 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon Line-of-Sight Optical Wireless Communication using Neuromorphic Cameras
Mar 14, 2025Neuromorphic or event cameras, inspired by biological vision systems, capture changes in illumination with high temporal resolution and efficiency, producing streams of events rather than traditional images. In this paper, we explore the use of neuromorphic cameras for passive optical wireless communication (OWC), leveraging their asynchronous detection of illumination changes to decode data transmitted through reflections of light from objects. We propose a novel system that utilizes neuromorphic cameras for passive visible light communication (VLC), extending the concept to Non Line-of-Sight (NLoS) scenarios through passive reflections from everyday objects. Our experiments demonstrate the feasibility and advantages of using neuromorphic cameras for VLC, characterizing the performance of various modulation schemes, including traditional On-Off Keying (OOK) and advanced N-pulse modulation. We introduce an adaptive N-pulse modulation scheme that dynamically adjusts encoding based on the packet's bit composition, achieving higher data rates and robustness in different scenarios. Our results show that lighter-colored, glossy objects are better for NLoS communication, while larger objects and those with matte finishes experience higher error rates due to multipath reflections.
Revelio: A Real-World Screen-Camera Communication System with Visually Imperceptible Data Embedding
Jan 04, 2025



We present `Revelio', a real-world screen-camera communication system leveraging temporal flicker fusion in the OKLAB color space. Using spatially-adaptive flickering and encoding information in pixel region shapes, Revelio achieves visually imperceptible data embedding while remaining robust against noise, asynchronicity, and distortions in screen-camera channels, ensuring reliable decoding by standard smartphone cameras. The decoder, driven by a two-stage neural network, uses a weighted differential accumulator for precise frame detection and symbol recognition. Initial experiments demonstrate Revelio's effectiveness in interactive television, offering an unobtrusive method for meta-information transmission.
Memory Proxy Maps for Visual Navigation
Nov 15, 2024



Visual navigation takes inspiration from humans, who navigate in previously unseen environments using vision without detailed environment maps. Inspired by this, we introduce a novel no-RL, no-graph, no-odometry approach to visual navigation using feudal learning to build a three tiered agent. Key to our approach is a memory proxy map (MPM), an intermediate representation of the environment learned in a self-supervised manner by the high-level manager agent that serves as a simplified memory, approximating what the agent has seen. We demonstrate that recording observations in this learned latent space is an effective and efficient memory proxy that can remove the need for graphs and odometry in visual navigation tasks. For the mid-level manager agent, we develop a waypoint network (WayNet) that outputs intermediate subgoals, or waypoints, imitating human waypoint selection during local navigation. For the low-level worker agent, we learn a classifier over a discrete action space that avoids local obstacles and moves the agent towards the WayNet waypoint. The resulting feudal navigation network offers a novel approach with no RL, no graph, no odometry, and no metric map; all while achieving SOTA results on the image goal navigation task.
A Landmark-Aware Visual Navigation Dataset
Feb 22, 2024



Map representation learned by expert demonstrations has shown promising research value. However, recent advancements in the visual navigation field face challenges due to the lack of human datasets in the real world for efficient supervised representation learning of the environments. We present a Landmark-Aware Visual Navigation (LAVN) dataset to allow for supervised learning of human-centric exploration policies and map building. We collect RGB observation and human point-click pairs as a human annotator explores virtual and real-world environments with the goal of full coverage exploration of the space. The human annotators also provide distinct landmark examples along each trajectory, which we intuit will simplify the task of map or graph building and localization. These human point-clicks serve as direct supervision for waypoint prediction when learning to explore in environments. Our dataset covers a wide spectrum of scenes, including rooms in indoor environments, as well as walkways outdoors. Dataset is available at DOI: 10.5281/zenodo.10608067.
