 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoIQ: An Ensemble Framework for Automatic Assessment of Geometric Distortion in Prostate Diffusion-Weighted Imaging
May 29, 2026Geometric distortion in prostate diffusion-weighted imaging (DWI) can impair lesion localization and reduce the reliability of MRI-based clinical assessment. We propose AutoIQ, an ensemble machine learning framework for automatic quantification and classification of DWI geometric distortion severity. A total of 140 retrospective prostate biparametric MRI examinations were analyzed, including 33 scans with severe distortion requiring repeat acquisition and 107 scans with acceptable distortion based on expert radiologist assessment. AutoIQ combines two complementary distortion quantification strategies: a segmentation-based method measuring prostate boundary mismatch between T2-weighted imaging (T2WI) and DWI, and a registration-based method estimating deformation magnitude after DWI-to-T2WI alignment. The resulting distortion scores were used to train individual classifiers and a logistic-regression ensemble model. Both computational methods significantly differentiated severe from acceptable distortion cases (p < 0.001). On an independent test set, the ensemble model achieved an accuracy of 0.95, F1-score of 0.93, and AUC of 0.98, outperforming individual models. These results suggest that AutoIQ can provide automated, quantitative quality assessment for prostate DWI and may help identify scans that require repeat acquisition.
Swimming Under Constraints: A Safe Reinforcement Learning Framework for Quadrupedal Bio-Inspired Propulsion
Mar 04, 2026Bio-inspired aquatic propulsion offers high thrust and maneuverability but is prone to destabilizing forces such as lift fluctuations, which are further amplified by six-degree-of-freedom (6-DoF) fluid coupling. We formulate quadrupedal swimming as a constrained optimization problem that maximizes forward thrust while minimizing destabilizing fluctuations. Our proposed framework, Accelerated Constrained Proximal Policy Optimization with a PID-regulated Lagrange multiplier (ACPPO-PID), enforces constraints with a PID-regulated Lagrange multiplier, accelerates learning via conditional asymmetric clipping, and stabilizes updates through cycle-wise geometric aggregation. Initialized with imitation learning and refined through on-hardware towing-tank experiments, ACPPO-PID produces control policies that transfer effectively to quadrupedal free-swimming trials. Results demonstrate improved thrust efficiency, reduced destabilizing forces, and faster convergence compared with state-of-the-art baselines, underscoring the importance of constraint-aware safe RL for robust and generalizable bio-inspired locomotion in complex fluid environments.
The Quantization Trap: Breaking Linear Scaling Laws in Multi-Hop Reasoning
Feb 14, 2026Neural scaling laws provide a predictable recipe for AI advancement: reducing numerical precision should linearly improve computational efficiency and energy profile (E proportional to bits). In this paper, we demonstrate that this scaling law breaks in the context of multi-hop reasoning. We reveal a 'quantization trap' where reducing precision from 16-bit to 8/4-bit paradoxically increases more net energy consumption while degrading reasoning accuracy. We provide a rigorous theoretical decomposition that attributes this failure to hardware casting overhead, the hidden latency cost of dequantization kernels, which becomes a dominant bottleneck in sequential reasoning chains, as well as to a sequential energy amortization failure. As a result, scaling law breaking is unavoidable in practice. Our findings suggest that the industry's "smaller-is-better" heuristic is mathematically counterproductive for complex reasoning tasks.
Causal World Modeling for Robot Control
Jan 29, 2026This work highlights that video world modeling, alongside vision-language pre-training, establishes a fresh and independent foundation for robot learning. Intuitively, video world models provide the ability to imagine the near future by understanding the causality between actions and visual dynamics. Inspired by this, we introduce LingBot-VA, an autoregressive diffusion framework that learns frame prediction and policy execution simultaneously. Our model features three carefully crafted designs: (1) a shared latent space, integrating vision and action tokens, driven by a Mixture-of-Transformers (MoT) architecture, (2) a closed-loop rollout mechanism, allowing for ongoing acquisition of environmental feedback with ground-truth observations, (3) an asynchronous inference pipeline, parallelizing action prediction and motor execution to support efficient control. We evaluate our model on both simulation benchmarks and real-world scenarios, where it shows significant promise in long-horizon manipulation, data efficiency in post-training, and strong generalizability to novel configurations. The code and model are made publicly available to facilitate the community.
