 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Noise Stability and Robustness of Adversarially Trained Networks on NVM Crossbars
Sep 19, 2021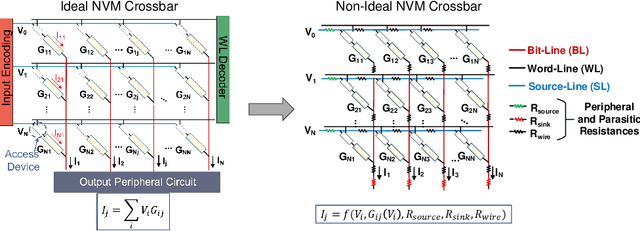
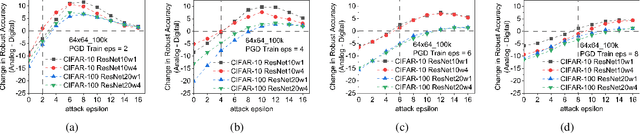
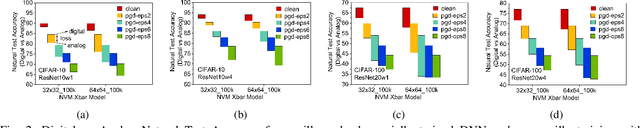
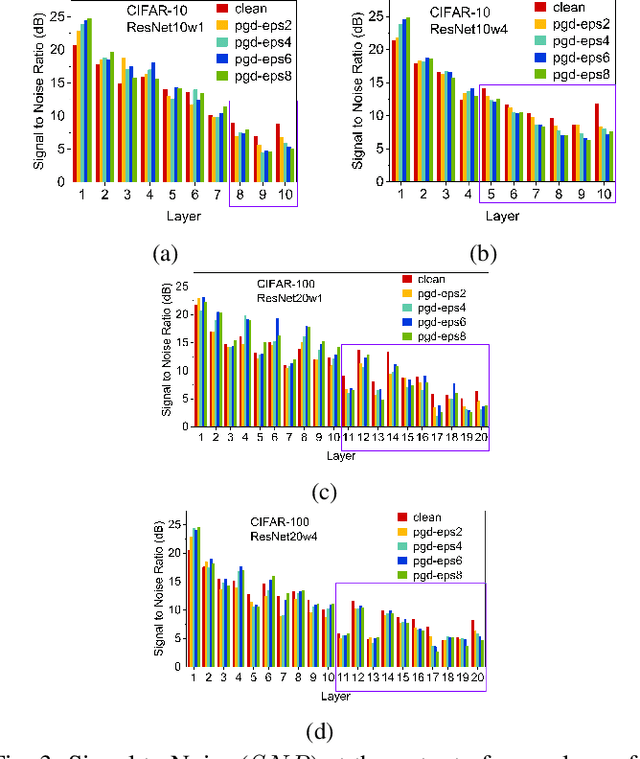
Applications based on Deep Neural Networks (DNNs) have grown exponentially in the past decade. To match their increasing computational needs, several Non-Volatile Memory (NVM) crossbar-based accelerators have been proposed. Apart from improved energy efficiency and performance, these approximate hardware also possess intrinsic robustness for defense against Adversarial Attacks, which is an important security concern for DNNs. Prior works have focused on quantifying this intrinsic robustness for vanilla networks, that is DNNs trained on unperturbed inputs. However, adversarial training of DNNs is the benchmark technique for robustness, and sole reliance on intrinsic robustness of the hardware may not be sufficient. In this work, we explore the design of robust DNNs through the amalgamation of adversarial training and the intrinsic robustness offered by NVM crossbar-based analog hardware. First, we study the noise stability of such networks on unperturbed inputs and observe that internal activations of adversarially trained networks have lower Signal-to-Noise Ratio (SNR), and are sensitive to noise than vanilla networks. As a result, they suffer significantly higher performance degradation due to the non-ideal computations; on an average 2x accuracy drop. On the other hand, for adversarial images generated using Projected-Gradient-Descent (PGD) White-Box attacks, ResNet-10/20 adversarially trained on CIFAR-10/100 display a 5-10% gain in robust accuracy due to the underlying NVM crossbar when the attack epsilon ($\epsilon_{attack}$, the degree of input perturbations) is greater than the epsilon of the adversarial training ($\epsilon_{train}$). Our results indicate that implementing adversarially trained networks on analog hardware requires careful calibration between hardware non-idealities and $\epsilon_{train}$ to achieve optimum robustness and performance.
Robustness Hidden in Plain Sight: Can Analog Computing Defend Against Adversarial Attacks?
