 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Inherent Adversarial Robustness of Active Vision Systems
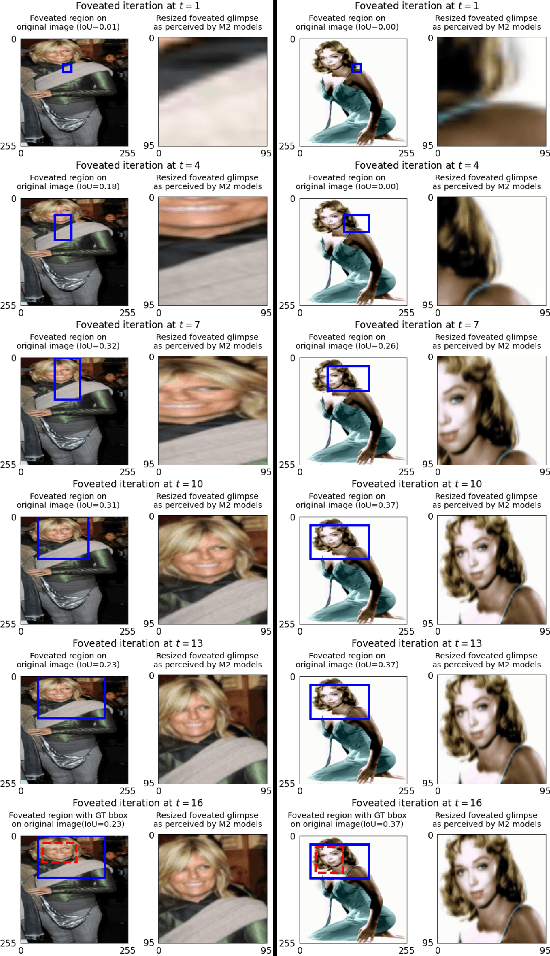
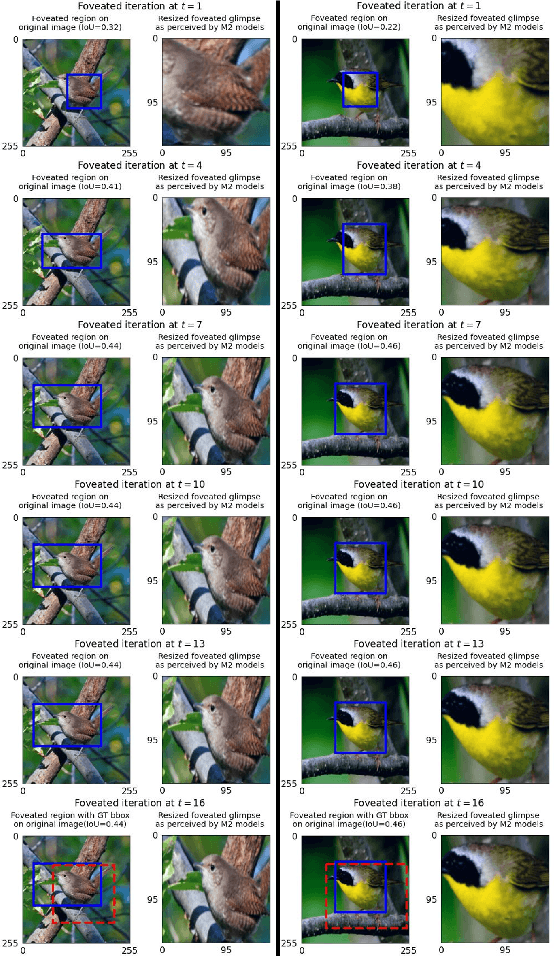
Apr 05, 2024Current Deep Neural Networks are vulnerable to adversarial examples, which alter their predictions by adding carefully crafted noise. Since human eyes are robust to such inputs, it is possible that the vulnerability stems from the standard way of processing inputs in one shot by processing every pixel with the same importance. In contrast, neuroscience suggests that the human vision system can differentiate salient features by (1) switching between multiple fixation points (saccades) and (2) processing the surrounding with a non-uniform external resolution (foveation). In this work, we advocate that the integration of such active vision mechanisms into current deep learning systems can offer robustness benefits. Specifically, we empirically demonstrate the inherent robustness of two active vision methods - GFNet and FALcon - under a black box threat model. By learning and inferencing based on downsampled glimpses obtained from multiple distinct fixation points within an input, we show that these active methods achieve (2-3) times greater robustness compared to a standard passive convolutional network under state-of-the-art adversarial attacks. More importantly, we provide illustrative and interpretable visualization analysis that demonstrates how performing inference from distinct fixation points makes active vision methods less vulnerable to malicious inputs.
