 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListening Alone, Understanding Together: Collaborative Context Recovery for Privacy-Aware AI
Apr 14, 2026We introduce CONCORD, a privacy-aware asynchronous assistant-to-assistant (A2A) framework that leverages collaboration between proactive speech-based AI. As agents evolve from reactive to always-listening assistants, they face a core privacy risk (of capturing non-consenting speakers), which makes their social deployment a challenge. To overcome this, we implement CONCORD, which enforces owner-only speech capture via real-time speaker verification, producing a one-sided transcript that incurs missing context but preserves privacy. We demonstrate that CONCORD can safely recover necessary context through (1) spatio-temporal context resolution, (2) information gap detection, and (3) minimal A2A queries governed by a relationship-aware disclosure. Instead of hallucination-prone inferring, CONCORD treats context recovery as a negotiated safe exchange between assistants. Across a multi-domain dialogue dataset, CONCORD achieves 91.4% recall in gap detection, 96% relationship classification accuracy, and 97% true negative rate in privacy-sensitive disclosure decisions. By reframing always-listening AI as a coordination problem between privacy-preserving agents, CONCORD offers a practical path toward socially deployable proactive conversational agents.
RLHFless: Serverless Computing for Efficient RLHF
Feb 26, 2026Reinforcement Learning from Human Feedback (RLHF) has been widely applied to Large Language Model (LLM) post-training to align model outputs with human preferences. Recent models, such as DeepSeek-R1, have also shown RLHF's potential to improve LLM reasoning on complex tasks. In RL, inference and training co-exist, creating dynamic resource demands throughout the workflow. Compared to traditional RL, RLHF further challenges training efficiency due to expanding model sizes and resource consumption. Several RLHF frameworks aim to balance flexible abstraction and efficient execution. However, they rely on serverful infrastructures, which struggle with fine-grained resource variability. As a result, during synchronous RLHF training, idle time between or within RL components often causes overhead and resource wastage. To address these issues, we present RLHFless, the first scalable training framework for synchronous RLHF, built on serverless computing environments. RLHFless adapts to dynamic resource demands throughout the RLHF pipeline, pre-computes shared prefixes to avoid repeated computation, and uses a cost-aware actor scaling strategy that accounts for response length variation to find sweet spots with lower cost and higher speed. In addition, RLHFless assigns workloads efficiently to reduce intra-function imbalance and idle time. Experiments on both physical testbeds and a large-scale simulated cluster show that RLHFless achieves up to 1.35x speedup and 44.8% cost reduction compared to the state-of-the-art baseline.
YOPO-Nav: Visual Navigation using 3DGS Graphs from One-Pass Videos
Dec 10, 2025



Visual navigation has emerged as a practical alternative to traditional robotic navigation pipelines that rely on detailed mapping and path planning. However, constructing and maintaining 3D maps is often computationally expensive and memory-intensive. We address the problem of visual navigation when exploration videos of a large environment are available. The videos serve as a visual reference, allowing a robot to retrace the explored trajectories without relying on metric maps. Our proposed method, YOPO-Nav (You Only Pass Once), encodes an environment into a compact spatial representation composed of interconnected local 3D Gaussian Splatting (3DGS) models. During navigation, the framework aligns the robot's current visual observation with this representation and predicts actions that guide it back toward the demonstrated trajectory. YOPO-Nav employs a hierarchical design: a visual place recognition (VPR) module provides coarse localization, while the local 3DGS models refine the goal and intermediate poses to generate control actions. To evaluate our approach, we introduce the YOPO-Campus dataset, comprising 4 hours of egocentric video and robot controller inputs from over 6 km of human-teleoperated robot trajectories. We benchmark recent visual navigation methods on trajectories from YOPO-Campus using a Clearpath Jackal robot. Experimental results show YOPO-Nav provides excellent performance in image-goal navigation for real-world scenes on a physical robot. The dataset and code will be made publicly available for visual navigation and scene representation research.
TransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
StatsMerging: Statistics-Guided Model Merging via Task-Specific Teacher Distillation
Jun 05, 2025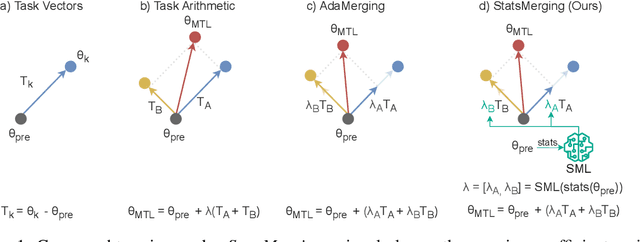

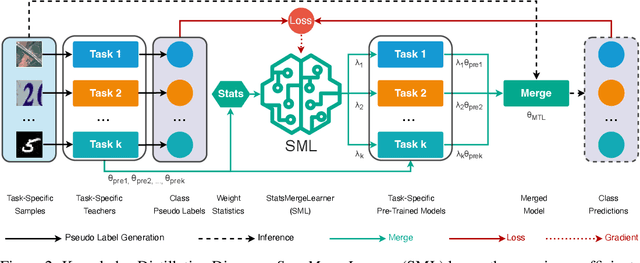

Model merging has emerged as a promising solution to accommodate multiple large models within constrained memory budgets. We present StatsMerging, a novel lightweight learning-based model merging method guided by weight distribution statistics without requiring ground truth labels or test samples. StatsMerging offers three key advantages: (1) It uniquely leverages singular values from singular value decomposition (SVD) to capture task-specific weight distributions, serving as a proxy for task importance to guide task coefficient prediction; (2) It employs a lightweight learner StatsMergeLearner to model the weight distributions of task-specific pre-trained models, improving generalization and enhancing adaptation to unseen samples; (3) It introduces Task-Specific Teacher Distillation for merging vision models with heterogeneous architectures, a merging learning paradigm that avoids costly ground-truth labels by task-specific teacher distillation. Notably, we present two types of knowledge distillation, (a) distilling knowledge from task-specific models to StatsMergeLearner; and (b) distilling knowledge from models with heterogeneous architectures prior to merging. Extensive experiments across eight tasks demonstrate the effectiveness of StatsMerging. Our results show that StatsMerging outperforms state-of-the-art techniques in terms of overall accuracy, generalization to unseen tasks, and robustness to image quality variations.
Memory Proxy Maps for Visual Navigation
Nov 15, 2024



Visual navigation takes inspiration from humans, who navigate in previously unseen environments using vision without detailed environment maps. Inspired by this, we introduce a novel no-RL, no-graph, no-odometry approach to visual navigation using feudal learning to build a three tiered agent. Key to our approach is a memory proxy map (MPM), an intermediate representation of the environment learned in a self-supervised manner by the high-level manager agent that serves as a simplified memory, approximating what the agent has seen. We demonstrate that recording observations in this learned latent space is an effective and efficient memory proxy that can remove the need for graphs and odometry in visual navigation tasks. For the mid-level manager agent, we develop a waypoint network (WayNet) that outputs intermediate subgoals, or waypoints, imitating human waypoint selection during local navigation. For the low-level worker agent, we learn a classifier over a discrete action space that avoids local obstacles and moves the agent towards the WayNet waypoint. The resulting feudal navigation network offers a novel approach with no RL, no graph, no odometry, and no metric map; all while achieving SOTA results on the image goal navigation task.
Few-Class Arena: A Benchmark for Efficient Selection of Vision Models and Dataset Difficulty Measurement
Nov 02, 2024



We propose Few-Class Arena (FCA), as a unified benchmark with focus on testing efficient image classification models for few classes. A wide variety of benchmark datasets with many classes (80-1000) have been created to assist Computer Vision architectural evolution. An increasing number of vision models are evaluated with these many-class datasets. However, real-world applications often involve substantially fewer classes of interest (2-10). This gap between many and few classes makes it difficult to predict performance of the few-class applications using models trained on the available many-class datasets. To date, little has been offered to evaluate models in this Few-Class Regime. We conduct a systematic evaluation of the ResNet family trained on ImageNet subsets from 2 to 1000 classes, and test a wide spectrum of Convolutional Neural Networks and Transformer architectures over ten datasets by using our newly proposed FCA tool. Furthermore, to aid an up-front assessment of dataset difficulty and a more efficient selection of models, we incorporate a difficulty measure as a function of class similarity. FCA offers a new tool for efficient machine learning in the Few-Class Regime, with goals ranging from a new efficient class similarity proposal, to lightweight model architecture design, to a new scaling law. FCA is user-friendly and can be easily extended to new models and datasets, facilitating future research work. Our benchmark is available at https://github.com/fewclassarena/fca.