Feudal Networks for Visual Navigation
Feb 19, 2024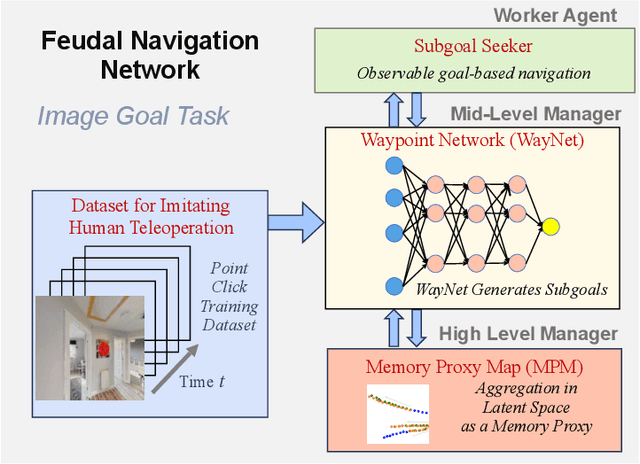

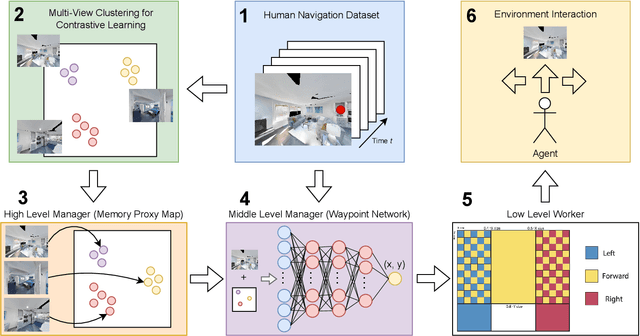
Visual navigation follows the intuition that humans can navigate without detailed maps. A common approach is interactive exploration while building a topological graph with images at nodes that can be used for planning. Recent variations learn from passive videos and can navigate using complex social and semantic cues. However, a significant number of training videos are needed, large graphs are utilized, and scenes are not unseen since odometry is utilized. We introduce a new approach to visual navigation using feudal learning, which employs a hierarchical structure consisting of a worker agent, a mid-level manager, and a high-level manager. Key to the feudal learning paradigm, agents at each level see a different aspect of the task and operate at different spatial and temporal scales. Two unique modules are developed in this framework. For the high-level manager, we learn a memory proxy map in a self supervised manner to record prior observations in a learned latent space and avoid the use of graphs and odometry. For the mid-level manager, we develop a waypoint network that outputs intermediate subgoals imitating human waypoint selection during local navigation. This waypoint network is pre-trained using a new, small set of teleoperation videos that we make publicly available, with training environments different from testing environments. The resulting feudal navigation network achieves near SOTA performance, while providing a novel no-RL, no-graph, no-odometry, no-metric map approach to the image goal navigation task.
ViFiT: Reconstructing Vision Trajectories from IMU and Wi-Fi Fine Time Measurements
Oct 04, 2023Tracking subjects in videos is one of the most widely used functions in camera-based IoT applications such as security surveillance, smart city traffic safety enhancement, vehicle to pedestrian communication and so on. In the computer vision domain, tracking is usually achieved by first detecting subjects with bounding boxes, then associating detected bounding boxes across video frames. For many IoT systems, images captured by cameras are usually sent over the network to be processed at a different site that has more powerful computing resources than edge devices. However, sending entire frames through the network causes significant bandwidth consumption that may exceed the system bandwidth constraints. To tackle this problem, we propose ViFiT, a transformer-based model that reconstructs vision bounding box trajectories from phone data (IMU and Fine Time Measurements). It leverages a transformer ability of better modeling long-term time series data. ViFiT is evaluated on Vi-Fi Dataset, a large-scale multimodal dataset in 5 diverse real world scenes, including indoor and outdoor environments. To fill the gap of proper metrics of jointly capturing the system characteristics of both tracking quality and video bandwidth reduction, we propose a novel evaluation framework dubbed Minimum Required Frames (MRF) and Minimum Required Frames Ratio (MRFR). ViFiT achieves an MRFR of 0.65 that outperforms the state-of-the-art approach for cross-modal reconstruction in LSTM Encoder-Decoder architecture X-Translator of 0.98, resulting in a high frame reduction rate as 97.76%.