Omni-LIVO: Robust RGB-Colored Multi-Camera Visual-Inertial-LiDAR Odometry via Photometric Migration and ESIKF Fusion
Sep 19, 2025



Wide field-of-view (FoV) LiDAR sensors provide dense geometry across large environments, but most existing LiDAR-inertial-visual odometry (LIVO) systems rely on a single camera, leading to limited spatial coverage and degraded robustness. We present Omni-LIVO, the first tightly coupled multi-camera LIVO system that bridges the FoV mismatch between wide-angle LiDAR and conventional cameras. Omni-LIVO introduces a Cross-View direct tracking strategy that maintains photometric consistency across non-overlapping views, and extends the Error-State Iterated Kalman Filter (ESIKF) with multi-view updates and adaptive covariance weighting. The system is evaluated on public benchmarks and our custom dataset, showing improved accuracy and robustness over state-of-the-art LIVO, LIO, and visual-inertial baselines. Code and dataset will be released upon publication.
Learn to Swim: Data-Driven LSTM Hydrodynamic Model for Quadruped Robot Gait Optimization
May 06, 2025



This paper presents a Long Short-Term Memory network-based Fluid Experiment Data-Driven model (FED-LSTM) for predicting unsteady, nonlinear hydrodynamic forces on the underwater quadruped robot we constructed. Trained on experimental data from leg force and body drag tests conducted in both a recirculating water tank and a towing tank, FED-LSTM outperforms traditional Empirical Formulas (EF) commonly used for flow prediction over flat surfaces. The model demonstrates superior accuracy and adaptability in capturing complex fluid dynamics, particularly in straight-line and turning-gait optimizations via the NSGA-II algorithm. FED-LSTM reduces deflection errors during straight-line swimming and improves turn times without increasing the turning radius. Hardware experiments further validate the model's precision and stability over EF. This approach provides a robust framework for enhancing the swimming performance of legged robots, laying the groundwork for future advances in underwater robotic locomotion.
Molecular topological deep learning for polymer property prediction
Oct 07, 2024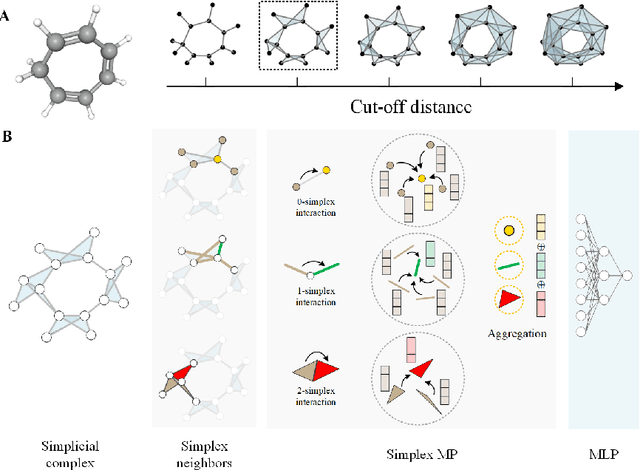
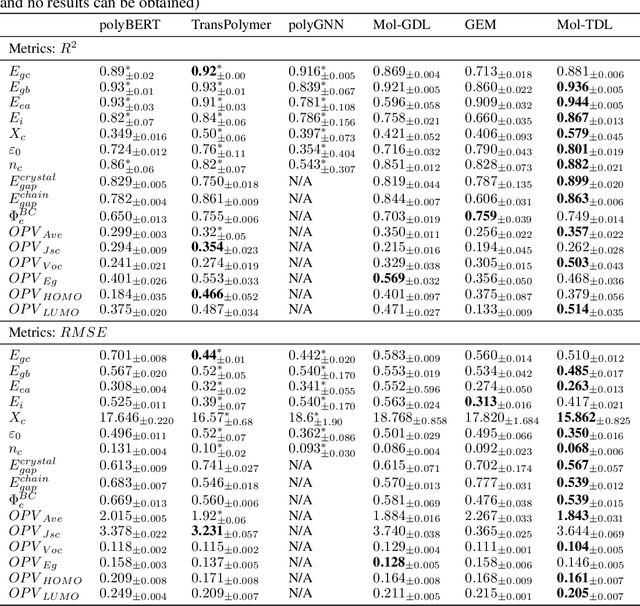
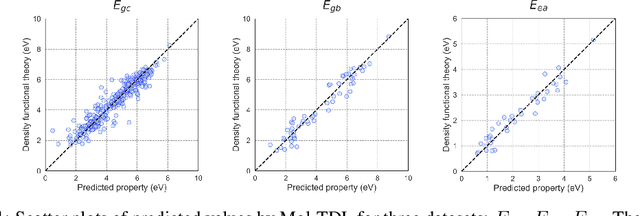
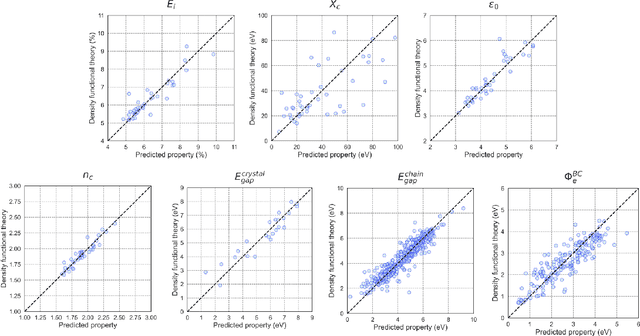
Accurate and efficient prediction of polymer properties is of key importance for polymer design. Traditional experimental tools and density function theory (DFT)-based simulations for polymer property evaluation, are both expensive and time-consuming. Recently, a gigantic amount of graph-based molecular models have emerged and demonstrated huge potential in molecular data analysis. Even with the great progresses, these models tend to ignore the high-order and mutliscale information within the data. In this paper, we develop molecular topological deep learning (Mol-TDL) for polymer property analysis. Our Mol-TDL incorporates both high-order interactions and multiscale properties into topological deep learning architecture. The key idea is to represent polymer molecules as a series of simplicial complices at different scales and build up simplical neural networks accordingly. The aggregated information from different scales provides a more accurate prediction of polymer molecular properties.
