 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Masked Graph Matching for Correspondence Identification in Collaborative Perception
Mar 14, 2023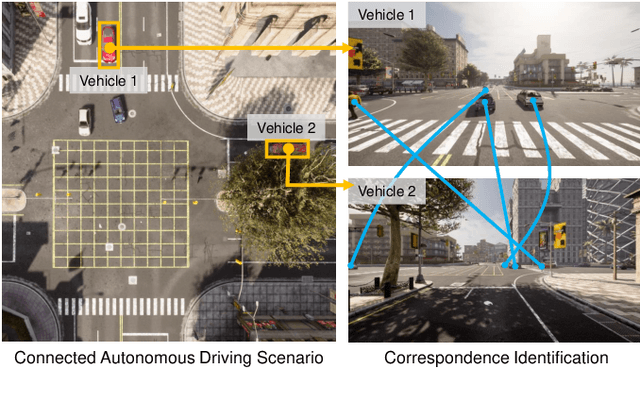
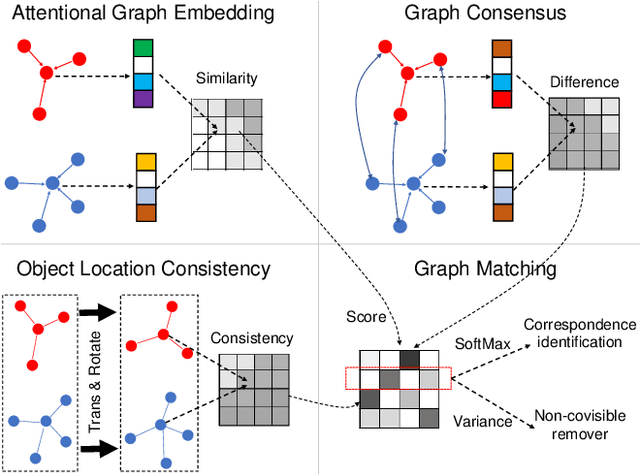


Correspondence identification (CoID) is an essential component for collaborative perception in multi-robot systems, such as connected autonomous vehicles. The goal of CoID is to identify the correspondence of objects observed by multiple robots in their own field of view in order for robots to consistently refer to the same objects. CoID is challenging due to perceptual aliasing, object non-covisibility, and noisy sensing. In this paper, we introduce a novel deep masked graph matching approach to enable CoID and address the challenges. Our approach formulates CoID as a graph matching problem and we design a masked neural network to integrate the multimodal visual, spatial, and GPS information to perform CoID. In addition, we design a new technique to explicitly address object non-covisibility caused by occlusion and the vehicle's limited field of view. We evaluate our approach in a variety of street environments using a high-fidelity simulation that integrates the CARLA and SUMO simulators. The experimental results show that our approach outperforms the previous approaches and achieves state-of-the-art CoID performance in connected autonomous driving applications. Our work is available at: https://github.com/gaopeng5/DMGM.git.
Asynchronous Collaborative Localization by Integrating Spatiotemporal Graph Learning with Model-Based Estimation
Nov 05, 2021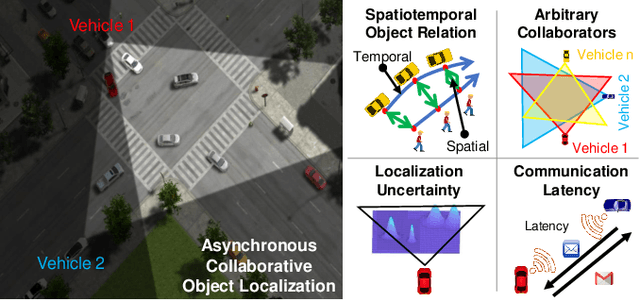
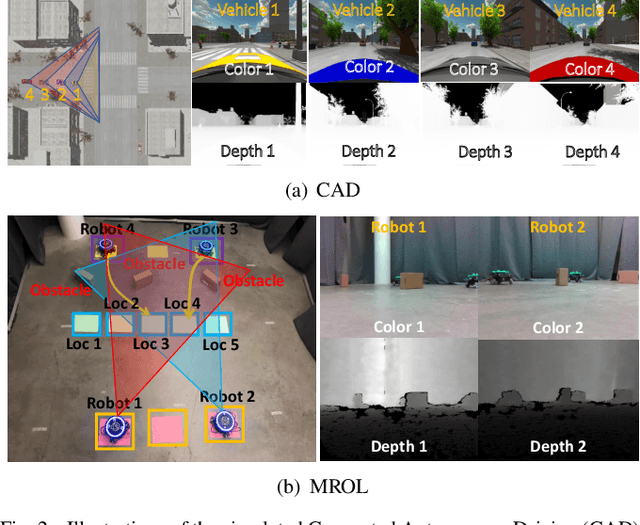
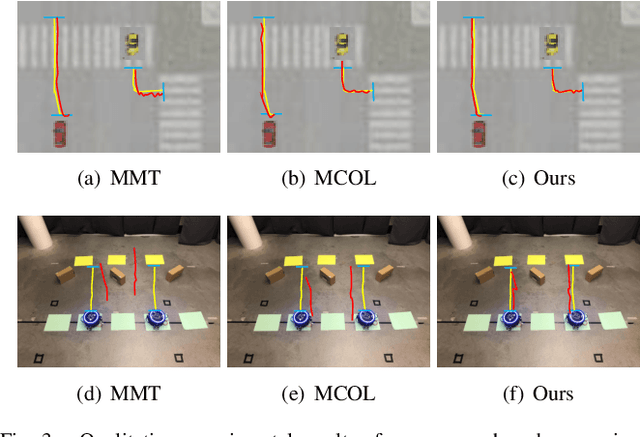
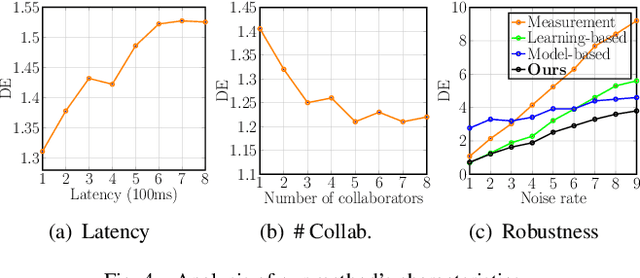
Collaborative localization is an essential capability for a team of robots such as connected vehicles to collaboratively estimate object locations from multiple perspectives with reliant cooperation. To enable collaborative localization, four key challenges must be addressed, including modeling complex relationships between observed objects, fusing observations from an arbitrary number of collaborating robots, quantifying localization uncertainty, and addressing latency of robot communications. In this paper, we introduce a novel approach