 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Inherent Adversarial Robustness of Active Vision Systems
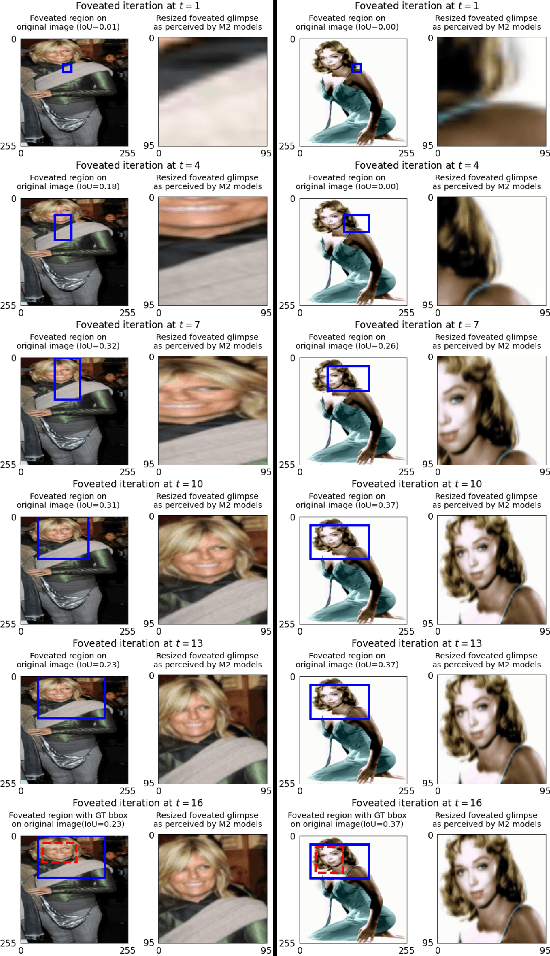
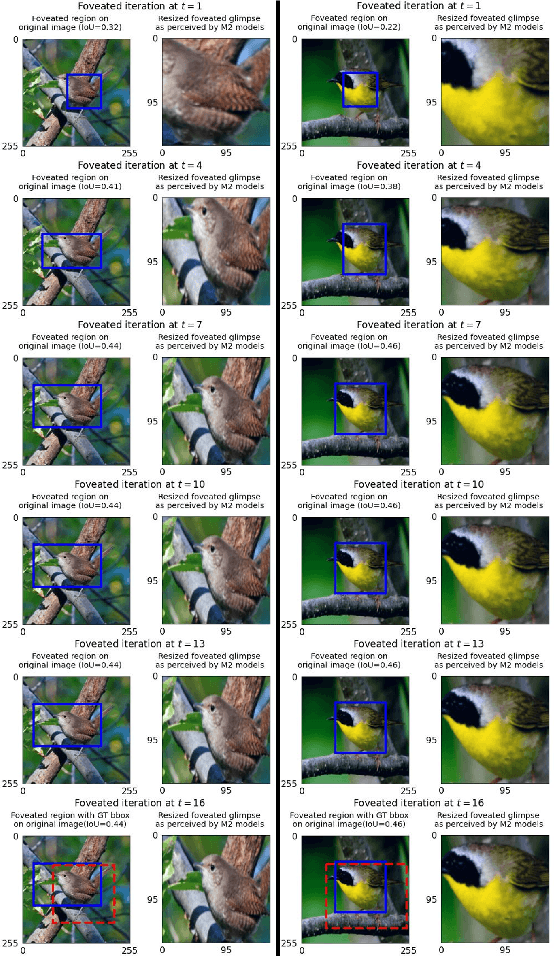
Apr 05, 2024Current Deep Neural Networks are vulnerable to adversarial examples, which alter their predictions by adding carefully crafted noise. Since human eyes are robust to such inputs, it is possible that the vulnerability stems from the standard way of processing inputs in one shot by processing every pixel with the same importance. In contrast, neuroscience suggests that the human vision system can differentiate salient features by (1) switching between multiple fixation points (saccades) and (2) processing the surrounding with a non-uniform external resolution (foveation). In this work, we advocate that the integration of such active vision mechanisms into current deep learning systems can offer robustness benefits. Specifically, we empirically demonstrate the inherent robustness of two active vision methods - GFNet and FALcon - under a black box threat model. By learning and inferencing based on downsampled glimpses obtained from multiple distinct fixation points within an input, we show that these active methods achieve (2-3) times greater robustness compared to a standard passive convolutional network under state-of-the-art adversarial attacks. More importantly, we provide illustrative and interpretable visualization analysis that demonstrates how performing inference from distinct fixation points makes active vision methods less vulnerable to malicious inputs.
