 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing VLA Models: Identifying the Action Generation Bottleneck for Edge AI Architectures
Mar 01, 2026Vision-Language-Action (VLA) models are an emerging class of workloads critical for robotics and embodied AI at the edge. As these models scale, they demonstrate significant capability gains, yet they must be deployed locally to meet the strict latency requirements of real-time applications. This paper characterizes VLA performance on two generations of edge hardware, viz. the Nvidia Jetson Orin and Thor platforms. Using MolmoAct-7B, a state-of-the-art VLA model, we identify a primary execution bottleneck: up to 75% of end-to-end latency is consumed by the memory-bound action-generation phase. Through analytical modeling and simulations, we project the hardware requirements for scaling to 100B parameter models. We also explore the impact of high-bandwidth memory technologies and processing-in-memory (PIM) as promising future pathways in edge systems for embodied AI.
Learning to Localize Leakage of Cryptographic Sensitive Variables
Mar 10, 2025While cryptographic algorithms such as the ubiquitous Advanced Encryption Standard (AES) are secure, *physical implementations* of these algorithms in hardware inevitably 'leak' sensitive data such as cryptographic keys. A particularly insidious form of leakage arises from the fact that hardware consumes power and emits radiation in a manner that is statistically associated with the data it processes and the instructions it executes. Supervised deep learning has emerged as a state-of-the-art tool for carrying out *side-channel attacks*, which exploit this leakage by learning to map power/radiation measurements throughout encryption to the sensitive data operated on during that encryption. In this work we develop a principled deep learning framework for determining the relative leakage due to measurements recorded at different points in time, in order to inform *defense* against such attacks. This information is invaluable to cryptographic hardware designers for understanding *why* their hardware leaks and how they can mitigate it (e.g. by indicating the particular sections of code or electronic components which are responsible). Our framework is based on an adversarial game between a family of classifiers trained to estimate the conditional distributions of sensitive data given subsets of measurements, and a budget-constrained noise distribution which probabilistically erases individual measurements to maximize the loss of these classifiers. We demonstrate our method's efficacy and ability to overcome limitations of prior work through extensive experimental comparison with 8 baseline methods using 3 evaluation metrics and 6 publicly-available power/EM trace datasets from AES, ECC and RSA implementations. We provide an open-source PyTorch implementation of these experiments.
BCQ: Block Clustered Quantization for 4-bit (W4A4) LLM Inference
Feb 07, 2025Post-training quantization (PTQ) is a promising approach to reducing the storage and computational requirements of large language models (LLMs) without additional training cost. Recent PTQ studies have primarily focused on quantizing only weights to sub-8-bits while maintaining activations at 8-bits or higher. Accurate sub-8-bit quantization for both weights and activations without relying on quantization-aware training remains a significant challenge. We propose a novel quantization method called block clustered quantization (BCQ) wherein each operand tensor is decomposed into blocks (a block is a group of contiguous scalars), blocks are clustered based on their statistics, and a dedicated optimal quantization codebook is designed for each cluster. As a specific embodiment of this approach, we propose a PTQ algorithm called Locally-Optimal BCQ (LO-BCQ) that iterates between the steps of block clustering and codebook design to greedily minimize the quantization mean squared error. When weight and activation scalars are encoded to W4A4 format (with 0.5-bits of overhead for storing scaling factors and codebook selectors), we advance the current state-of-the-art by demonstrating <1% loss in inference accuracy across several LLMs and downstream tasks.
Power side-channel leakage localization through adversarial training of deep neural networks
Oct 29, 2024Supervised deep learning has emerged as an effective tool for carrying out power side-channel attacks on cryptographic implementations. While increasingly-powerful deep learning-based attacks are regularly published, comparatively-little work has gone into using deep learning to defend against these attacks. In this work we propose a technique for identifying which timesteps in a power trace are responsible for leaking a cryptographic key, through an adversarial game between a deep learning-based side-channel attacker which seeks to classify a sensitive variable from the power traces recorded during encryption, and a trainable noise generator which seeks to thwart this attack by introducing a minimal amount of noise into the power traces. We demonstrate on synthetic datasets that our method can outperform existing techniques in the presence of common countermeasures such as Boolean masking and trace desynchronization. Results on real datasets are weak because the technique is highly sensitive to hyperparameters and early-stop point, and we lack a holdout dataset with ground truth knowledge of leaking points for model selection. Nonetheless, we believe our work represents an important first step towards deep side-channel leakage localization without relying on strong assumptions about the implementation or the nature of its leakage. An open-source PyTorch implementation of our experiments is provided.
