 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHas Your Pretrained Model Improved? A Multi-head Posterior Based Approach
Jan 15, 2024



The emergence of pretrained models has significantly impacted Natural Language Processing (NLP) and Computer Vision to relational datasets. Traditionally, these models are assessed through fine-tuned downstream tasks. However, this raises the question of how to evaluate these models more efficiently and more effectively. In this study, we explore a novel approach where we leverage the meta features associated with each entity as a source of worldly knowledge and employ entity representations from the models. We propose using the consistency between these representations and the meta features as a metric for evaluating pretrained models. Our method's effectiveness is demonstrated across various domains, including models with relational datasets, large language models and image models.
Visual Analytics for Efficient Image Exploration and User-Guided Image Captioning
Nov 02, 2023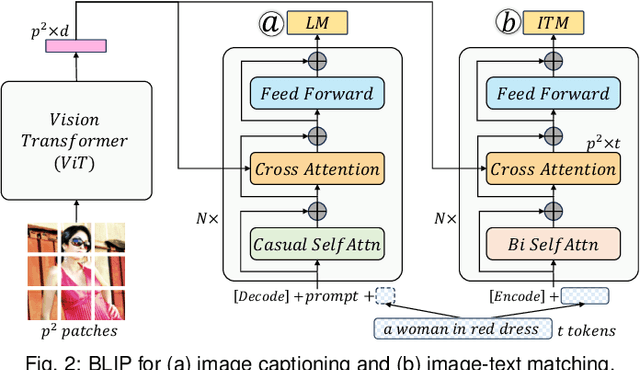



Recent advancements in pre-trained large-scale language-image models have ushered in a new era of visual comprehension, offering a significant leap forward. These breakthroughs have proven particularly instrumental in addressing long-standing challenges that were previously daunting. Leveraging these innovative techniques, this paper tackles two well-known issues within the realm of visual analytics: (1) the efficient exploration of large-scale image datasets and identification of potential data biases within them; (2) the evaluation of image captions and steering of their generation process. On the one hand, by visually examining the captions automatically generated from language-image models for an image dataset, we gain deeper insights into the semantic underpinnings of the visual contents, unearthing data biases that may be entrenched within the dataset. On the other hand, by depicting the association between visual contents and textual captions, we expose the weaknesses of pre-trained language-image models in their captioning capability and propose an interactive interface to steer caption generation. The two parts have been coalesced into a coordinated visual analytics system, fostering mutual enrichment of visual and textual elements. We validate the effectiveness of the system with domain practitioners through concrete case studies with large-scale image datasets.
Quantized Wasserstein Procrustes Alignment of Word Embedding Spaces
Dec 05, 2022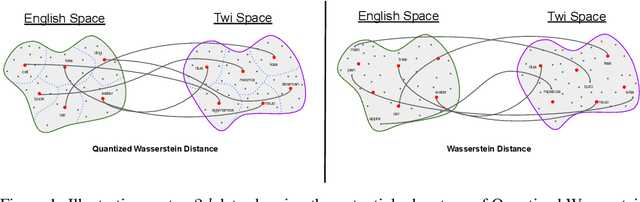
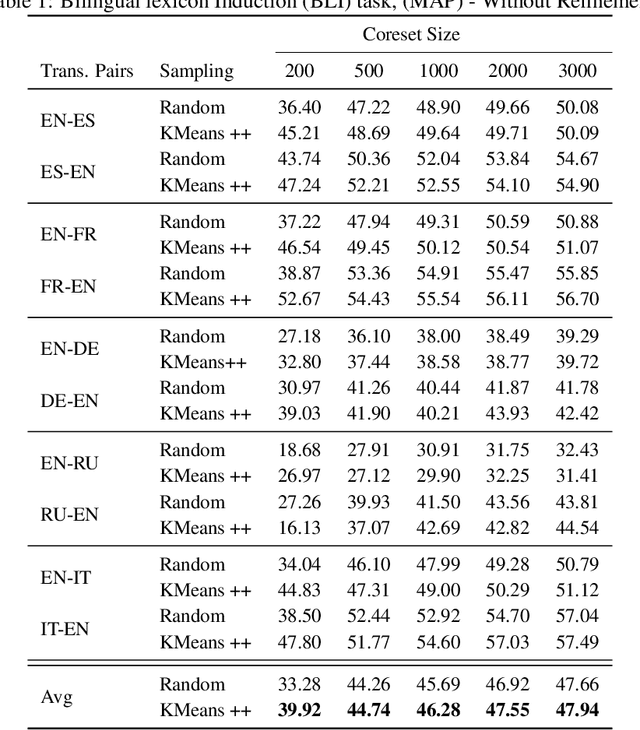

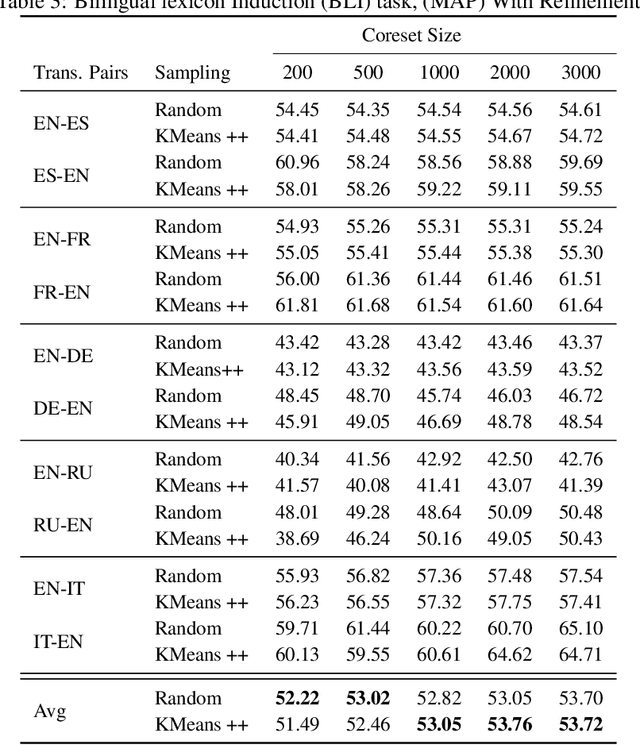
Optimal Transport (OT) provides a useful geometric framework to estimate the permutation matrix under unsupervised cross-lingual word embedding (CLWE) models that pose the alignment task as a Wasserstein-Procrustes problem. However, linear programming algorithms and approximate OT solvers via Sinkhorn for computing the permutation matrix come with a significant computational burden since they scale cubically and quadratically, respectively, in the input size. This makes it slow and infeasible to compute OT distances exactly for a larger input size, resulting in a poor approximation quality of the permutation matrix and subsequently a less robust learned transfer function or mapper. This paper proposes an unsupervised projection-based CLWE model called quantized Wasserstein Procrustes (qWP). qWP relies on a quantization step of both the source and target monolingual embedding space to estimate the permutation matrix given a cheap sampling procedure. This approach substantially improves the approximation quality of empirical OT solvers given fixed computational cost. We demonstrate that qWP achieves state-of-the-art results on the Bilingual lexicon Induction (BLI) task.