Towards Two-Stream Foveation-based Active Vision Learning
Mar 24, 2024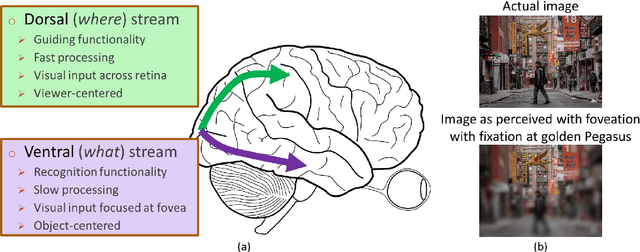

Deep neural network (DNN) based machine perception frameworks process the entire input in a one-shot manner to provide answers to both "what object is being observed" and "where it is located". In contrast, the "two-stream hypothesis" from neuroscience explains the neural processing in the human visual cortex as an active vision system that utilizes two separate regions of the brain to answer the what and the where questions. In this work, we propose a machine learning framework inspired by the "two-stream hypothesis" and explore the potential benefits that it offers. Specifically, the proposed framework models the following mechanisms: 1) ventral (what) stream focusing on the input regions perceived by the fovea part of an eye (foveation), 2) dorsal (where) stream providing visual guidance, and 3) iterative processing of the two streams to calibrate visual focus and process the sequence of focused image patches. The training of the proposed framework is accomplished by label-based DNN training for the ventral stream model and reinforcement learning for the dorsal stream model. We show that the two-stream foveation-based learning is applicable to the challenging task of weakly-supervised object localization (WSOL), where the training data is limited to the object class or its attributes. The framework is capable of both predicting the properties of an object and successfully localizing it by predicting its bounding box. We also show that, due to the independent nature of the two streams, the dorsal model can be applied on its own to unseen images to localize objects from different datasets.
Pruning for Improved ADC Efficiency in Crossbar-based Analog In-memory Accelerators
Mar 19, 2024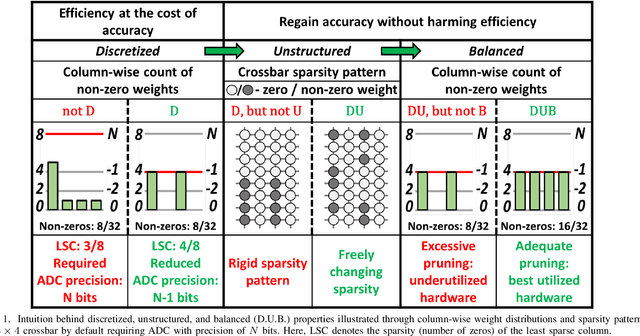
