 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOOSTraj: Out-of-Sight Trajectory Prediction With Vision-Positioning Denoising
Apr 02, 2024Trajectory prediction is fundamental in computer vision and autonomous driving, particularly for understanding pedestrian behavior and enabling proactive decision-making. Existing approaches in this field often assume precise and complete observational data, neglecting the challenges associated with out-of-view objects and the noise inherent in sensor data due to limited camera range, physical obstructions, and the absence of ground truth for denoised sensor data. Such oversights are critical safety concerns, as they can result in missing essential, non-visible objects. To bridge this gap, we present a novel method for out-of-sight trajectory prediction that leverages a vision-positioning technique. Our approach denoises noisy sensor observations in an unsupervised manner and precisely maps sensor-based trajectories of out-of-sight objects into visual trajectories. This method has demonstrated state-of-the-art performance in out-of-sight noisy sensor trajectory denoising and prediction on the Vi-Fi and JRDB datasets. By enhancing trajectory prediction accuracy and addressing the challenges of out-of-sight objects, our work significantly contributes to improving the safety and reliability of autonomous driving in complex environments. Our work represents the first initiative towards Out-Of-Sight Trajectory prediction (OOSTraj), setting a new benchmark for future research. The code is available at \url{https://github.com/Hai-chao-Zhang/OOSTraj}.
SiCP: Simultaneous Individual and Cooperative Perception for 3D Object Detection in Connected and Automated Vehicles
Dec 08, 2023Cooperative perception for connected and automated vehicles is traditionally achieved through the fusion of feature maps from two or more vehicles. However, the absence of feature maps shared from other vehicles can lead to a significant decline in object detection performance for cooperative perception models compared to standalone 3D detection models. This drawback impedes the adoption of cooperative perception as vehicle resources are often insufficient to concurrently employ two perception models. To tackle this issue, we present Simultaneous Individual and Cooperative Perception (SiCP), a generic framework that supports a wide range of the state-of-the-art standalone perception backbones and enhances them with a novel Dual-Perception Network (DP-Net) designed to facilitate both individual and cooperative perception. In addition to its lightweight nature with only 0.13M parameters, DP-Net is robust and retains crucial gradient information during feature map fusion. As demonstrated in a comprehensive evaluation on the OPV2V dataset, thanks to DP-Net, SiCP surpasses state-of-the-art cooperative perception solutions while preserving the performance of standalone perception solutions.
Layout Sequence Prediction From Noisy Mobile Modality
Oct 09, 2023Trajectory prediction plays a vital role in understanding pedestrian movement for applications such as autonomous driving and robotics. Current trajectory prediction models depend on long, complete, and accurately observed sequences from visual modalities. Nevertheless, real-world situations often involve obstructed cameras, missed objects, or objects out of sight due to environmental factors, leading to incomplete or noisy trajectories. To overcome these limitations, we propose LTrajDiff, a novel approach that treats objects obstructed or out of sight as equally important as those with fully visible trajectories. LTrajDiff utilizes sensor data from mobile phones to surmount out-of-sight constraints, albeit introducing new challenges such as modality fusion, noisy data, and the absence of spatial layout and object size information. We employ a denoising diffusion model to predict precise layout sequences from noisy mobile data using a coarse-to-fine diffusion strategy, incorporating the RMS, Siamese Masked Encoding Module, and MFM. Our model predicts layout sequences by implicitly inferring object size and projection status from a single reference timestamp or significantly obstructed sequences. Achieving SOTA results in randomly obstructed experiments and extremely short input experiments, our model illustrates the effectiveness of leveraging noisy mobile data. In summary, our approach offers a promising solution to the challenges faced by layout sequence and trajectory prediction models in real-world settings, paving the way for utilizing sensor data from mobile phones to accurately predict pedestrian bounding box trajectories. To the best of our knowledge, this is the first work that addresses severely obstructed and extremely short layout sequences by combining vision with noisy mobile modality, making it the pioneering work in the field of layout sequence trajectory prediction.