Aug 27, 2020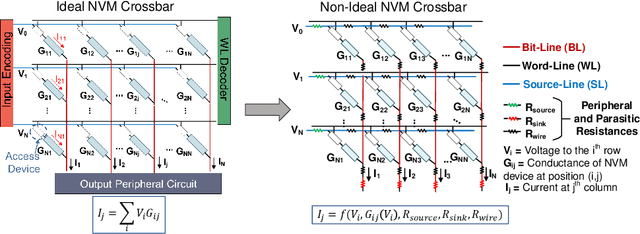
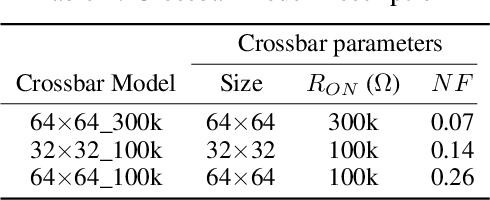
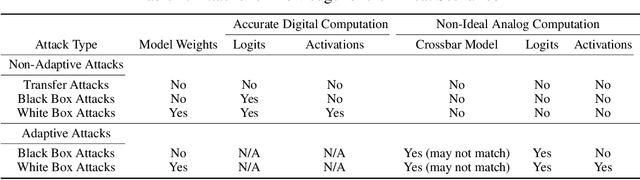
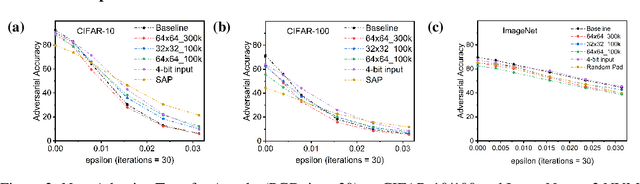
The ever-increasing computational demand of Deep Learning has propelled research in special-purpose inference accelerators based on emerging non-volatile memory (NVM) technologies. Such NVM crossbars promise fast and energy-efficient in-situ matrix vector multiplications (MVM) thus alleviating the long-standing von Neuman bottleneck in today's digital hardware. However the analog nature of computing in these NVM crossbars introduces approximations in the MVM operations. In this paper, we study the impact of these non-idealities on the performance of DNNs under adversarial attacks. The non-ideal behavior interferes with the computation of the exact gradient of the model, which is required for adversarial image generation. In a non-adaptive attack, where the attacker is unaware of the analog hardware, we show that analog computing offers a varying degree of intrinsic robustness, with a peak adversarial accuracy improvement of 35.34%, 22.69%, and 31.70% for white box PGD ($\epsilon$=1/255, iter=30) for CIFAR-10, CIFAR-100, and ImageNet(top-5) respectively. We also demonstrate "hardware-in-loop" adaptive attacks that circumvent this robustness by utilizing the knowledge of the NVM model. To the best of our knowledge, this is the first work that explores the non-idealities of analog computing for adversarial robustness at the time of submission to NeurIPS 2020.
PCA-driven Hybrid network design for enabling Intelligence at the Edge
Jun 04, 2019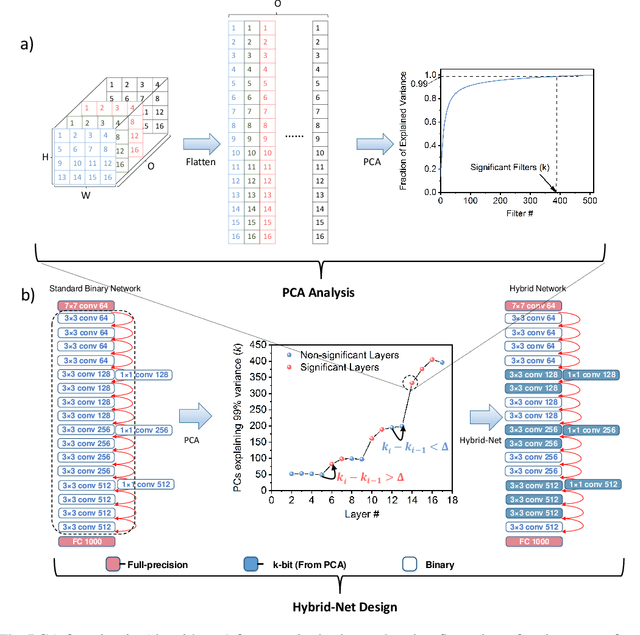

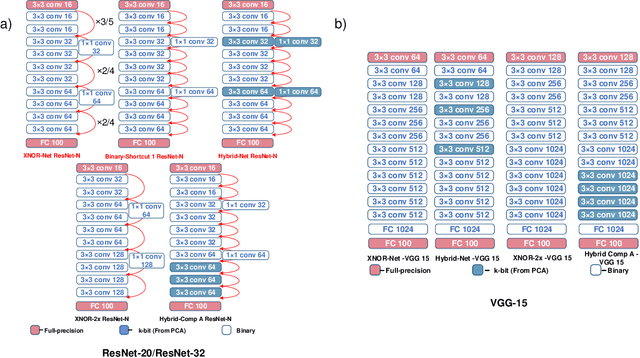
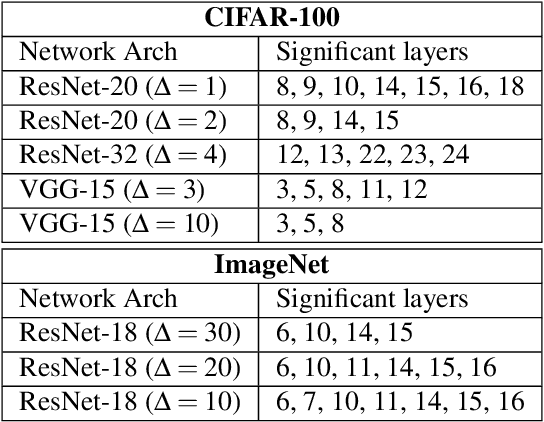
The recent advent of IOT has increased the demand for enabling AI-based edge computing in several applications including healthcare monitoring systems, autonomous vehicles etc. This has necessitated the search for efficient implementations of neural networks in terms of both computation and storage. Although extreme quantization has proven to be a powerful tool to achieve significant compression over