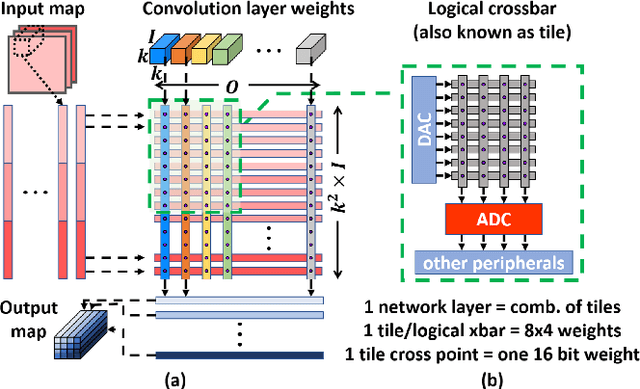
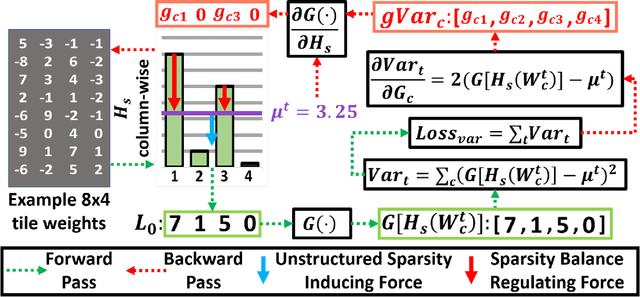
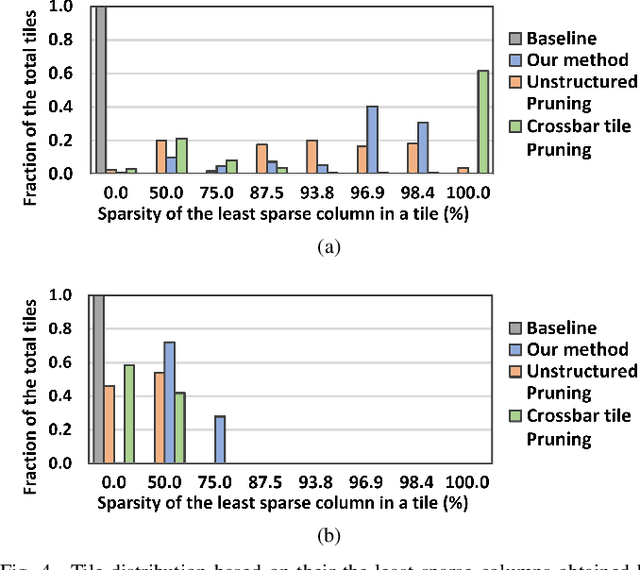
Deep learning has proved successful in many applications but suffers from high computational demands and requires custom accelerators for deployment. Crossbar-based analog in-memory architectures are attractive for acceleration of deep neural networks (DNN), due to their high data reuse and high efficiency enabled by combining storage and computation in memory. However, they require analog-to-digital converters (ADCs) to communicate crossbar outputs. ADCs consume a significant portion of energy and area of every crossbar processing unit, thus diminishing the potential efficiency benefits. Pruning is a well-studied technique to improve the efficiency of DNNs but requires modifications to be effective for crossbars. In this paper, we motivate crossbar-attuned pruning to target ADC-specific inefficiencies. This is achieved by identifying three key properties (dubbed D.U.B.) that induce sparsity that can be utilized to reduce ADC energy without sacrificing accuracy. The first property ensures that sparsity translates effectively to hardware efficiency by restricting sparsity levels to Discrete powers of 2. The other 2 properties encourage columns in the same crossbar to achieve both Unstructured and Balanced sparsity in order to amortize the accuracy drop. The desired D.U.B. sparsity is then achieved by regularizing the variance of $L_{0}$ norms of neighboring columns within the same crossbar. Our proposed implementation allows it to be directly used in end-to-end gradient-based training. We apply the proposed algorithm to convolutional layers of VGG11 and ResNet18 models, trained on CIFAR-10 and ImageNet datasets, and achieve up to 7.13x and 1.27x improvement, respectively, in ADC energy with less than 1% drop in accuracy.