that integrates uncertainty-aware spatiotemporal graph learning and model-based state estimation for a team of robots to collaboratively localize objects. Specifically, we introduce a new uncertainty-aware graph learning model that learns spatiotemporal graphs to represent historical motions of the objects observed by each robot over time and provides uncertainties in object localization. Moreover, we propose a novel method for integrated learning and model-based state estimation, which fuses asynchronous observations obtained from an arbitrary number of robots for collaborative localization. We evaluate our approach in two collaborative object localization scenarios in simulations and on real robots. Experimental results show that our approach outperforms previous methods and achieves state-of-the-art performance on asynchronous collaborative localization.
Simultaneous Learning from Human Pose and Object Cues for Real-Time Activity Recognition
Mar 26, 2020
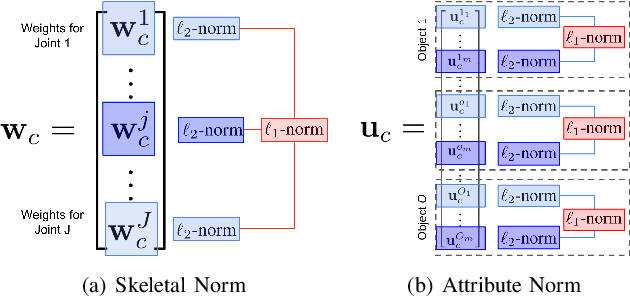


Real-time human activity recognition plays an essential role in real-world human-centered robotics applications, such as assisted living and human-robot collaboration. Although previous methods based on skeletal data to encode human poses showed promising results on real-time activity recognition, they lacked the capability to consider the context provided by objects within the scene and in use by the humans, which can provide a further discriminant between human activity categories. In this paper, we propose a novel approach to real-time human activity recognition, through simultaneously learning from observations of both human poses and objects involved in the human activity. We formulate human activity recognition as a joint optimization problem under a unified mathematical framework, which uses a regression-like loss function to integrate human pose and object cues and defines structured sparsity-inducing norms to identify discriminative body joints and object attributes. To evaluate our method, we perform extensive experiments on two benchmark datasets and a physical robot in a home assistance setting. Experimental results have shown that our method outperforms previous methods and obtains real-time performance for human activity recognition with a processing speed of 10^4 Hz.