Controlling the Latent Space of GANs through Reinforcement Learning: A Case Study on Task-based Image-to-Image Translation
Jul 26, 2023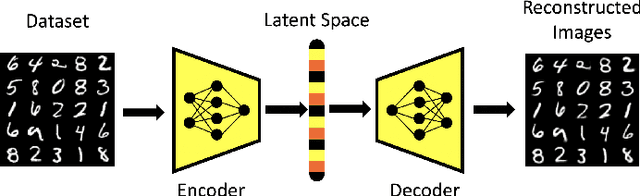
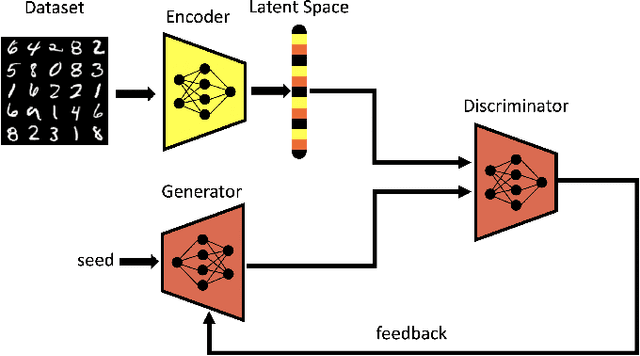
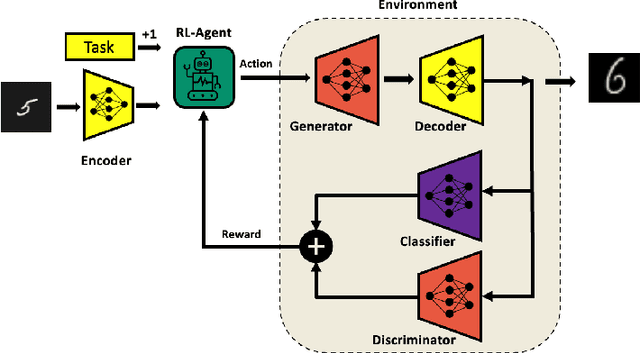

Generative Adversarial Networks (GAN) have emerged as a formidable AI tool to generate realistic outputs based on training datasets. However, the challenge of exerting control over the generation process of GANs remains a significant hurdle. In this paper, we propose a novel methodology to address this issue by integrating a reinforcement learning (RL) agent with a latent-space GAN (l-GAN), thereby facilitating the generation of desired outputs. More specifically, we have developed an actor-critic RL agent with a meticulously designed reward policy, enabling it to acquire proficiency in navigating the latent space of the l-GAN and generating outputs based on specified tasks. To substantiate the efficacy of our approach, we have conducted a series of experiments employing the MNIST dataset, including arithmetic addition as an illustrative task. The outcomes of these experiments serve to validate our methodology. Our pioneering integration of an RL agent with a GAN model represents a novel advancement, holding great potential for enhancing generative networks in the future.
Learning to Localize with Attention: from sparse mmWave channel estimates from a single BS to high accuracy 3D location
Jun 30, 2023One strategy to obtain user location information in a wireless network operating at millimeter wave (mmWave) is based on the exploitation of the geometric relationships between the channel parameters and the user position. These relationships can be easily built from the LoS path and/or first order reflections, but high resolution channel estimates are required for high accuracy. In this paper, we consider a mmWave MIMO system based on a hybrid architecture, and develop first a low complexity channel estimation strategy based on MOMP suitable for high dimensional channels, as those associated to operating with large planar arrays. Then, a deep neural network (DNN) called PathNet is designed to classify the order of the estimated channel paths, so that only the line-of-sight (LOS) path and first order reflections are selected for localization purposes. Next, a 3D localization strategy exploiting the geometry of the environment is developed to operate in both LOS and non-line-of-sight (NLOS) conditions, while considering the unknown clock offset between the transmitter (TX) and the receiver (RX). Finally, a Transformer based network exploiting attention mechanisms called ChanFormer is proposed to refine the initial position estimate obtained from the geometric system of equations that connects user position and channel parameters. Simulation results obtained with realistic vehicular channels generated by ray tracing indicate that sub-meter accuracy (<= 0.45 m) can be achieved for 95% of the users in LOS channels, and for 50% of the users in NLOS conditions.