Representation Similarity: A Better Guidance of DNN Layer Sharing for Edge Computing without Training
Oct 15, 2024Edge computing has emerged as an alternative to reduce transmission and processing delay and preserve privacy of the video streams. However, the ever-increasing complexity of Deep Neural Networks (DNNs) used in video-based applications (e.g. object detection) exerts pressure on memory-constrained edge devices. Model merging is proposed to reduce the DNNs' memory footprint by keeping only one copy of merged layers' weights in memory. In existing model merging techniques, (i) only architecturally identical layers can be shared; (ii) requires computationally expensive retraining in the cloud; (iii) assumes the availability of ground truth for retraining. The re-evaluation of a merged model's performance, however, requires a validation dataset with ground truth, typically runs at the cloud. Common metrics to guide the selection of shared layers include the size or computational cost of shared layers or representation size. We propose a new model merging scheme by sharing representations (i.e., outputs of layers) at the edge, guided by representation similarity S. We show that S is extremely highly correlated with merged model's accuracy with Pearson Correlation Coefficient |r| > 0.94 than other metrics, demonstrating that representation similarity can serve as a strong validation accuracy indicator without ground truth. We present our preliminary results of the newly proposed model merging scheme with identified challenges, demonstrating a promising research future direction.
Preserving Individuality while Following the Crowd: Understanding the Role of User Taste and Crowd Wisdom in Online Product Rating Prediction
Sep 06, 2024



Numerous algorithms have been developed for online product rating prediction, but the specific influence of user and product information in determining the final prediction score remains largely unexplored. Existing research often relies on narrowly defined data settings, which overlooks real-world challenges such as the cold-start problem, cross-category information utilization, and scalability and deployment issues. To delve deeper into these aspects, and particularly to uncover the roles of individual user taste and collective wisdom, we propose a unique and practical approach that emphasizes historical ratings at both the user and product levels, encapsulated using a continuously updated dynamic tree representation. This representation effectively captures the temporal dynamics of users and products, leverages user information across product categories, and provides a natural solution to the cold-start problem. Furthermore, we have developed an efficient data processing strategy that makes this approach highly scalable and easily deployable. Comprehensive experiments in real industry settings demonstrate the effectiveness of our approach. Notably, our findings reveal that individual taste dominates over collective wisdom in online product rating prediction, a perspective that contrasts with the commonly observed wisdom of the crowd phenomenon in other domains. This dominance of individual user taste is consistent across various model types, including the boosting tree model, recurrent neural network (RNN), and transformer-based architectures. This observation holds true across the overall population, within individual product categories, and in cold-start scenarios. Our findings underscore the significance of individual user tastes in the context of online product rating prediction and the robustness of our approach across different model architectures.