Towards Two-Stream Foveation-based Active Vision Learning
Mar 24, 2024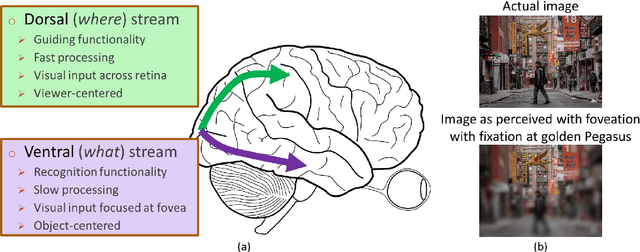

Deep neural network (DNN) based machine perception frameworks process the entire input in a one-shot manner to provide answers to both "what object is being observed" and "where it is located". In contrast, the "two-stream hypothesis" from neuroscience explains the neural processing in the human visual cortex as an active vision system that utilizes two separate regions of the brain to answer the what and the where questions. In this work, we propose a machine learning framework inspired by the "two-stream hypothesis" and explore the potential benefits that it offers. Specifically, the proposed framework models the following mechanisms: 1) ventral (what) stream focusing on the input regions perceived by the fovea part of an eye (foveation), 2) dorsal (where) stream providing visual guidance, and 3) iterative processing of the two streams to calibrate visual focus and process the sequence of focused image patches. The training of the proposed framework is accomplished by label-based DNN training for the ventral stream model and reinforcement learning for the dorsal stream model. We show that the two-stream foveation-based learning is applicable to the challenging task of weakly-supervised object localization (WSOL), where the training data is limited to the object class or its attributes. The framework is capable of both predicting the properties of an object and successfully localizing it by predicting its bounding box. We also show that, due to the independent nature of the two streams, the dorsal model can be applied on its own to unseen images to localize objects from different datasets.
Encoding Hierarchical Information in Neural Networks helps in Subpopulation Shift
Dec 20, 2021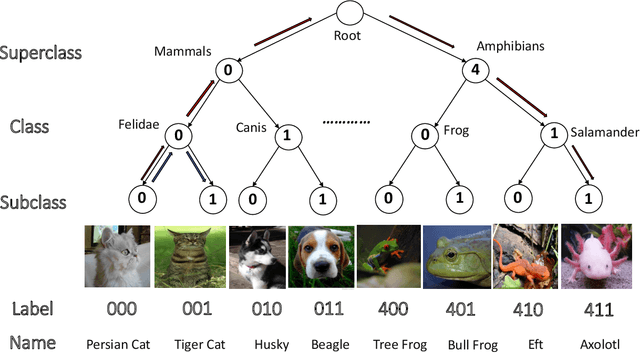
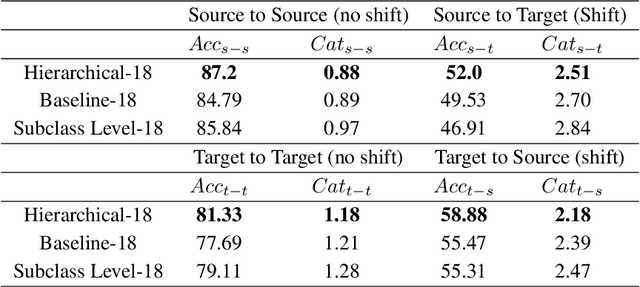
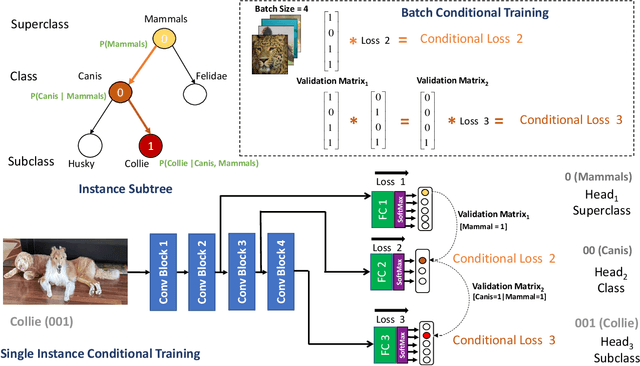
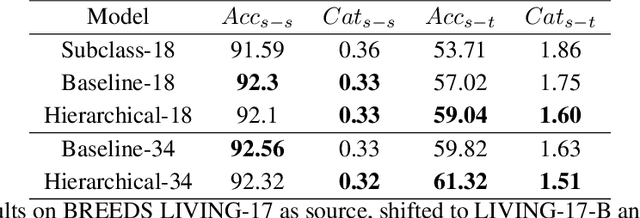
Over the past decade, deep neural networks have proven to be adept in image classification tasks, often surpassing humans in terms of accuracy. However, standard neural networks often fail to understand the concept of hierarchical structures and dependencies among different classes for vision related tasks. Humans on the other hand, seem to learn categories conceptually, progressively growing from understanding high-level concepts down to granular