 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERMo: What can BERT learn from ELMo?
Paper and Code
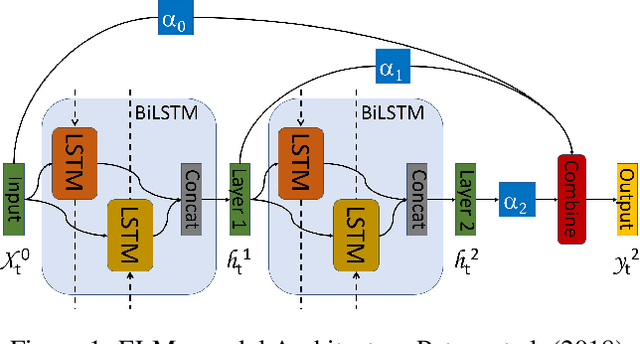

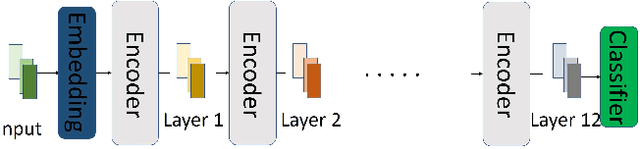

We propose BERMo, an architectural modification to BERT, which makes predictions based on a hierarchy of surface, syntactic and semantic language features. We use linear combination scheme proposed in Embeddings from Language Models (ELMo) to combine the scaled internal representations from different network depths. Our approach has two-fold benefits: (1) improved gradient flow for the downstream task as every layer has a direct connection to the gradients of the loss function and (2) increased representative power as the model no longer needs to copy the features learned in the shallower layer which are necessary for the downstream task. Further, our model has a negligible parameter overhead as there is a single scalar parameter associated with each layer in the network. Experiments on the probing task from SentEval dataset show that our model performs up to $4.65\%$ better in accuracy than the baseline with an average improvement of $2.67\%$ on the semantic tasks. When subject to compression techniques, we find that our model enables stable pruning for compressing small datasets like SST-2, where the BERT model commonly diverges. We observe that our approach converges $1.67\times$ and $1.15\times$ faster than the baseline on MNLI and QQP tasks from GLUE dataset. Moreover, our results show that our approach can obtain better parameter efficiency for penalty based pruning approaches on QQP task.