 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVOLVE: Emotion and Visual Output Learning via LLM Evaluation
Dec 30, 2024



Human acceptance of social robots is greatly effected by empathy and perceived understanding. This necessitates accurate and flexible responses to various input data from the user. While systems such as this can become increasingly complex as more states or response types are included, new research in the application of large language models towards human-robot interaction has allowed for more streamlined perception and reaction pipelines. LLM-selected actions and emotional expressions can help reinforce the realism of displayed empathy and allow for improved communication between the robot and user. Beyond portraying empathy in spoken or written responses, this shows the possibilities of using LLMs in actuated, real world scenarios. In this work we extend research in LLM-driven nonverbal behavior for social robots by considering more open-ended emotional response selection leveraging new advances in vision-language models, along with emotionally aligned motion and color pattern selections that strengthen conveyance of meaning and empathy.
Towards Human-Robot Teaming through Augmented Reality and Gaze-Based Attention Control
Aug 23, 2024

Robots are now increasingly integrated into various real world applications and domains. In these new domains, robots are mostly employed to improve, in some ways, the work done by humans. So, the need for effective Human-Robot Teaming (HRT) capabilities grows. These capabilities usually involve the dynamic collaboration between humans and robots at different levels of involvement, leveraging the strengths of both to efficiently navigate complex situations. Crucial to this collaboration is the ability of robotic systems to adjust their level of autonomy to match the needs of the task and the human team members. This paper introduces a system designed to control attention using HRT through the use of ground robots and augmented reality (AR) technology. Traditional methods of controlling attention, such as pointing, touch, and voice commands, sometimes fall short in precision and subtlety. Our system overcomes these limitations by employing AR headsets to display virtual visual markers. These markers act as dynamic cues to attract and shift human attention seamlessly, irrespective of the robot's physical location.
Compositional Zero-Shot Learning for Attribute-Based Object Reference in Human-Robot Interaction
Dec 21, 2023Language-enabled robots have been widely studied over the past years to enable natural human-robot interaction and teaming in various real-world applications. Language-enabled robots must be able to comprehend referring expressions to identify a particular object from visual perception using a set of referring attributes extracted from natural language. However, visual observations of an object may not be available when it is referred to, and the number of objects and attributes may also be unbounded in open worlds. To address the challenges, we implement an attribute-based compositional zero-shot learning method that uses a list of attributes to perform referring expression comprehension in open worlds. We evaluate the approach on two datasets including the MIT-States and the Clothing 16K. The preliminary experimental results show that our implemented approach allows a robot to correctly identify the objects referred to by human commands.
Representing Multi-Robot Structure through Multimodal Graph Embedding for the Selection of Robot Teams
Apr 07, 2020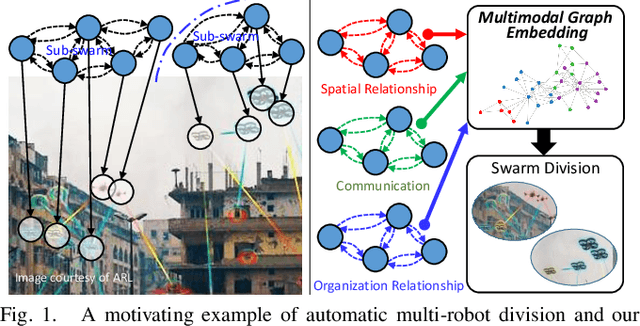