levels of categories. One of the issues arising from the inability of neural networks to encode such dependencies within its learned structure is that of subpopulation shift -- where models are queried with novel unseen classes taken from a shifted population of the training set categories. Since the neural network treats each class as independent from all others, it struggles to categorize shifting populations that are dependent at higher levels of the hierarchy. In this work, we study the aforementioned problems through the lens of a novel conditional supervised training framework. We tackle subpopulation shift by a structured learning procedure that incorporates hierarchical information conditionally through labels. Furthermore, we introduce a notion of graphical distance to model the catastrophic effect of mispredictions. We show that learning in this structured hierarchical manner results in networks that are more robust against subpopulation shifts, with an improvement of around ~2% in terms of accuracy and around 8.5\% in terms of graphical distance over standard models on subpopulation shift benchmarks.
Semantic Adversarial Attacks: Parametric Transformations That Fool Deep Classifiers
Apr 17, 2019
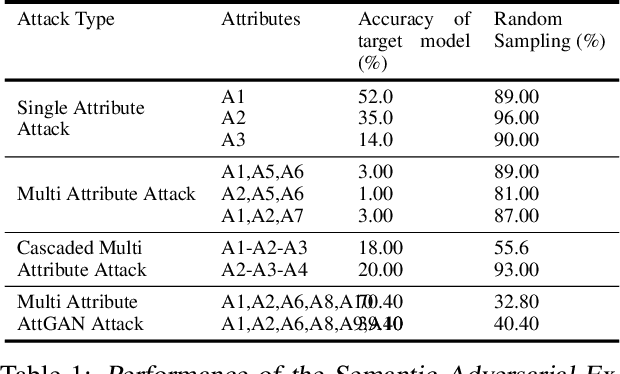
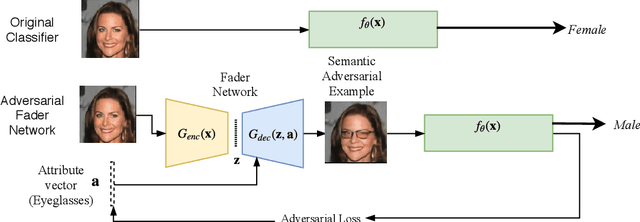

Deep neural networks have been shown to exhibit an intriguing vulnerability to adversarial input images corrupted with imperceptible perturbations. However, the majority of adversarial attacks assume global, fine-grained control over the image pixel space. In this paper, we consider a different setting: what happens if the adversary could only alter specific attributes of the input image? These would generate inputs that might be perceptibly different, but still natural-looking and enough to fool a classifier. We propose a novel approach to generate such `semantic' adversarial examples by optimizing a particular adversarial loss over the range-space of a parametric conditional generative model. We demonstrate implementations of our attacks on binary classifiers trained on face images, and show that such natural-looking semantic adversarial examples exist. We evaluate the effectiveness of our attack on synthetic and real data, and present detailed comparisons with existing attack methods. We supplement our empirical results with theoretical bounds that demonstrate the existence of such parametric adversarial examples.