Deep Masked Graph Matching for Correspondence Identification in Collaborative Perception
Mar 14, 2023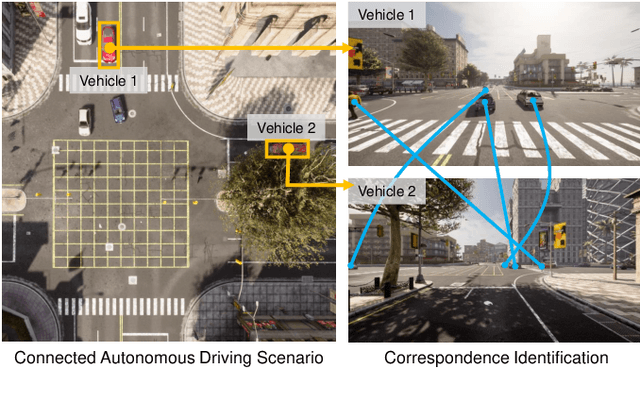
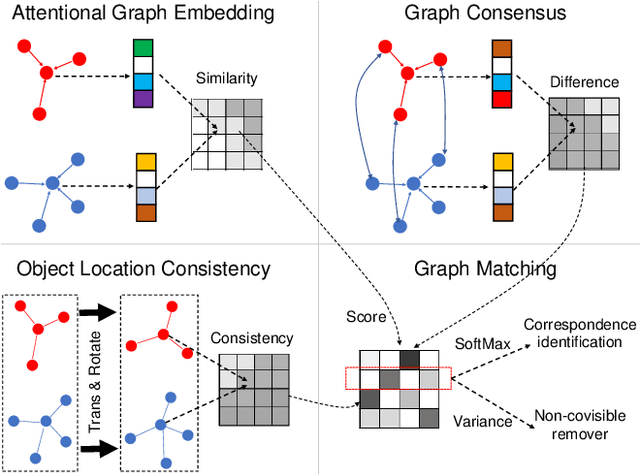


Correspondence identification (CoID) is an essential component for collaborative perception in multi-robot systems, such as connected autonomous vehicles. The goal of CoID is to identify the correspondence of objects observed by multiple robots in their own field of view in order for robots to consistently refer to the same objects. CoID is challenging due to perceptual aliasing, object non-covisibility, and noisy sensing. In this paper, we introduce a novel deep masked graph matching approach to enable CoID and address the challenges. Our approach formulates CoID as a graph matching problem and we design a masked neural network to integrate the multimodal visual, spatial, and GPS information to perform CoID. In addition, we design a new technique to explicitly address object non-covisibility caused by occlusion and the vehicle's limited field of view. We evaluate our approach in a variety of street environments using a high-fidelity simulation that integrates the CARLA and SUMO simulators. The experimental results show that our approach outperforms the previous approaches and achieves state-of-the-art CoID performance in connected autonomous driving applications. Our work is available at: https://github.com/gaopeng5/DMGM.git.
ViFi-Loc: Multi-modal Pedestrian Localization using GAN with Camera-Phone Correspondences
Nov 22, 2022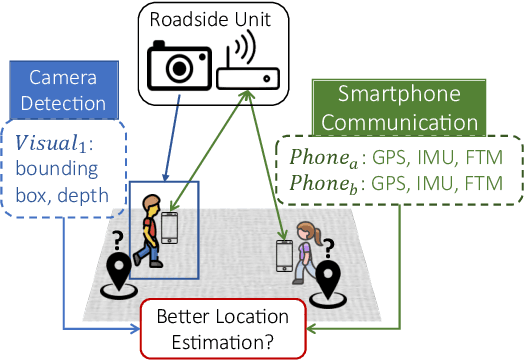
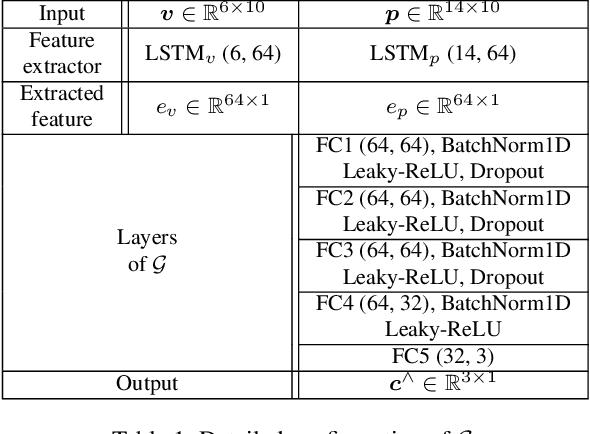
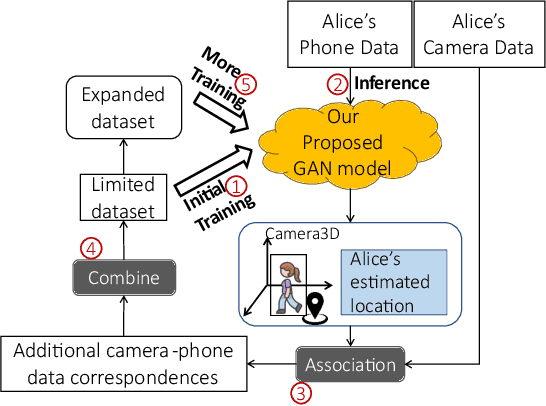

In Smart City and Vehicle-to-Everything (V2X) systems, acquiring pedestrians' accurate locations is crucial to traffic safety. Current systems adopt cameras and wireless sensors to detect and estimate people's locations via sensor fusion. Standard fusion algorithms, however, become inapplicable when multi-modal data is not associated. For example, pedestrians are out of the camera field of view, or data from camera modality is missing. To address this challenge and produce