Learning Adaptive Hydrodynamic Models Using Neural ODEs in Complex Conditions
Oct 01, 2024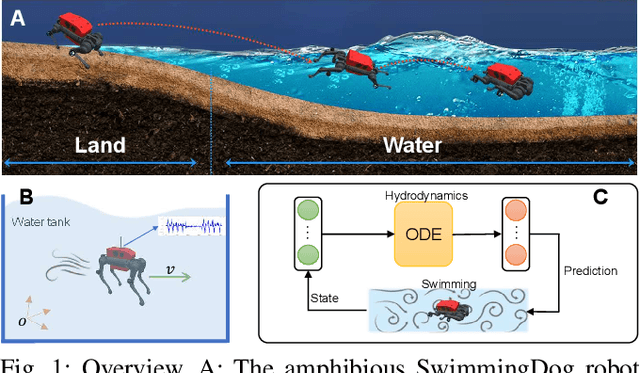
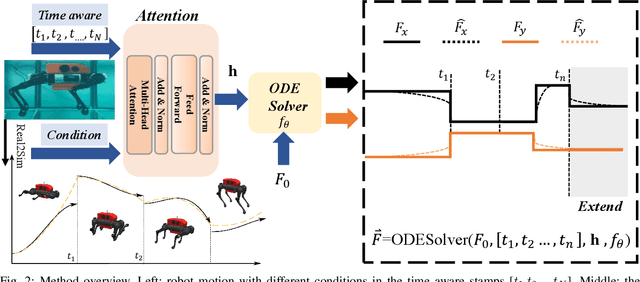


Reinforcement learning-based quadruped robots excel across various terrains but still lack the ability to swim in water due to the complex underwater environment. This paper presents the development and evaluation of a data-driven hydrodynamic model for amphibious quadruped robots, aiming to enhance their adaptive capabilities in complex and dynamic underwater environments. The proposed model leverages Neural Ordinary Differential Equations (ODEs) combined with attention mechanisms to accurately process and interpret real-time sensor data. The model enables the quadruped robots to understand and predict complex environmental patterns, facilitating robust decision-making strategies. We harness real-time sensor data, capturing various environmental and internal state parameters to train and evaluate our model. A significant focus of our evaluation involves testing the quadruped robot's performance across different hydrodynamic conditions and assessing its capabilities at varying speeds and fluid dynamic conditions. The outcomes suggest that the model can effectively learn and adapt to varying conditions, enabling the prediction of force states and enhancing autonomous robotic behaviors in various practical scenarios.
Range Resolution Enhanced Method with Spectral Properties for Hyperspectral Lidar
Mar 03, 2023Waveform decomposition is needed as a first step in the extraction of various types of geometric and spectral information from hyperspectral full-waveform LiDAR echoes. We present a new approach to deal with the "Pseudo-monopulse" waveform formed by the overlapped waveforms from multi-targets when they are very close. We use one single skew-normal distribution (SND) model to fit waveforms of all spectral channels first and count the geometric center position distribution of the echoes to decide whether it contains multi-targets. The geometric center position distribution of the "Pseudo-monopulse" presents aggregation and asymmetry with the change of wavelength, while such an asymmetric phenomenon cannot be found from the echoes of the single target. Both theoretical and experimental data verify the point. Based on such observation, we further propose a hyperspectral waveform decomposition method utilizing the SND mixture model with: 1) initializing new waveform component parameters and their ranges based on the distinction of the three characteristics (geometric center position, pulse width, and skew-coefficient) between the echo and fitted SND waveform and 2) conducting single-channel waveform decomposition for all channels and 3) setting thresholds to find outlier channels based on statistical parameters of all single-channel decomposition results (the standard deviation and the means of geometric center position) and 4) re-conducting single-channel waveform decomposition for these outlier channels. The proposed method significantly improves the range resolution from 60cm to 5cm at most for a 4ns width laser pulse and represents the state-of-the-art in "Pseudo-monopulse" waveform decomposition.