ViFiCon: Vision and Wireless Association Via Self-Supervised Contrastive Learning
Oct 11, 2022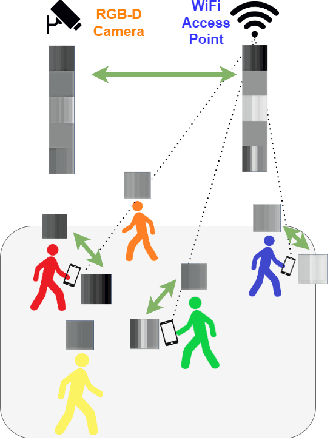

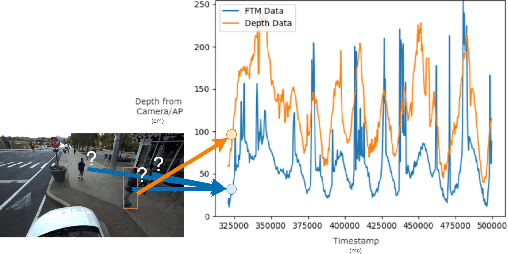

We introduce ViFiCon, a self-supervised contrastive learning scheme which uses synchronized information across vision and wireless modalities to perform cross-modal association. Specifically, the system uses pedestrian data collected from RGB-D camera footage as well as WiFi Fine Time Measurements (FTM) from a user's smartphone device. We represent the temporal sequence by stacking multi-person depth data spatially within a banded image. Depth data from RGB-D (vision domain) is inherently linked with an observable pedestrian, but FTM data (wireless domain) is associated only to a smartphone on the network. To formulate the cross-modal association problem as self-supervised, the network learns a scene-wide synchronization of the two modalities as a pretext task, and then uses that learned representation for the downstream task of associating individual bounding boxes to specific smartphones, i.e. associating vision and wireless information. We use a pre-trained region proposal model on the camera footage and then feed the extrapolated bounding box information into a dual-branch convolutional neural network along with the FTM data. We show that compared to fully supervised SoTA models, ViFiCon achieves high performance vision-to-wireless association, finding which bounding box corresponds to which smartphone device, without hand-labeled association examples for training data.
DeepLight: Robust & Unobtrusive Real-time Screen-Camera Communication for Real-World Displays
May 11, 2021
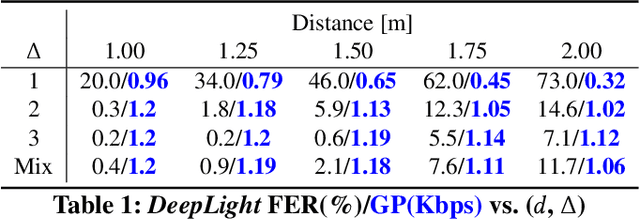

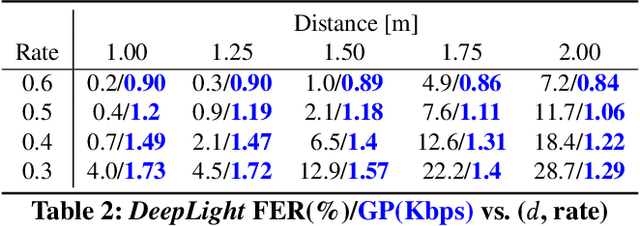
The paper introduces a novel, holistic approach for robust Screen-Camera Communication (SCC), where video content on a screen is visually encoded in a human-imperceptible fashion and decoded by a camera capturing images of such screen content. We first show that state-of-the-art SCC techniques have two key limitations for in-the-wild deployment: (a) the decoding accuracy drops rapidly under even modest screen extraction errors from the captured images, and (b) they generate perceptible flickers on common refresh rate screens even with minimal modulation of pixel intensity. To overcome these challenges, we introduce DeepLight, a system that incorporates machine learning (ML) models in the decoding pipeline to achieve humanly-imperceptible, moderately high SCC rates under diverse real-world conditions. Deep-Light's key innovation is the design of a Deep Neural Network (DNN) based decoder that collectively decodes all the bits spatially encoded in a display frame, without attempting to precisely isolate the pixels associated with each encoded bit. In addition, DeepLight supports imperceptible encoding by selectively modulating the intensity of only the Blue channel, and provides reasonably accurate screen extraction (IoU values >= 83%) by using state-of-the-art object detection DNN pipelines. We show that a fully functional DeepLight system is able to robustly achieve high decoding accuracy (frame error rate < 0.2) and moderately-high data goodput (>=0.95Kbps) using a human-held smartphone camera, even over larger screen-camera distances (approx =2m).