Towards Image Semantics and Syntax Sequence Learning
Jan 31, 2024Convolutional neural networks and vision transformers have achieved outstanding performance in machine perception, particularly for image classification. Although these image classifiers excel at predicting image-level class labels, they may not discriminate missing or shifted parts within an object. As a result, they may fail to detect corrupted images that involve missing or disarrayed semantic information in the object composition. On the contrary, human perception easily distinguishes such corruptions. To mitigate this gap, we introduce the concept of "image grammar", consisting of "image semantics" and "image syntax", to denote the semantics of parts or patches of an image and the order in which these parts are arranged to create a meaningful object. To learn the image grammar relative to a class of visual objects/scenes, we propose a weakly supervised two-stage approach. In the first stage, we use a deep clustering framework that relies on iterative clustering and feature refinement to produce part-semantic segmentation. In the second stage, we incorporate a recurrent bi-LSTM module to process a sequence of semantic segmentation patches to capture the image syntax. Our framework is trained to reason over patch semantics and detect faulty syntax. We benchmark the performance of several grammar learning models in detecting patch corruptions. Finally, we verify the capabilities of our framework in Celeb and SUNRGBD datasets and demonstrate that it can achieve a grammar validation accuracy of 70 to 90% in a wide variety of semantic and syntactical corruption scenarios.
Robustness Hidden in Plain Sight: Can Analog Computing Defend Against Adversarial Attacks?
Aug 27, 2020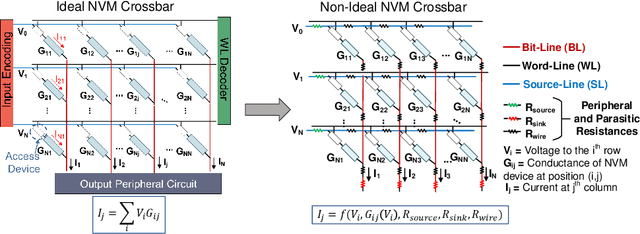
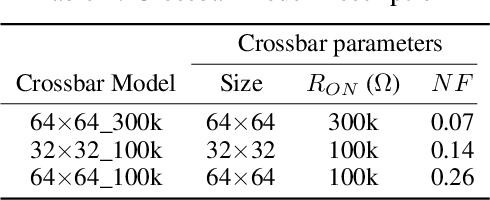
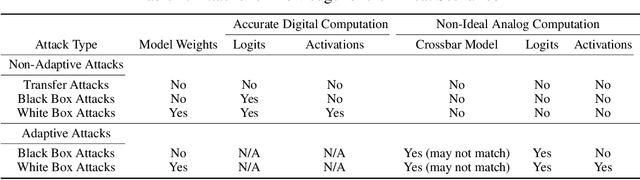
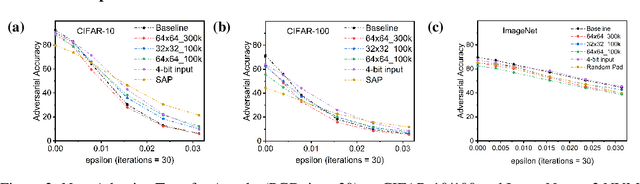
The ever-increasing computational demand of Deep Learning has propelled research in special-purpose inference accelerators based on emerging non-volatile memory (NVM) technologies. Such NVM crossbars promise fast and energy-efficient in-situ matrix vector multiplications (MVM) thus alleviating the long-standing von Neuman bottleneck in today's digital hardware. However the analog nature of computing in these NVM crossbars introduces approximations in the MVM operations. In this paper, we study the impact of these non-idealities on the performance of DNNs under adversarial attacks. The non-ideal behavior interferes with the computation of the exact gradient of the model, which is required for adversarial image generation. In a non-adaptive attack, where the attacker is unaware of the analog hardware, we show that analog computing offers a varying degree of intrinsic robustness, with a peak adversarial accuracy improvement of 35.34%, 22.69%, and 31.70% for white box PGD ($\epsilon$=1/255, iter=30) for CIFAR-10, CIFAR-100, and ImageNet(top-5) respectively. We also demonstrate "hardware-in-loop" adaptive attacks that circumvent this robustness by utilizing the knowledge of the NVM model. To the best of our knowledge, this is the first work that explores the non-idealities of analog computing for adversarial robustness at the time of submission to NeurIPS 2020.