more accurate location estimations for pedestrians, we propose a Generative Adversarial Network (GAN) architecture. During training, it learns the underlying linkage between pedestrians' camera-phone data correspondences. During inference, it generates refined position estimations based only on pedestrians' phone data that consists of GPS, IMU and FTM. Results show that our GAN produces 3D coordinates at 1 to 2 meter localization error across 5 different outdoor scenes. We further show that the proposed model supports self-learning. The generated coordinates can be associated with pedestrian's bounding box coordinates to obtain additional camera-phone data correspondences. This allows automatic data collection during inference. After fine-tuning on the expanded dataset, localization accuracy is improved by up to 26%.
Joint Initial Access and Localization in Millimeter Wave Vehicular Networks: a Hybrid Model/Data Driven Approach
Apr 04, 2022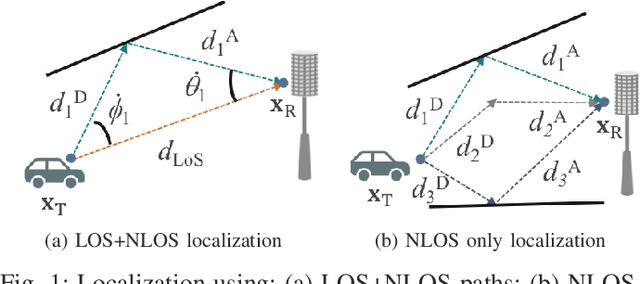
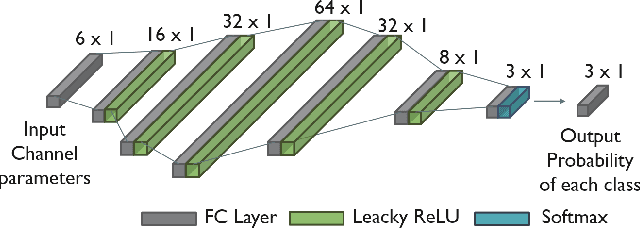

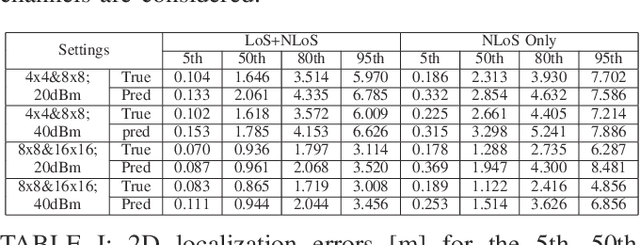
High resolution compressive channel estimation provides information for vehicle localization when a hybrid mmWave MIMO system is considered. Complexity and memory requirements can, however, become a bottleneck when high accuracy localization is required. An additional challenge is the need of path order information to apply the appropriate geometric relationships between the channel path parameters and the vehicle, RSU and scatterers position. In this paper, we propose a low complexity channel estimation strategy of the angle of departure and time difference of arrival based on multidimensional orthogonal matching pursuit. We also design a deep neural network that predicts the order of the channel paths so only the LoS and first order reflections are used for localization. Simulation results obtained with realistic vehicular channels generated by ray tracing show that sub-meter accuracy can be achieved for 50% of the users, without resorting to perfect synchronization assumptions or unfeasible all-digital high resolution MIMO architectures.
