 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-feature Contrastive Loss for Decentralized Deep Learning on Heterogeneous Data
Paper and Code



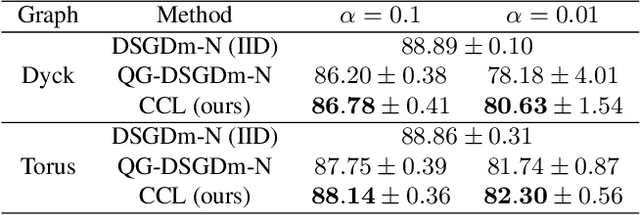
The current state-of-the-art decentralized learning algorithms mostly assume the data distribution to be Independent and Identically Distributed (IID). However, in practical scenarios, the distributed datasets can have significantly heterogeneous data distributions across the agents. In this work, we present a novel approach for decentralized learning on heterogeneous data, where data-free knowledge distillation through contrastive loss on cross-features is utilized to improve performance. Cross-features for a pair of neighboring agents are the features (i.e., last hidden layer activations) obtained from the data of an agent with respect to the model parameters of the other agent. We demonstrate the effectiveness of the proposed technique through an exhaustive set of experiments on various Computer Vision datasets (CIFAR-10, CIFAR-100, Fashion MNIST, Imagenette, and ImageNet), model architectures, and network topologies. Our experiments show that the proposed method achieves superior performance (0.2-4% improvement in test accuracy) compared to other existing techniques for decentralized learning on heterogeneous data.