 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fine-Tuning Trap: Evaluating Negative Transfer and the Role of PEFT in Sub-1B Mathematical Reasoning
Jun 05, 2026Deploying Small Language Models (SLMs) on edge devices requires efficient fine-tuning strategies that adapt models to new tasks without degrading their general capabilities. In this study, we benchmark five sub-1B models (135M-1B) on mathematical reasoning tasks and uncover a critical vulnerability: Full Fine-Tuning (Full FT) actively harms performance in models under 300M parameters, often dropping accuracy below zero-shot baselines. This "negative transfer" makes Parameter-Efficient Fine-Tuning (PEFT) not just an efficiency preference, but a stability requirement. We find that while Low-Rank Adaptation (LoRA) and Weight-Decomposed LoRA (DoRA) perform comparably, their strengths vary by task; DoRA excels in complex reasoning (GSM8K), while LoRA dominates pattern matching (OrcaMath). In particular, Full FT is outperformed by LoRA on aligned models (Qwen2.5-0.5B) and even by simple 5-shot In-Context Learning on the smallest architectures (SmolLM2-135M). Based on these findings, we recommend defaulting to PEFT for all aligned sub-1B models and caution against Full FT for any architecture smaller than 500M parameters to prevent catastrophic forgetting. Reproduction of this work can be found at https://github.com/gulguluu/tiny-slm-finetune-compare.
Towards Image Semantics and Syntax Sequence Learning
Jan 31, 2024Convolutional neural networks and vision transformers have achieved outstanding performance in machine perception, particularly for image classification. Although these image classifiers excel at predicting image-level class labels, they may not discriminate missing or shifted parts within an object. As a result, they may fail to detect corrupted images that involve missing or disarrayed semantic information in the object composition. On the contrary, human perception easily distinguishes such corruptions. To mitigate this gap, we introduce the concept of "image grammar", consisting of "image semantics" and "image syntax", to denote the semantics of parts or patches of an image and the order in which these parts are arranged to create a meaningful object. To learn the image grammar relative to a class of visual objects/scenes, we propose a weakly supervised two-stage approach. In the first stage, we use a deep clustering framework that relies on iterative clustering and feature refinement to produce part-semantic segmentation. In the second stage, we incorporate a recurrent bi-LSTM module to process a sequence of semantic segmentation patches to capture the image syntax. Our framework is trained to reason over patch semantics and detect faulty syntax. We benchmark the performance of several grammar learning models in detecting patch corruptions. Finally, we verify the capabilities of our framework in Celeb and SUNRGBD datasets and demonstrate that it can achieve a grammar validation accuracy of 70 to 90% in a wide variety of semantic and syntactical corruption scenarios.
On the Noise Stability and Robustness of Adversarially Trained Networks on NVM Crossbars
Sep 19, 2021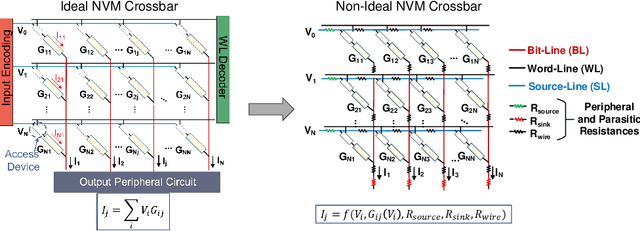
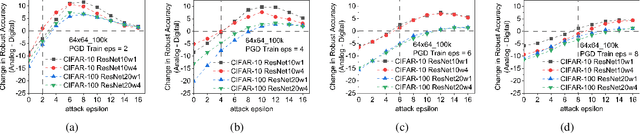
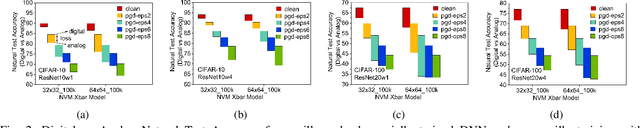
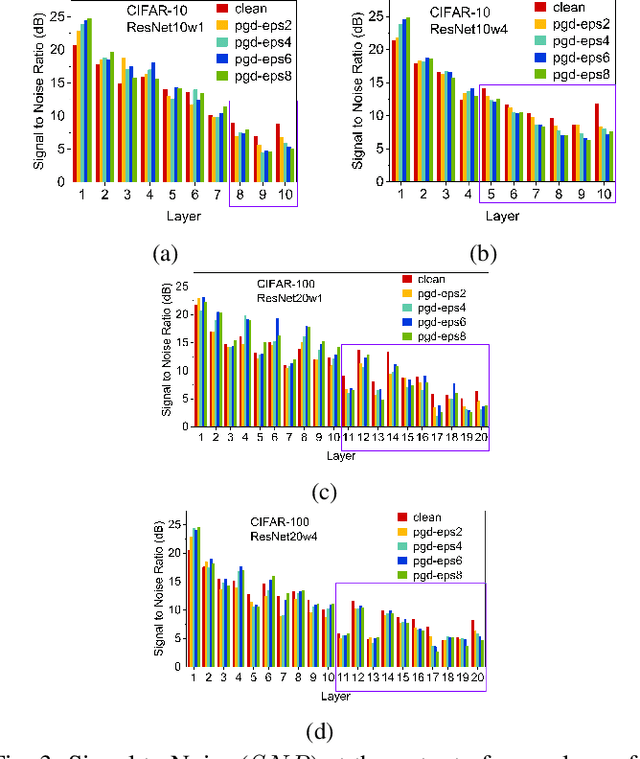
Applications based on Deep Neural Networks (DNNs) have grown exponentially in the past decade. To match their increasing computational needs, several Non-Volatile Memory (NVM) crossbar-based accelerators have been proposed. Apart from improved energy efficiency and performance, these approximate hardware also possess intrinsic robustness for defense against Adversarial Attacks, which is an important security concern for DNNs. Prior works have focused on quantifying this intrinsic robustness for vanilla networks, that is DNNs trained on unperturbed inputs. However, adversarial training of DNNs is the benchmark technique for robustness, and sole reliance on intrinsic robustness of the hardware may not be sufficient. In this work, we explore the design of robust DNNs through the amalgamation of adversarial training and the intrinsic robustness offered by NVM crossbar-based analog hardware. First, we study the noise stability of such networks on unperturbed inputs and observe that internal activations of adversarially trained networks have lower Signal-to-Noise Ratio (SNR), and are sensitive to noise than vanilla networks. As a result, they suffer significantly higher performance degradation due to the non-ideal computations; on an average 2x accuracy drop. On the other hand, for adversarial images generated using Projected-Gradient-Descent (PGD) White-Box attacks, ResNet-10/20 adversarially trained on CIFAR-10/100 display a 5-10% gain in robust accuracy due to the underlying NVM crossbar when the attack epsilon ($\epsilon_{attack}$, the degree of input perturbations) is greater than the epsilon of the adversarial training ($\epsilon_{train}$). Our results indicate that implementing adversarially trained networks on analog hardware requires careful calibration between hardware non-idealities and $\epsilon_{train}$ to achieve optimum robustness and performance.