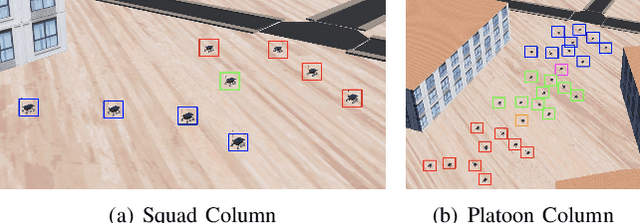
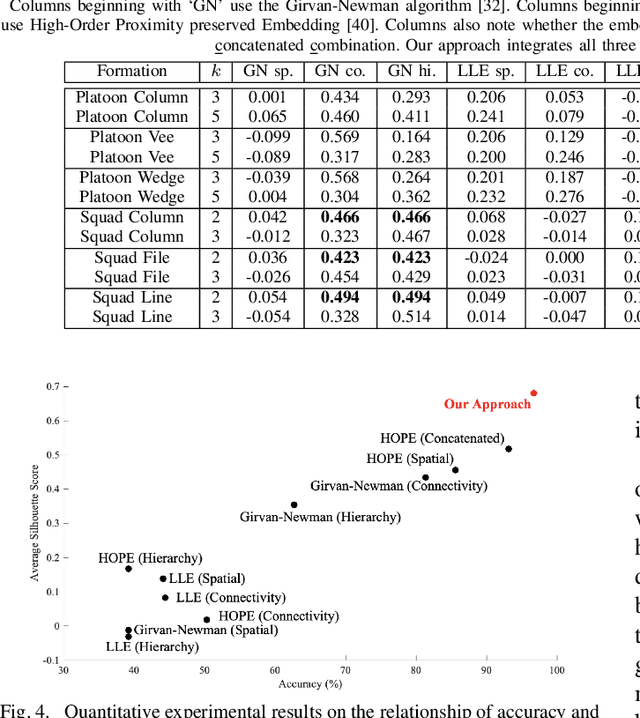
Multi-robot systems of increasing size and complexity are used to solve large-scale problems, such as area exploration and search and rescue. A key decision in human-robot teaming is dividing a multi-robot system into teams to address separate issues or to accomplish a task over a large area. In order to address the problem of selecting teams in a multi-robot system, we propose a new multimodal graph embedding method to construct a unified representation that fuses multiple information modalities to describe and divide a multi-robot system. The relationship modalities are encoded as directed graphs that can encode asymmetrical relationships, which are embedded into a unified representation for each robot. Then, the constructed multimodal representation is used to determine teams based upon unsupervised learning. We perform experiments to evaluate our approach on expert-defined team formations, large-scale simulated multi-robot systems, and a system of physical robots. Experimental results show that our method successfully decides correct teams based on the multifaceted internal structures describing multi-robot systems, and outperforms baseline methods based upon only one mode of information, as well as other graph embedding-based division methods.
Simultaneous Learning from Human Pose and Object Cues for Real-Time Activity Recognition
Mar 26, 2020
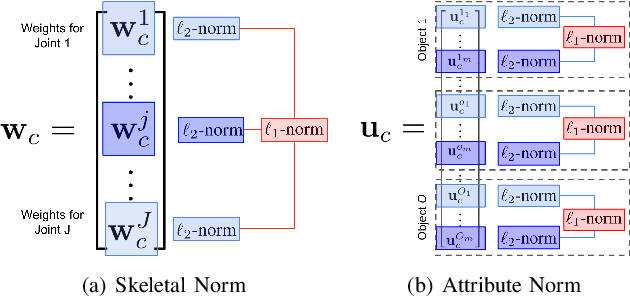


Real-time human activity recognition plays an essential role in real-world human-centered robotics applications, such as assisted living and human-robot collaboration. Although previous methods based on skeletal data to encode human poses showed promising results on real-time activity recognition, they lacked the capability to consider the context provided by objects within the scene and in use by the humans, which can provide a further discriminant between human activity categories. In this paper, we propose a novel approach to real-time human activity recognition, through simultaneously learning from observations of both human poses and objects involved in the human activity. We formulate human activity recognition as a joint optimization problem under a unified mathematical framework, which uses a regression-like loss function to integrate human pose and object cues and defines structured sparsity-inducing norms to identify discriminative body joints and object attributes. To evaluate our method, we perform extensive experiments on two benchmark datasets and a physical robot in a home assistance setting. Experimental results have shown that our method outperforms previous methods and obtains real-time performance for human activity recognition with a processing speed of 10^4 Hz.
Enabling Intuitive Human-Robot Teaming Using Augmented Reality and Gesture Control
Sep 13, 2019

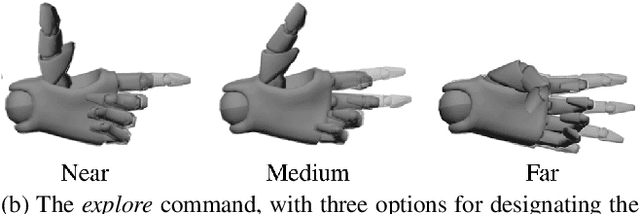

Human-robot teaming offers great potential because of the opportunities to combine strengths of heterogeneous agents. However, one of the critical challenges in realizing an effective human-robot team is efficient information exchange - both from the human to the robot as well as from the robot to the human. In this work, we present and analyze an augmented reality-enabled, gesture-based system that supports intuitive human-robot teaming through improved information exchange. Our proposed system requires no external instrumentation aside from human-wearable devices and shows promise of real-world applicability for service-oriented missions. Additionally, we present preliminary results from a pilot study with human participants, and highlight lessons learned and open research questions that may help direct future development, fielding, and experimentation of autonomous HRI systems.
* Proceedings of the Artificial Intelligence for Human-Robot Interaction AAAI Symposium Series (AI-HRI 2019)
Simultaneous Feature and Body-Part Learning for Real-Time Robot Awareness of Human Behaviors
Feb 24, 2017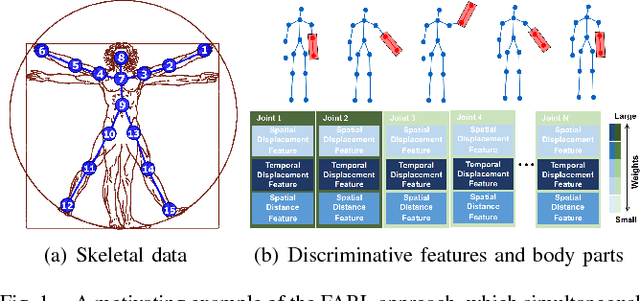


