradient Projection (SGP) method, where we combine the orthogonal gradient projections with scaled gradient steps along the important gradient spaces for the past tasks. The degree of gradient scaling along these spaces depends on the importance of the bases spanning them. We propose an efficient method for computing and accumulating importance of these bases using the singular value decomposition of the input representations for each task. We conduct extensive experiments ranging from continual image classification to reinforcement learning tasks and report better performance with less training overhead than the state-of-the-art approaches.