 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
Preserving Individuality while Following the Crowd: Understanding the Role of User Taste and Crowd Wisdom in Online Product Rating Prediction
Sep 06, 2024



Numerous algorithms have been developed for online product rating prediction, but the specific influence of user and product information in determining the final prediction score remains largely unexplored. Existing research often relies on narrowly defined data settings, which overlooks real-world challenges such as the cold-start problem, cross-category information utilization, and scalability and deployment issues. To delve deeper into these aspects, and particularly to uncover the roles of individual user taste and collective wisdom, we propose a unique and practical approach that emphasizes historical ratings at both the user and product levels, encapsulated using a continuously updated dynamic tree representation. This representation effectively captures the temporal dynamics of users and products, leverages user information across product categories, and provides a natural solution to the cold-start problem. Furthermore, we have developed an efficient data processing strategy that makes this approach highly scalable and easily deployable. Comprehensive experiments in real industry settings demonstrate the effectiveness of our approach. Notably, our findings reveal that individual taste dominates over collective wisdom in online product rating prediction, a perspective that contrasts with the commonly observed wisdom of the crowd phenomenon in other domains. This dominance of individual user taste is consistent across various model types, including the boosting tree model, recurrent neural network (RNN), and transformer-based architectures. This observation holds true across the overall population, within individual product categories, and in cold-start scenarios. Our findings underscore the significance of individual user tastes in the context of online product rating prediction and the robustness of our approach across different model architectures.
Has Your Pretrained Model Improved? A Multi-head Posterior Based Approach
Jan 15, 2024



The emergence of pretrained models has significantly impacted Natural Language Processing (NLP) and Computer Vision to relational datasets. Traditionally, these models are assessed through fine-tuned downstream tasks. However, this raises the question of how to evaluate these models more efficiently and more effectively. In this study, we explore a novel approach where we leverage the meta features associated with each entity as a source of worldly knowledge and employ entity representations from the models. We propose using the consistency between these representations and the meta features as a metric for evaluating pretrained models. Our method's effectiveness is demonstrated across various domains, including models with relational datasets, large language models and image models.
Visual Analytics for Efficient Image Exploration and User-Guided Image Captioning
Nov 02, 2023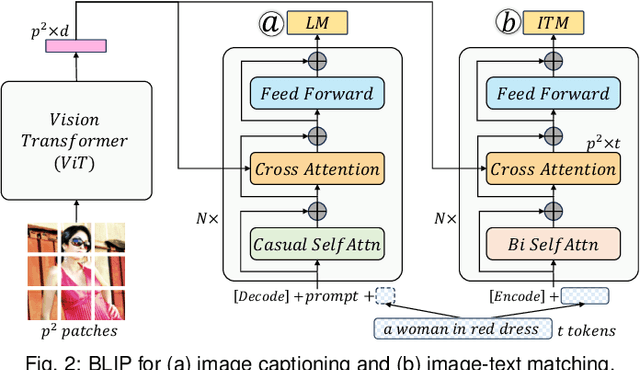



Recent advancements in pre-trained large-scale language-image models have ushered in a new era of visual comprehension, offering a significant leap forward. These breakthroughs have proven particularly instrumental in addressing long-standing challenges that were previously daunting. Leveraging these innovative techniques, this paper tackles two well-known issues within the realm of visual analytics: (1) the efficient exploration of large-scale image datasets and identification of potential data biases within them; (2) the evaluation of image captions and steering of their generation process. On the one hand, by visually examining the captions automatically generated from language-image models for an image dataset, we gain deeper insights into the semantic underpinnings of the visual contents, unearthing data biases that may be entrenched within the dataset. On the other hand, by depicting the association between visual contents and textual captions, we expose the weaknesses of pre-trained language-image models in their captioning capability and propose an interactive interface to steer caption generation. The two parts have been coalesced into a coordinated visual analytics system, fostering mutual enrichment of visual and textual elements. We validate the effectiveness of the system with domain practitioners through concrete case studies with large-scale image datasets.