Ev-Edge: Efficient Execution of Event-based Vision Algorithms on Commodity Edge Platforms
Mar 23, 2024Event cameras have emerged as a promising sensing modality for autonomous navigation systems, owing to their high temporal resolution, high dynamic range and negligible motion blur. To process the asynchronous temporal event streams from such sensors, recent research has shown that a mix of Artificial Neural Networks (ANNs), Spiking Neural Networks (SNNs) as well as hybrid SNN-ANN algorithms are necessary to achieve high accuracies across a range of perception tasks. However, we observe that executing such workloads on commodity edge platforms which feature heterogeneous processing elements such as CPUs, GPUs and neural accelerators results in inferior performance. This is due to the mismatch between the irregular nature of event streams and diverse characteristics of algorithms on the one hand and the underlying hardware platform on the other. We propose Ev-Edge, a framework that contains three key optimizations to boost the performance of event-based vision systems on edge platforms: (1) An Event2Sparse Frame converter directly transforms raw event streams into sparse frames, enabling the use of sparse libraries with minimal encoding overheads (2) A Dynamic Sparse Frame Aggregator merges sparse frames at runtime by trading off the temporal granularity of events and computational demand thereby improving hardware utilization (3) A Network Mapper maps concurrently executing tasks to different processing elements while also selecting layer precision by considering both compute and communication overheads. On several state-of-art networks for a range of autonomous navigation tasks, Ev-Edge achieves 1.28x-2.05x improvements in latency and 1.23x-2.15x in energy over an all-GPU implementation on the NVIDIA Jetson Xavier AGX platform for single-task execution scenarios. Ev-Edge also achieves 1.43x-1.81x latency improvements over round-robin scheduling methods in multi-task execution scenarios.
Evaluation of STT-MRAM as a Scratchpad for Training in ML Accelerators
Aug 03, 2023Progress in artificial intelligence and machine learning over the past decade has been driven by the ability to train larger deep neural networks (DNNs), leading to a compute demand that far exceeds the growth in hardware performance afforded by Moore's law. Training DNNs is an extremely memory-intensive process, requiring not just the model weights but also activations and gradients for an entire minibatch to be stored. The need to provide high-density and low-leakage on-chip memory motivates the exploration of emerging non-volatile memory for training accelerators. Spin-Transfer-Torque MRAM (STT-MRAM) offers several desirable properties for training accelerators, including 3-4x higher density than SRAM, significantly reduced leakage power, high endurance and reasonable access time. On the one hand, MRAM write operations require high write energy and latency due to the need to ensure reliable switching. In this study, we perform a comprehensive device-to-system evaluation and co-optimization of STT-MRAM for efficient ML training accelerator design. We devised a cross-layer simulation framework to evaluate the effectiveness of STT-MRAM as a scratchpad replacing SRAM in a systolic-array-based DNN accelerator. To address the inefficiency of writes in STT-MRAM, we propose to reduce write voltage and duration. To evaluate the ensuing accuracy-efficiency trade-off, we conduct a thorough analysis of the error tolerance of input activations, weights, and errors during the training. We propose heterogeneous memory configurations that enable training convergence with good accuracy. We show that MRAM provide up to 15-22x improvement in system level energy across a suite of DNN benchmarks under iso-capacity and iso-area scenarios. Further optimizing STT-MRAM write operations can provide over 2x improvement in write energy for minimal degradation in application-level training accuracy.
