 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWWW: What, When, Where to Compute-in-Memory
Dec 26, 2023



Compute-in-memory (CiM) has emerged as a compelling solution to alleviate high data movement costs in von Neumann machines. CiM can perform massively parallel general matrix multiplication (GEMM) operations in memory, the dominant computation in Machine Learning (ML) inference. However, re-purposing memory for compute poses key questions on 1) What type of CiM to use: Given a multitude of analog and digital CiMs, determining their suitability from systems perspective is needed. 2) When to use CiM: ML inference includes workloads with a variety of memory and compute requirements, making it difficult to identify when CiM is more beneficial than standard processing cores. 3) Where to integrate CiM: Each memory level has different bandwidth and capacity, that affects the data movement and locality benefits of CiM integration. In this paper, we explore answers to these questions regarding CiM integration for ML inference acceleration. We use Timeloop-Accelergy for early system-level evaluation of CiM prototypes, including both analog and digital primitives. We integrate CiM into different cache memory levels in an Nvidia A100-like baseline architecture and tailor the dataflow for various ML workloads. Our experiments show CiM architectures improve energy efficiency, achieving up to 0.12x lower energy than the established baseline with INT-8 precision, and upto 4x performance gains with weight interleaving and duplication. The proposed work provides insights into what type of CiM to use, and when and where to optimally integrate it in the cache hierarchy for GEMM acceleration.
PIM-DRAM: Accelerating Machine Learning Workloads using Processing in Commodity DRAM
May 14, 2021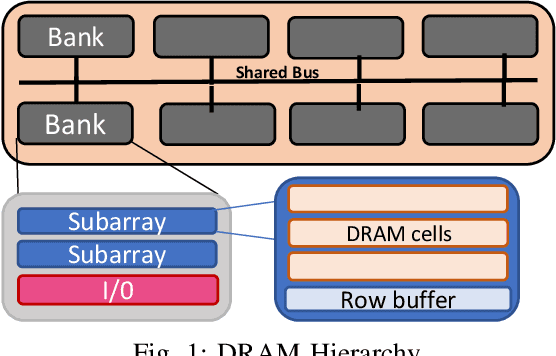
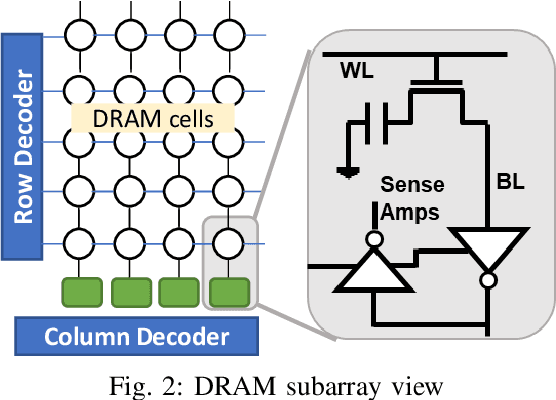
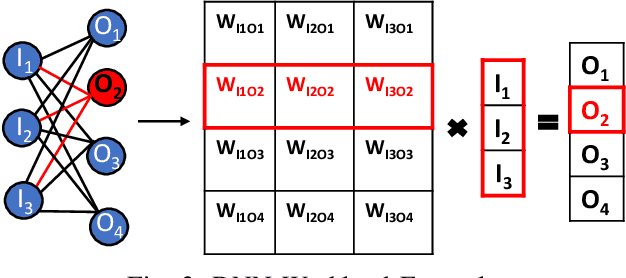
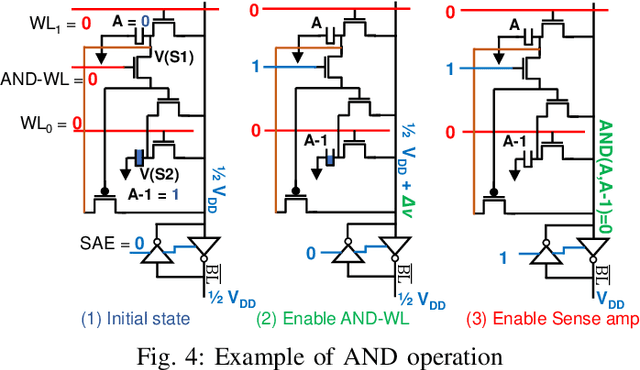
Deep Neural Networks (DNNs) have transformed the field of machine learning and are widely deployed in many applications involving image, video, speech and natural language processing. The increasing compute demands of DNNs have been widely addressed through Graphics Processing Units (GPUs) and specialized accelerators. However, as model sizes grow, these von Neumann architectures require very high memory bandwidth to keep the processing elements utilized as a majority of the data resides in the main memory. Processing in memory has been proposed as a promising solution for the memory wall bottleneck for ML workloads. In this work, we propose a new DRAM-based processing-in-memory (PIM) multiplication primitive coupled with intra-bank accumulation to accelerate matrix vector operations in ML workloads. The proposed multiplication primitive adds < 1% area overhead and does not require any change in the DRAM peripherals. Therefore, the proposed multiplication can be easily adopted in commodity DRAM chips. Subsequently, we design a DRAM-based PIM architecture, data mapping scheme and dataflow for executing DNNs within DRAM. System evaluations performed on networks like AlexNet, VGG16 and ResNet18 show that the proposed architecture, mapping, and data flow can provide up to 23x speedup over an NVIDIA Titan Xp GPU. Furthermore, it achieves upto 6.5x speedup over an ideal von Neumann architecture with infinite computational throughput, highlighting the need to overcome the memory bottleneck in future generations of DNN hardware.