A Data Set of Internet Claims and Comparison of their Sentiments with Credibility
Nov 22, 2019
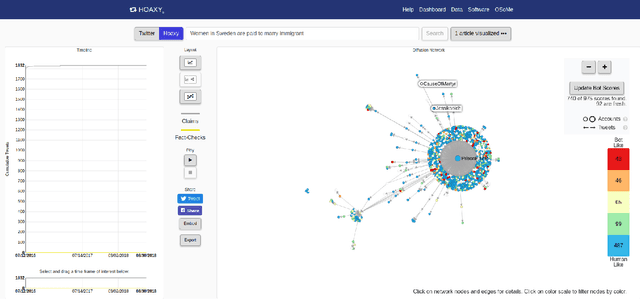
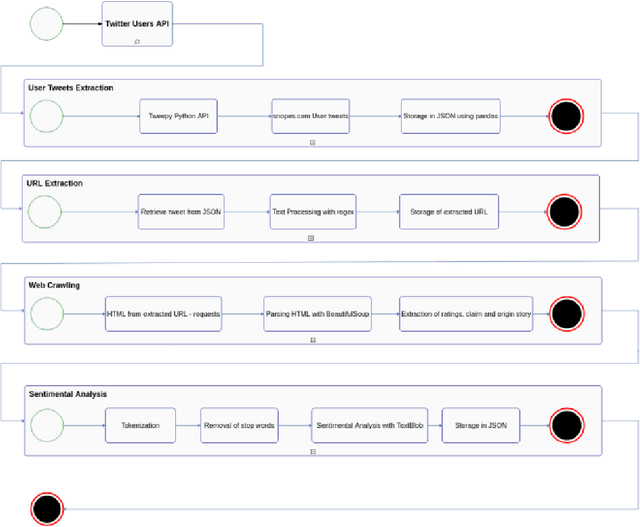
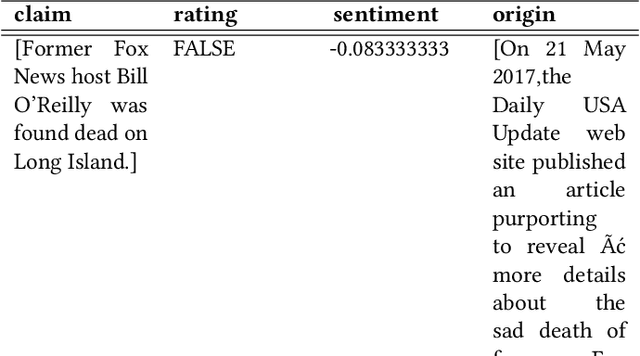
In this modern era, communication has become faster and easier. This means fallacious information can spread as fast as reality. Considering the damage that fake news kindles on the psychology of people and the fact that such news proliferates faster than truth, we need to study the phenomenon that helps spread fake news. An unbiased data set that depends on reality for rating news is necessary to construct predictive models for its classification. This paper describes the methodology to create such a data set. We collect our data from snopes.com which is a fact-checking organization. Furthermore, we intend to create this data set not only for classification of the news but also to find patterns that reason the intent behind misinformation. We also formally define an Internet Claim, its credibility, and the sentiment behind such a claim. We try to realize the relationship between the sentiment of a claim with its credibility. This relationship pours light on the bigger picture behind the propagation of misinformation. We pave the way for further research based on the methodology described in this paper to create the data set and usage of predictive modeling along with research-based on psychology/mentality of people to understand why fake news spreads much faster than reality.