full-precision networks, it can result in significant degradation in performance for complex image classification tasks. In this work, we propose a Principal Component Analysis (PCA) driven methodology to design mixed-precision, hybrid networks. Unlike standard practices of using PCA for dimensionality reduction, we leverage PCA to identify significant layers in a binary network which contribute relevant transformations on the input data by increasing the number of significant dimensions. Subsequently, we propose Hybrid-Net, a network with increased bit-precision of the weights and activations of the significant layers in a binary network. We show that the proposed Hybrid-Net achieves over 10% improvement in classification accuracy over binary networks such as XNOR-Net for ResNet and VGG architectures on CIFAR-100 and ImageNet datasets while still achieving upto 94% of the energy-efficiency of XNOR-Nets. The proposed design methodology allows us to move closer to the accuracy of standard full-precision networks by keeping more than half of the network binary. This work demonstrates an effective, one-shot methodology for designing hybrid, mixed-precision networks which significantly improve the classification performance of binary networks while attaining remarkable compression. The proposed hybrid networks further the feasibility of using highly compressed neural networks for energy-efficient neural computing in IOT-based edge devices.
Efficient Hybrid Network Architectures for Extremely Quantized Neural Networks Enabling Intelligence at the Edge
Feb 01, 2019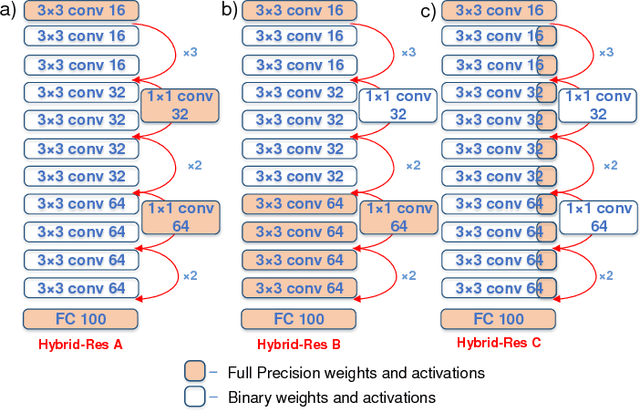

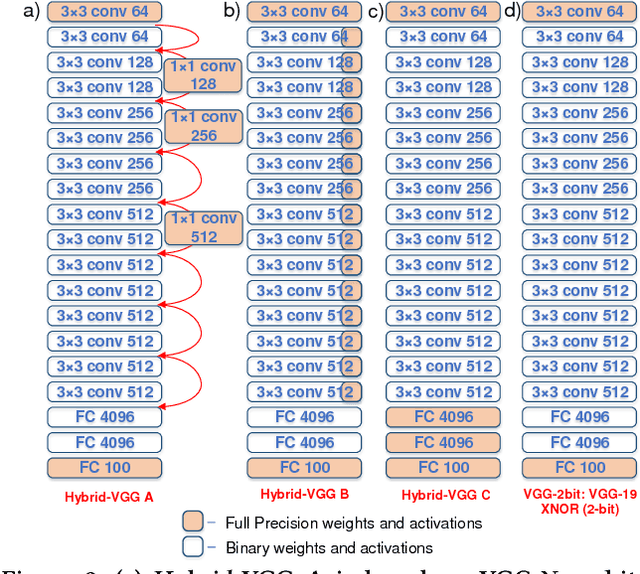
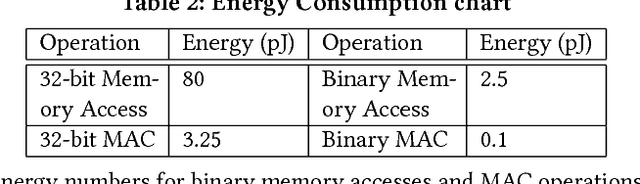
The recent advent of `Internet of Things' (IOT) has increased the demand for enabling AI-based edge computing. This has necessitated the search for efficient implementations of neural networks in terms of both computations and storage. Although extreme quantization has proven to be a powerful tool to achieve significant compression over full-precision networks, it can result in significant degradation in performance. In this work, we propose extremely quantized