IMAC: In-memory multi-bit Multiplication andACcumulation in 6T SRAM Array
Mar 27, 2020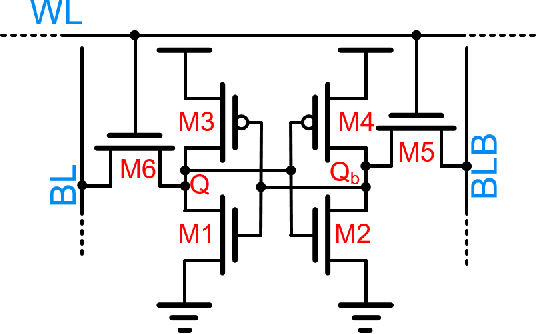
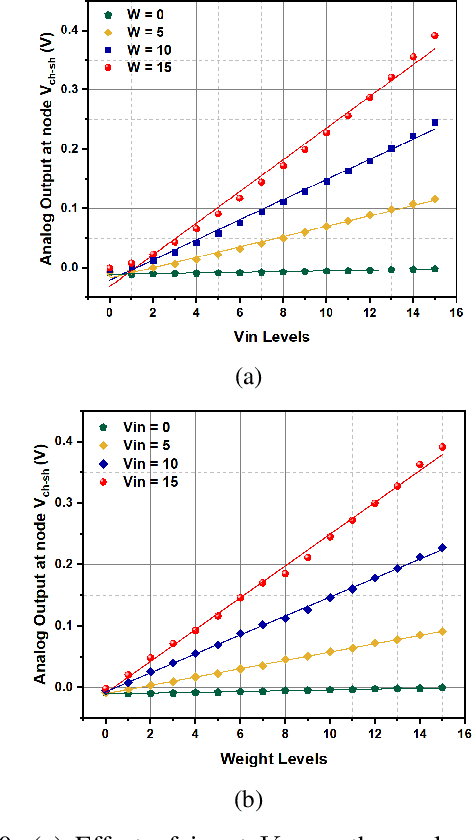

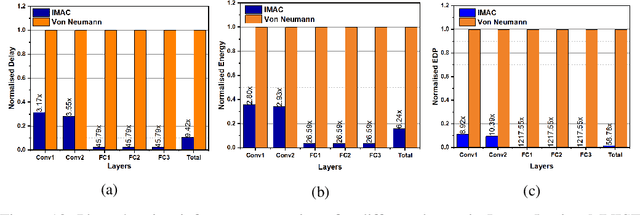
`In-memory computing' is being widely explored as a novel computing paradigm to mitigate the well known memory bottleneck. This emerging paradigm aims at embedding some aspects of computations inside the memory array, thereby avoiding frequent and expensive movement of data between the compute unit and the storage memory. In-memory computing with respect to Silicon memories has been widely explored on various memory bit-cells. Embedding computation inside the 6 transistor (6T) SRAM array is of special interest since it is the most widely used on-chip memory. In this paper, we present a novel in-memory multiplication followed by accumulation operation capable of performing parallel dot products within 6T SRAM without any changes to the standard bitcell. We, further, study the effect of circuit non-idealities and process variations on the accuracy of the LeNet-5 and VGG neural network architectures against the MNIST and CIFAR-10 datasets, respectively. The proposed in-memory dot-product mechanism achieves 88.8% and 99% accuracy for the CIFAR-10 and MNIST, respectively. Compared to the standard von Neumann system, the proposed system is 6.24x better in energy consumption and 9.42x better in delay.