Optimal Radiometric Calibration for Camera-Display Communication
Jan 08, 2015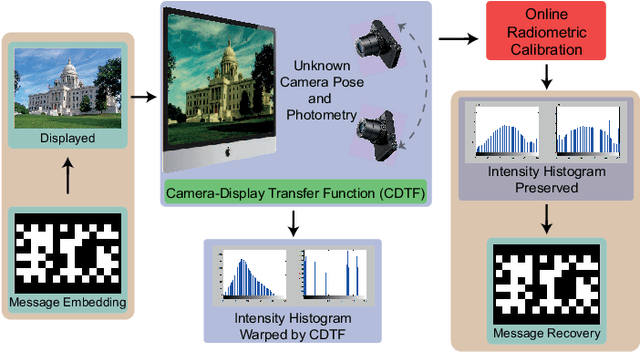
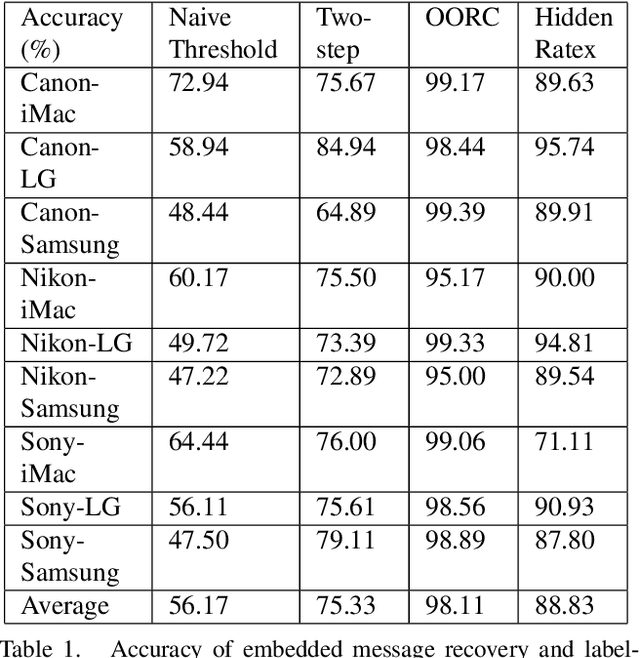
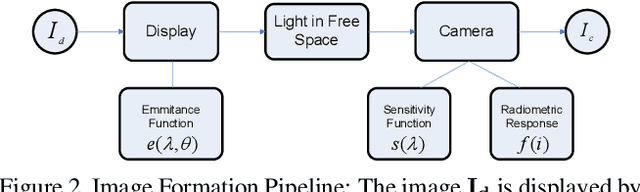
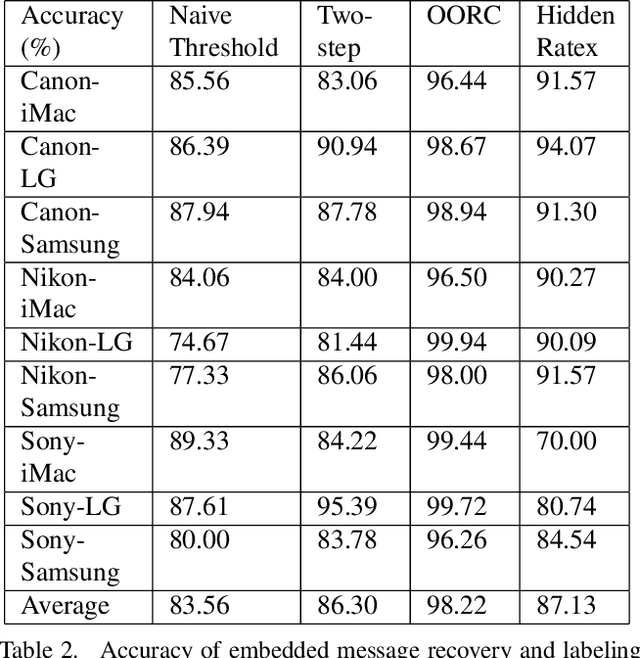
We present a novel method for communicating between a camera and display by embedding and recovering hidden and dynamic information within a displayed image. A handheld camera pointed at the display can receive not only the display image, but also the underlying message. These active scenes are fundamentally different from traditional passive scenes like QR codes because image formation is based on display emittance, not surface reflectance. Detecting and decoding the message requires careful photometric modeling for computational message recovery. Unlike standard watermarking and steganography methods that lie outside the domain of computer vision, our message recovery algorithm uses illumination to optically communicate hidden messages in real world scenes. The key innovation of our approach is an algorithm that performs simultaneous radiometric calibration and message recovery in one convex optimization problem. By modeling the photometry of the system using a camera-display transfer function (CDTF), we derive a physics-based kernel function for support vector machine classification. We demonstrate that our method of optimal online radiometric calibration (OORC) leads to an efficient and robust algorithm for computational messaging between nine commercial cameras and displays.