hybrid network architectures with both binary and full-precision sections to emulate the classification performance of full-precision networks while ensuring significant energy efficiency and memory compression. We explore several hybrid network architectures and analyze the performance of the networks in terms of accuracy, energy efficiency and memory compression. We perform our analysis on ResNet and VGG network architectures. Among the proposed network architectures, we show that the hybrid networks with full-precision residual connections emerge as the optimum by attaining accuracies close to full-precision networks while achieving excellent memory compression, up to 21.8x in case of VGG-19. This work demonstrates an effective way of hybridizing networks which achieve performance close to full-precision networks while attaining significant compression, furthering the feasibility of using such networks for energy-efficient neural computing in IOT-based edge devices.
Tree-CNN: A Hierarchical Deep Convolutional Neural Network for Incremental Learning
May 23, 2018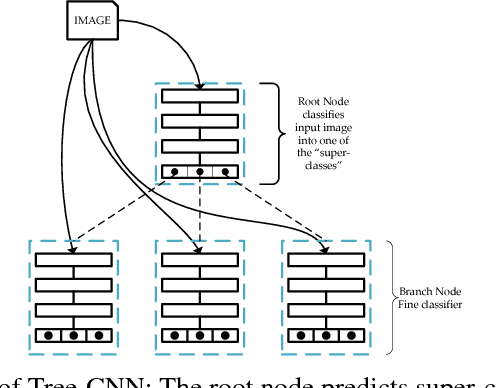
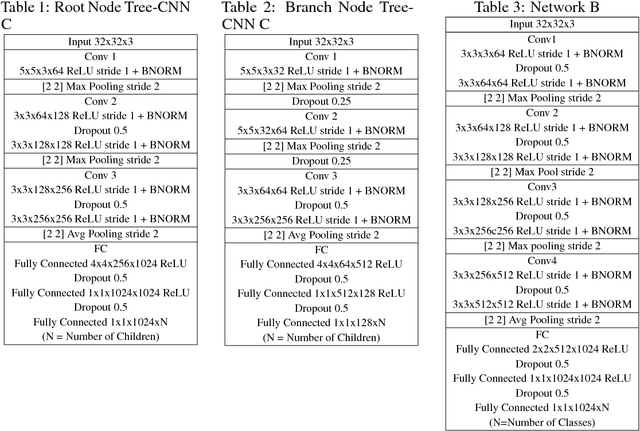
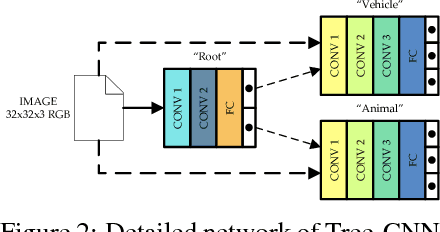

In recent years, Convolutional Neural Networks (CNNs) have shown remarkable performance in many computer vision tasks such as object recognition and detection. However, complex training issues, such as `catastrophic forgetting' and hyper-parameter tuning, make incremental learning in CNNs a difficult challenge. In this paper, we propose a hierarchical deep neural network, with CNNs at multiple levels, and a corresponding training method for incremental learning. The network grows in a tree-like manner to accommodate the new classes of data without losing the ability to identify the previously trained classes. The proposed network was tested on CIFAR-100 and reported 60.46% accuracy and 20% reduction in training effort as compared to retraining final layers of a deep network. The network organizes the incoming classes of data into feature-driven super-classes and improves upon existing hierarchical CNN models by adding the capability of self-growth.