Multisensory Omni-directional Long-term Place Recognition: Benchmark Dataset and Analysis
Apr 18, 2017
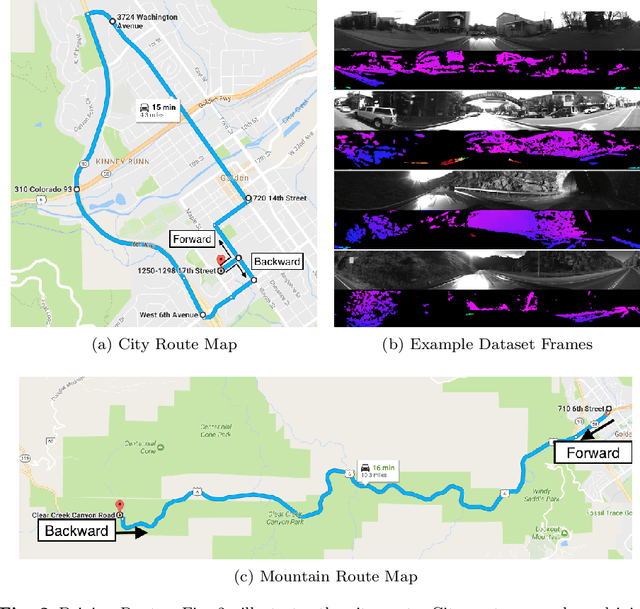
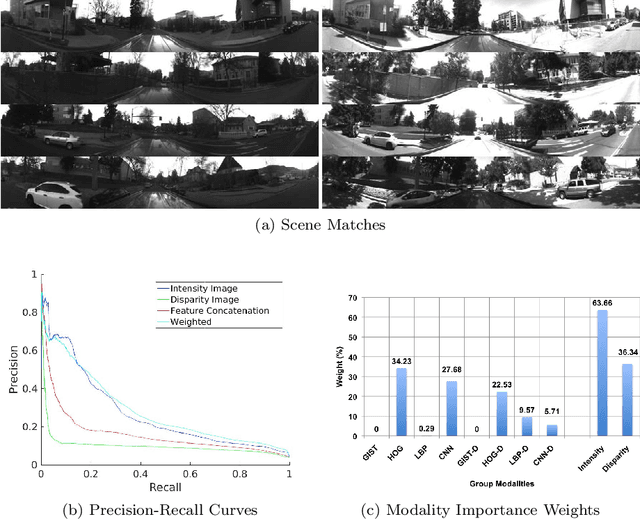
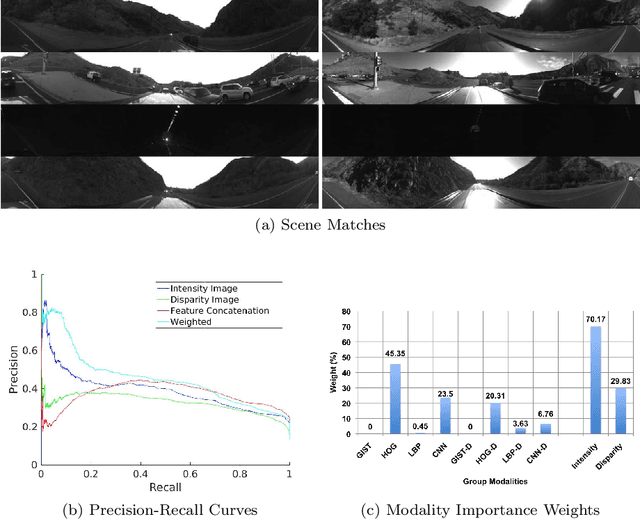
Recognizing a previously visited place, also known as place recognition (or loop closure detection) is the key towards fully autonomous mobile robots and self-driving vehicle navigation. Augmented with various Simultaneous Localization and Mapping techniques (SLAM), loop closure detection allows for incremental pose correction and can bolster efficient and accurate map creation. However, repeated and similar scenes (perceptual aliasing) and long term appearance changes (e.g. weather variations) are major challenges for current place recognition algorithms. We introduce a new dataset Multisensory Omnidirectional Long-term Place recognition (MOLP) comprising omnidirectional intensity and disparity images. This dataset presents many of the challenges faced by outdoor mobile robots and current place recognition algorithms. Using MOLP dataset, we formulate the place recognition problem as a regularized sparse convex optimization problem. We conclude that information extracted from intensity image is superior to disparity image in isolating discriminative features for successful long term place recognition. Furthermore, when these discriminative features are extracted from an omnidirectional vision sensor, a robust bidirectional loop closure detection approach is established, allowing mobile robots to close the loop, regardless of the difference in the direction when revisiting a place.