 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViFiT: Reconstructing Vision Trajectories from IMU and Wi-Fi Fine Time Measurements
Oct 04, 2023Tracking subjects in videos is one of the most widely used functions in camera-based IoT applications such as security surveillance, smart city traffic safety enhancement, vehicle to pedestrian communication and so on. In the computer vision domain, tracking is usually achieved by first detecting subjects with bounding boxes, then associating detected bounding boxes across video frames. For many IoT systems, images captured by cameras are usually sent over the network to be processed at a different site that has more powerful computing resources than edge devices. However, sending entire frames through the network causes significant bandwidth consumption that may exceed the system bandwidth constraints. To tackle this problem, we propose ViFiT, a transformer-based model that reconstructs vision bounding box trajectories from phone data (IMU and Fine Time Measurements). It leverages a transformer ability of better modeling long-term time series data. ViFiT is evaluated on Vi-Fi Dataset, a large-scale multimodal dataset in 5 diverse real world scenes, including indoor and outdoor environments. To fill the gap of proper metrics of jointly capturing the system characteristics of both tracking quality and video bandwidth reduction, we propose a novel evaluation framework dubbed Minimum Required Frames (MRF) and Minimum Required Frames Ratio (MRFR). ViFiT achieves an MRFR of 0.65 that outperforms the state-of-the-art approach for cross-modal reconstruction in LSTM Encoder-Decoder architecture X-Translator of 0.98, resulting in a high frame reduction rate as 97.76%.
ViFi-Loc: Multi-modal Pedestrian Localization using GAN with Camera-Phone Correspondences
Nov 22, 2022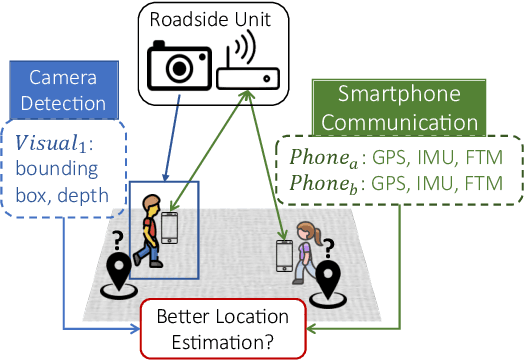
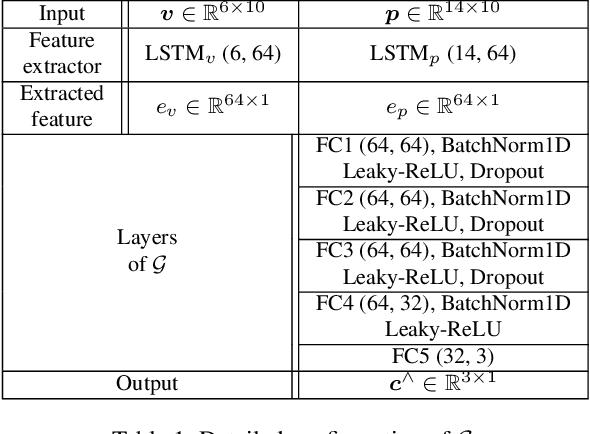
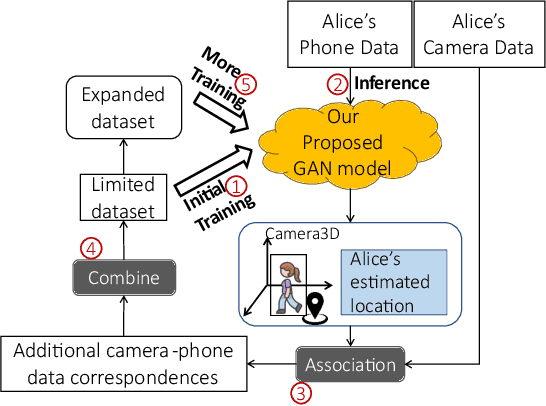

In Smart City and Vehicle-to-Everything (V2X) systems, acquiring pedestrians' accurate locations is crucial to traffic safety. Current systems adopt cameras and wireless sensors to detect and estimate people's locations via sensor fusion. Standard fusion algorithms, however, become inapplicable when multi-modal data is not associated. For example, pedestrians are out of the camera field of view, or data from camera modality is missing. To address this challenge and produce more accurate location estimations for pedestrians, we propose a Generative Adversarial Network (GAN) architecture. During training, it learns the underlying linkage between pedestrians' camera-phone data correspondences. During inference, it generates refined position estimations based only on pedestrians' phone data that consists of GPS, IMU and FTM. Results show that our GAN produces 3D coordinates at 1 to 2 meter localization error across 5 different outdoor scenes. We further show that the proposed model supports self-learning. The generated coordinates can be associated with pedestrian's bounding box coordinates to obtain additional camera-phone data correspondences. This allows automatic data collection during inference. After fine-tuning on the expanded dataset, localization accuracy is improved by up to 26%.
ViFiCon: Vision and Wireless Association Via Self-Supervised Contrastive Learning
Oct 11, 2022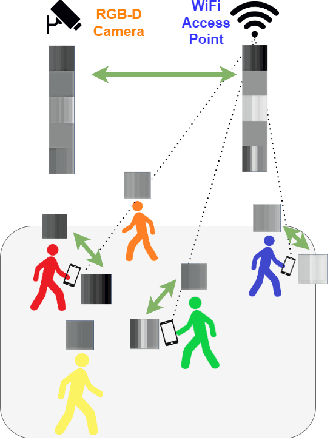

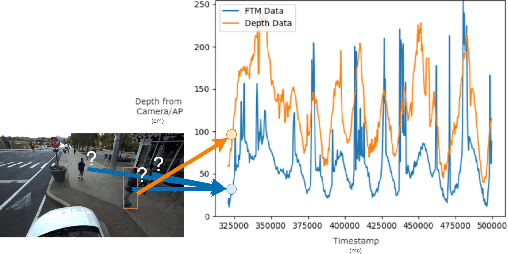

We introduce ViFiCon, a self-supervised contrastive learning scheme which uses synchronized information across vision and wireless modalities to perform cross-modal association. Specifically, the system uses pedestrian data collected from RGB-D camera footage as well as WiFi Fine Time Measurements (FTM) from a user's smartphone device. We represent the temporal sequence by stacking multi-person depth data spatially within a banded image. Depth data from RGB-D (vision domain) is inherently linked with an observable pedestrian, but FTM data (wireless domain) is associated only to a smartphone on the network. To formulate the cross-modal association problem as self-supervised, the network learns a scene-wide synchronization of the two modalities as a pretext task, and then uses that learned representation for the downstream task of associating individual bounding boxes to specific smartphones, i.e. associating vision and wireless information. We use a pre-trained region proposal model on the camera footage and then feed the extrapolated bounding box information into a dual-branch convolutional neural network along with the FTM data. We show that compared to fully supervised SoTA models, ViFiCon achieves high performance vision-to-wireless association, finding which bounding box corresponds to which smartphone device, without hand-labeled association examples for training data.