X-Former: In-Memory Acceleration of Transformers
Mar 13, 2023Transformers have achieved great success in a wide variety of natural language processing (NLP) tasks due to the attention mechanism, which assigns an importance score for every word relative to other words in a sequence. However, these models are very large, often reaching hundreds of billions of parameters, and therefore require a large number of DRAM accesses. Hence, traditional deep neural network (DNN) accelerators such as GPUs and TPUs face limitations in processing Transformers efficiently. In-memory accelerators based on non-volatile memory promise to be an effective solution to this challenge, since they provide high storage density while performing massively parallel matrix vector multiplications within memory arrays. However, attention score computations, which are frequently used in Transformers (unlike CNNs and RNNs), require matrix vector multiplications (MVM) where both operands change dynamically for each input. As a result, conventional NVM-based accelerators incur high write latency and write energy when used for Transformers, and further suffer from the low endurance of most NVM technologies. To address these challenges, we present X-Former, a hybrid in-memory hardware accelerator that consists of both NVM and CMOS processing elements to execute transformer workloads efficiently. To improve the hardware utilization of X-Former, we also propose a sequence blocking dataflow, which overlaps the computations of the two processing elements and reduces execution time. Across several benchmarks, we show that X-Former achieves upto 85x and 7.5x improvements in latency and energy over a NVIDIA GeForce GTX 1060 GPU and upto 10.7x and 4.6x improvements in latency and energy over a state-of-the-art in-memory NVM accelerator.
Approximate Computing and the Efficient Machine Learning Expedition
Oct 02, 2022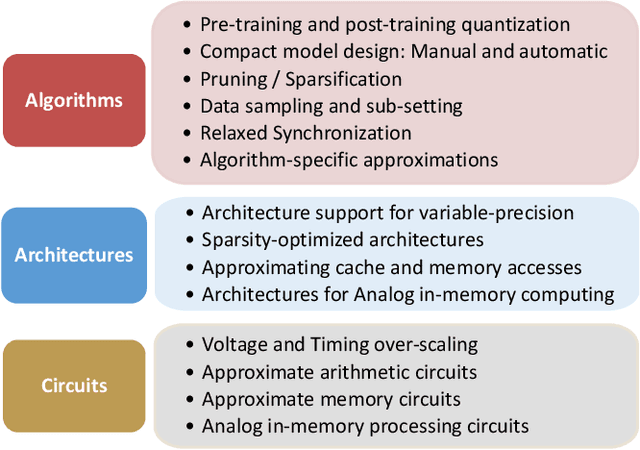
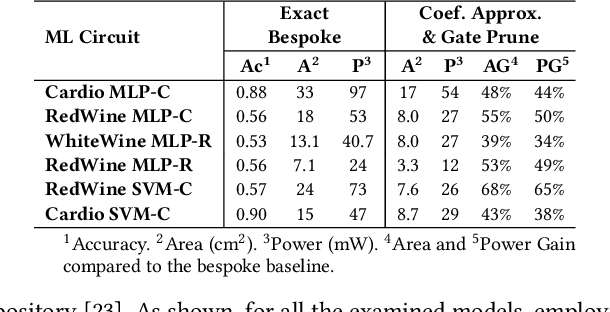
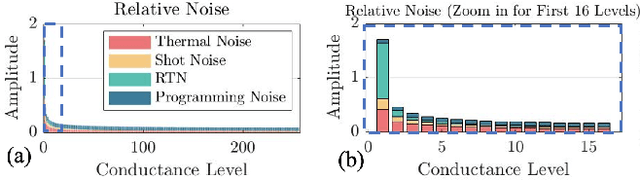
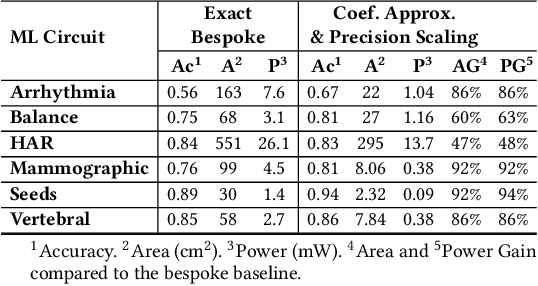
Approximate computing (AxC) has been long accepted as a design alternative for efficient system implementation at the cost of relaxed accuracy requirements. Despite the AxC research activities in various application domains, AxC thrived the past decade when it was applied in Machine Learning (ML). The by definition approximate notion of ML models but also the increased computational overheads associated with ML applications-that were effectively mitigated by corresponding approximations-led to a perfect matching and a fruitful synergy. AxC for AI/ML has transcended beyond academic prototypes. In this work, we enlighten the synergistic nature of AxC and ML and elucidate the impact of AxC in designing efficient ML systems. To that end, we present an overview and taxonomy of AxC for ML and use two descriptive application scenarios to demonstrate how AxC boosts the efficiency of ML systems.