Adaptive Neural Network-based OFDM Receivers
Mar 25, 2022
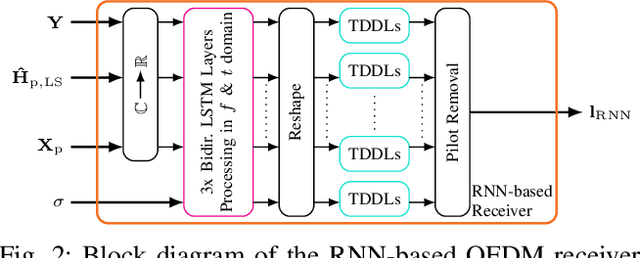
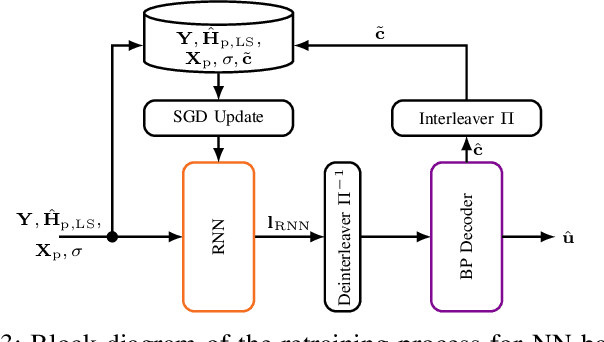
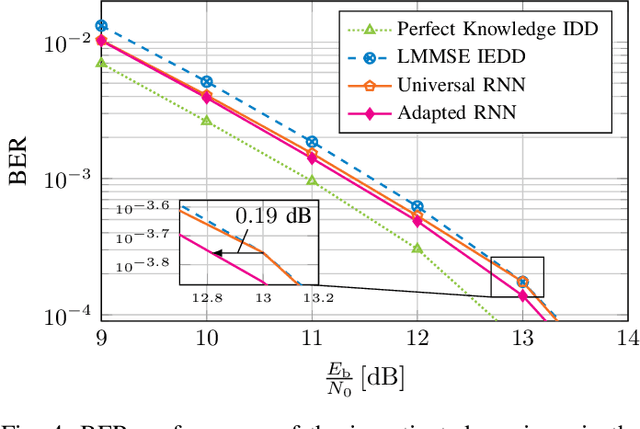
We propose and examine the idea of continuously adapting state-of-the-art neural network (NN)-based orthogonal frequency division multiplex (OFDM) receivers to current channel conditions. This online adaptation via retraining is mainly motivated by two reasons: First, receiver design typically focuses on the universal optimal performance for a wide range of possible channel realizations. However, in actual applications and within short time intervals, only a subset of these channel parameters is likely to occur, as macro parameters, e.g., the maximum channel delay, can assumed to be static. Second, in-the-field alterations like temporal interferences or other conditions out of the originally intended specifications can occur on a practical (real-world) transmission. While conventional (filter-based) systems would require reconfiguration or additional signal processing to cope with these unforeseen conditions, NN-based receivers can learn to mitigate previously unseen effects even after their deployment. For this, we showcase on-the-fly adaption to current channel conditions and temporal alterations solely based on recovered labels from an outer forward error correction (FEC) code without any additional piloting overhead. To underline the flexibility of the proposed adaptive training, we showcase substantial gains for scenarios with static channel macro parameters, for out-ofspecification usage and for interference compensation.