Inherent Challenges of Post-Hoc Membership Inference for Large Language Models
Jun 25, 2024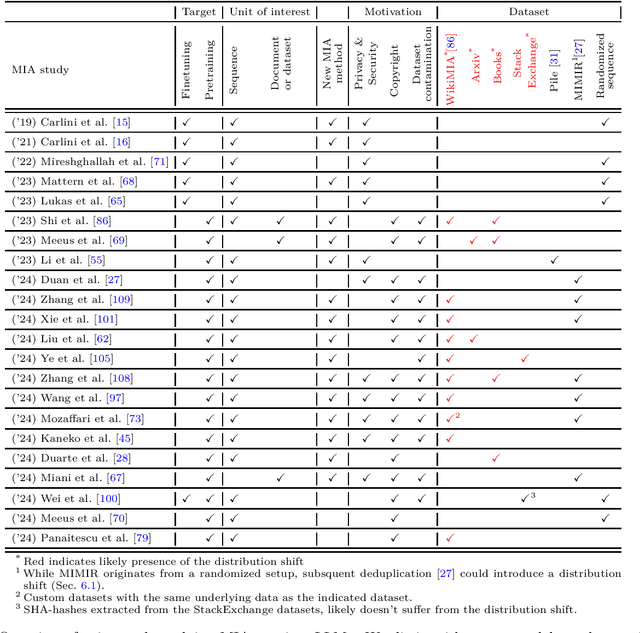
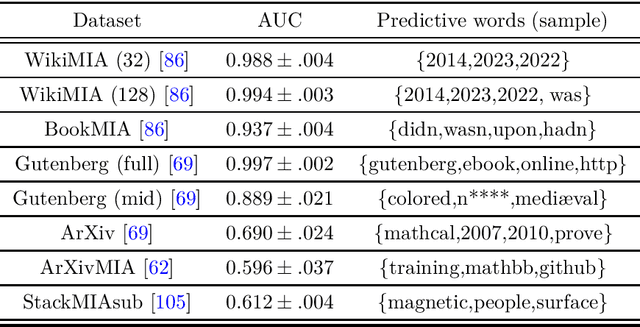
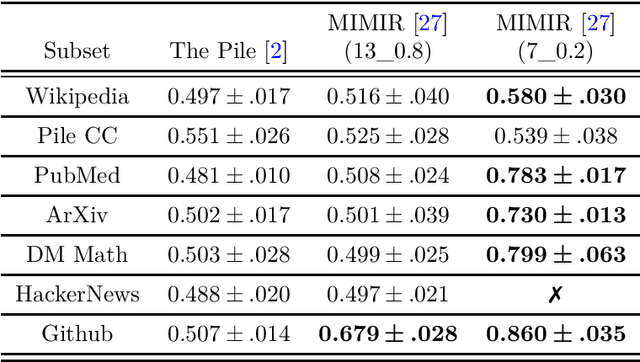
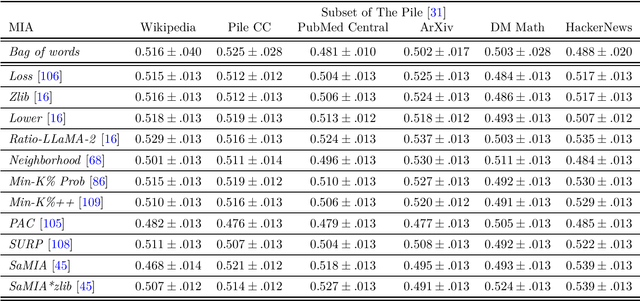
Large Language Models (LLMs) are often trained on vast amounts of undisclosed data, motivating the development of post-hoc Membership Inference Attacks (MIAs) to gain insight into their training data composition. However, in this paper, we identify inherent challenges in post-hoc MIA evaluation due to potential distribution shifts between collected member and non-member datasets. Using a simple bag-of-words classifier, we demonstrate that datasets used in recent post-hoc MIAs suffer from significant distribution shifts, in some cases achieving near-perfect distinction between members and non-members. This implies that previously reported high MIA performance may be largely attributable to these shifts rather than model memorization. We confirm that randomized, controlled setups eliminate such shifts and thus enable the development and fair evaluation of new MIAs. However, we note that such randomized setups are rarely available for the latest LLMs, making post-hoc data collection still required to infer membership for real-world LLMs. As a potential solution, we propose a Regression Discontinuity Design (RDD) approach for post-hoc data collection, which substantially mitigates distribution shifts. Evaluating various MIA methods on this RDD setup yields performance barely above random guessing, in stark contrast to previously reported results. Overall, our findings highlight the challenges in accurately measuring LLM memorization and the need for careful experimental design in (post-hoc) membership inference tasks.