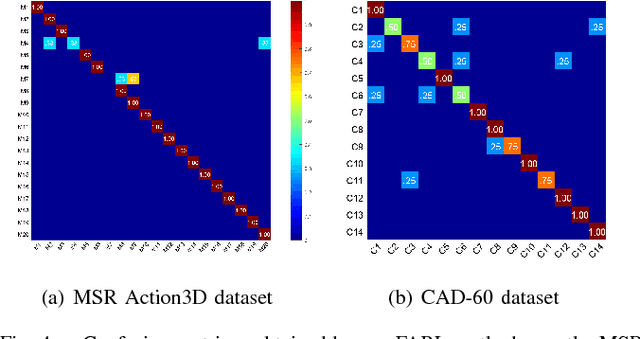
Robot awareness of human actions is an essential research problem in robotics with many important real-world applications, including human-robot collaboration and teaming. Over the past few years, depth sensors have become a standard device widely used by intelligent robots for 3D perception, which can also offer human skeletal data in 3D space. Several methods based on skeletal data were designed to enable robot awareness of human actions with satisfactory accuracy. However, previous methods treated all body parts and features equally important, without the capability to identify discriminative body parts and features. In this paper, we propose a novel simultaneous Feature And Body-part Learning (FABL) approach that simultaneously identifies discriminative body parts and features, and efficiently integrates all available information together to enable real-time robot awareness of human behaviors. We formulate FABL as a regression-like optimization problem with structured sparsity-inducing norms to model interrelationships of body parts and features. We also develop an optimization algorithm to solve the formulated problem, which possesses a theoretical guarantee to find the optimal solution. To evaluate FABL, three experiments were performed using public benchmark datasets, including the MSR Action3D and CAD-60 datasets, as well as a Baxter robot in practical assistive living applications. Experimental results show that our FABL approach obtains a high recognition accuracy with a processing speed of the order-of-magnitude of 10e4 Hz, which makes FABL a promising method to enable real-time robot awareness of human behaviors in practical robotics applications.
Self-Reflective Risk-Aware Artificial Cognitive Modeling for Robot Response to Human Behaviors
May 16, 2016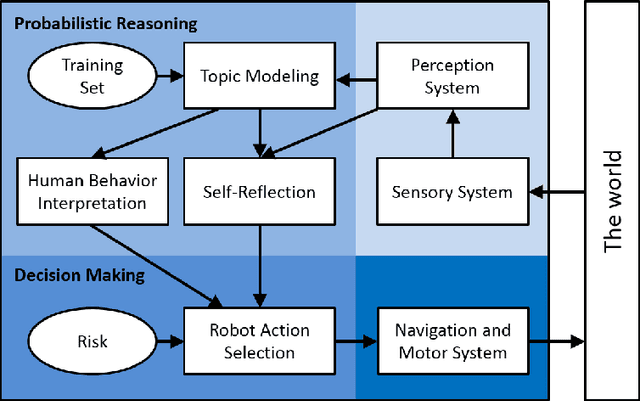
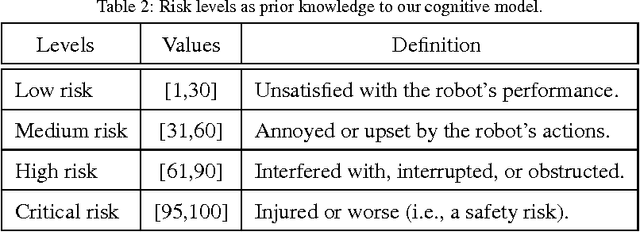
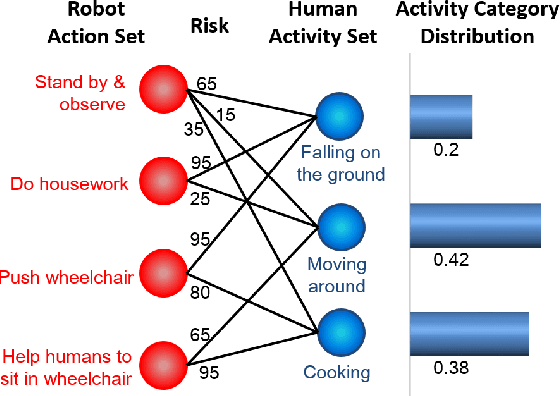

In order for cooperative robots ("co-robots") to respond to human behaviors accurately and efficiently in human-robot collaboration, interpretation of human actions, awareness of new situations, and appropriate decision making are all crucial abilities for co-robots. For this purpose, the human behaviors should be interpreted by co-robots in the same manner as human peers. To address this issue, a novel interpretability indicator is introduced so that robot actions are appropriate to the current human behaviors. In addition, the complete consideration of all potential situations of a robot's environment is nearly impossible in real-world applications, making it difficult for the co-robot to act appropriately and safely in new scenarios. This is true even when the pretrained model is highly accurate in a known situation. For effective and safe teaming with humans, we introduce a new generalizability indicator that allows a co-robot to self-reflect and reason about when an observation falls outside the co-robot's learned model. Based on topic modeling and two novel indicators, we propose a new Self-reflective Risk-aware Artificial Cognitive (SRAC) model. The co-robots are able to consider action risks and identify new situations so that better decisions can be made. Experiments both using real-world datasets and on physical robots suggest that our SRAC model significantly outperforms the traditional methodology and enables better decision making in response to human activities.