Asynchronous Collaborative Localization by Integrating Spatiotemporal Graph Learning with Model-Based Estimation
Nov 05, 2021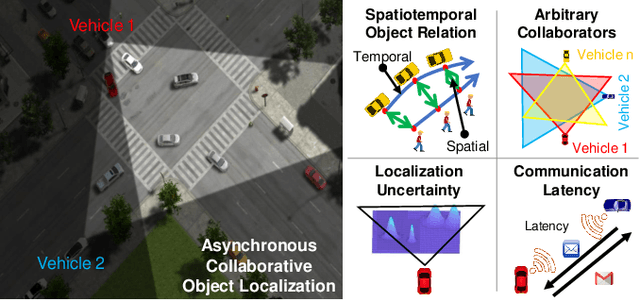
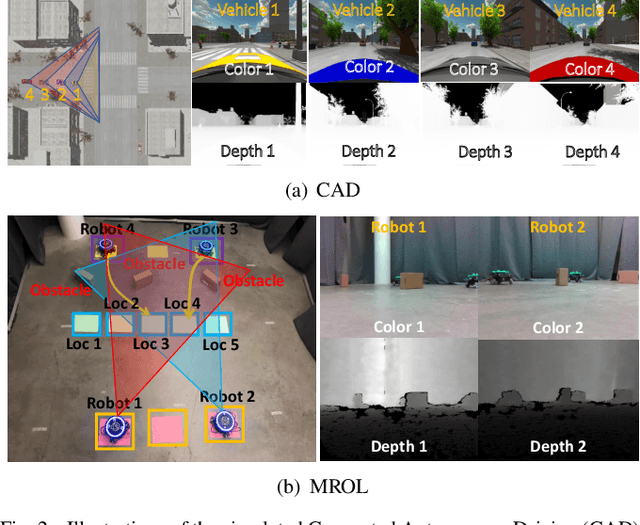
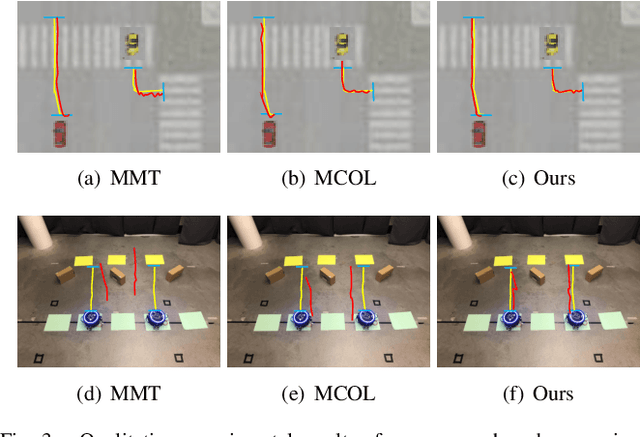
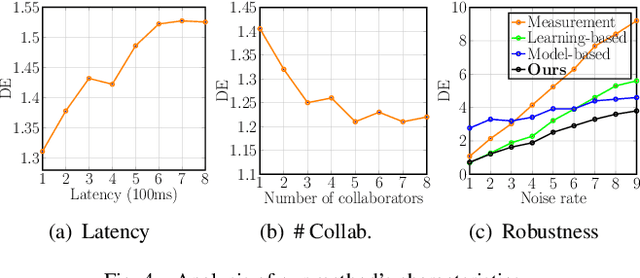
Collaborative localization is an essential capability for a team of robots such as connected vehicles to collaboratively estimate object locations from multiple perspectives with reliant cooperation. To enable collaborative localization, four key challenges must be addressed, including modeling complex relationships between observed objects, fusing observations from an arbitrary number of collaborating robots, quantifying localization uncertainty, and addressing latency of robot communications. In this paper, we introduce a novel approach that integrates uncertainty-aware spatiotemporal graph learning and model-based state estimation for a team of robots to collaboratively localize objects. Specifically, we introduce a new uncertainty-aware graph learning model that learns spatiotemporal graphs to represent historical motions of the objects observed by each robot over time and provides uncertainties in object localization. Moreover, we propose a novel method for integrated learning and model-based state estimation, which fuses asynchronous observations obtained from an arbitrary number of robots for collaborative localization. We evaluate our approach in two collaborative object localization scenarios in simulations and on real robots. Experimental results show that our approach outperforms previous methods and achieves state-of-the-art performance on asynchronous collaborative localization.