PIM-DRAM: Accelerating Machine Learning Workloads using Processing in Commodity DRAM
May 14, 2021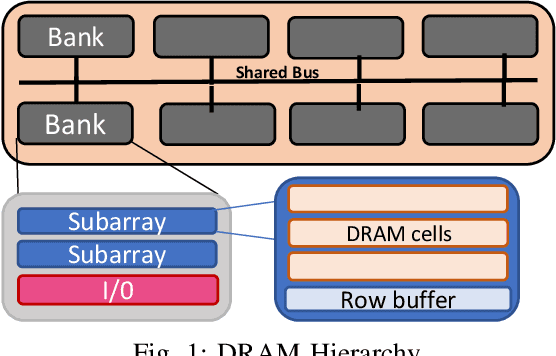
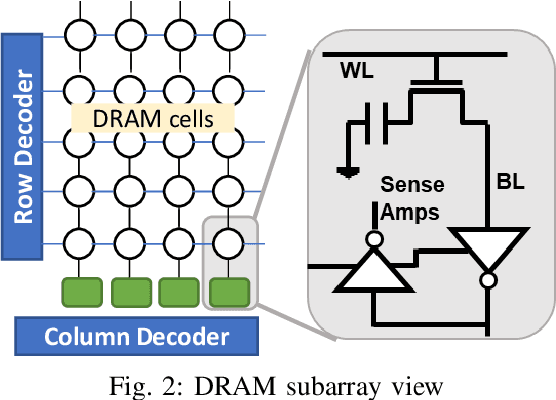
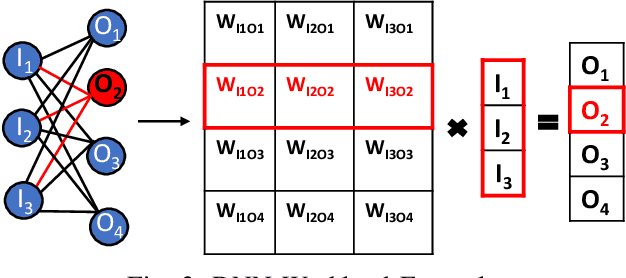
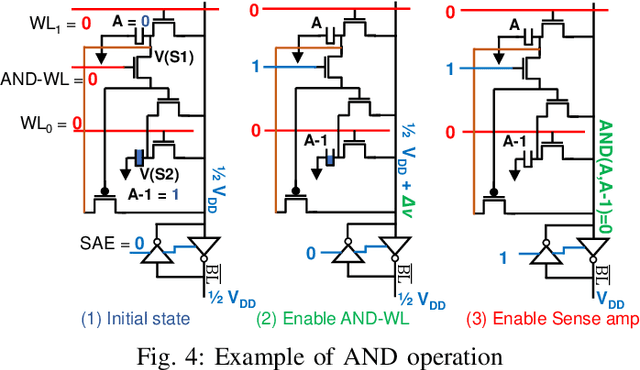
Deep Neural Networks (DNNs) have transformed the field of machine learning and are widely deployed in many applications involving image, video, speech and natural language processing. The increasing compute demands of DNNs have been widely addressed through Graphics Processing Units (GPUs) and specialized accelerators. However, as model sizes grow, these von Neumann architectures require very high memory bandwidth to keep the processing elements utilized as a majority of the data resides in the main memory. Processing in memory has been proposed as a promising solution for the memory wall bottleneck for ML workloads. In this work, we propose a new DRAM-based processing-in-memory (PIM) multiplication primitive coupled with intra-bank accumulation to accelerate matrix vector operations in ML workloads. The proposed multiplication primitive adds < 1% area overhead and does not require any change in the DRAM peripherals. Therefore, the proposed multiplication can be easily adopted in commodity DRAM chips. Subsequently, we design a DRAM-based PIM architecture, data mapping scheme and dataflow for executing DNNs within DRAM. System evaluations performed on networks like AlexNet, VGG16 and ResNet18 show that the proposed architecture, mapping, and data flow can provide up to 23x speedup over an NVIDIA Titan Xp GPU. Furthermore, it achieves upto 6.5x speedup over an ideal von Neumann architecture with infinite computational throughput, highlighting the need to overcome the memory bottleneck in future generations of DNN hardware.
Ax-BxP: Approximate Blocked Computation for Precision-Reconfigurable Deep Neural Network Acceleration
Nov 25, 2020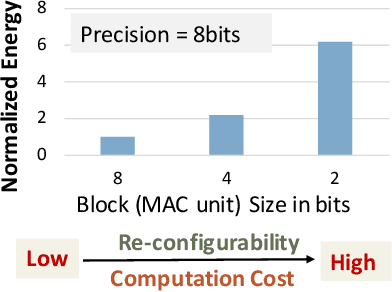
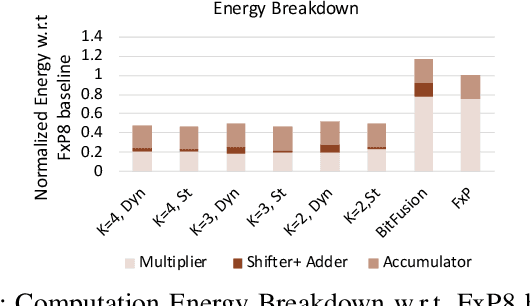
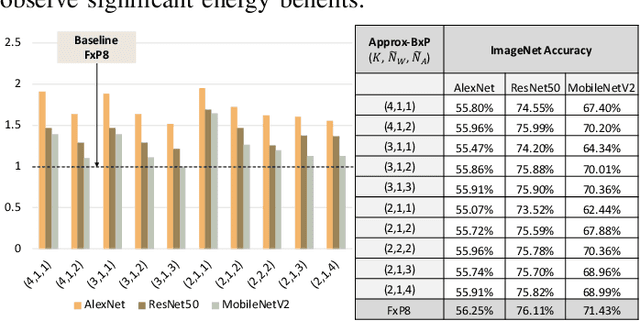
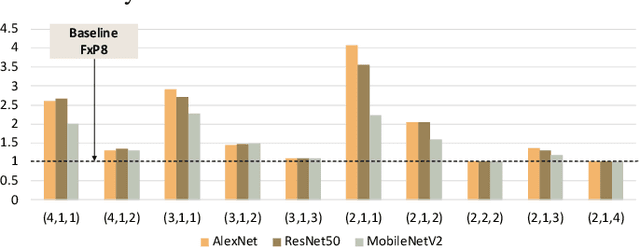
Precision scaling has emerged as a popular technique to optimize the compute and storage requirements of Deep Neural Networks (DNNs). Efforts toward creating ultra-low-precision (sub-8-bit) DNNs suggest that the minimum precision required to achieve a given network-level accuracy varies considerably across networks, and even across layers within a network, requiring support for variable precision in DNN hardware. Previous proposals such as bit-serial hardware incur high overheads, significantly diminishing the benefits of lower precision. To efficiently support precision re-configurability in DNN accelerators, we introduce an approximate computing method wherein DNN computations are performed block-wise (a block is a group of bits) and re-configurability is supported at the granularity of blocks. Results of block-wise computations are composed in an approximate manner to enable efficient re-configurability. We design a DNN accelerator that embodies approximate blocked computation and propose a method to determine a suitable approximation configuration for a given DNN. By varying the approximation configurations across DNNs, we achieve 1.11x-1.34x and 1.29x-1.6x improvement in system energy and performance respectively, over an 8-bit fixed-point (FxP8) baseline, with negligible loss in classification accuracy. Further, by varying the approximation configurations across layers and data-structures within DNNs, we achieve 1.14x-1.67x and 1.31x-1.93x improvement in system energy and performance respectively, with negligible accuracy loss.