 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Zero-Shot Learning for Attribute-Based Object Reference in Human-Robot Interaction
Dec 21, 2023Language-enabled robots have been widely studied over the past years to enable natural human-robot interaction and teaming in various real-world applications. Language-enabled robots must be able to comprehend referring expressions to identify a particular object from visual perception using a set of referring attributes extracted from natural language. However, visual observations of an object may not be available when it is referred to, and the number of objects and attributes may also be unbounded in open worlds. To address the challenges, we implement an attribute-based compositional zero-shot learning method that uses a list of attributes to perform referring expression comprehension in open worlds. We evaluate the approach on two datasets including the MIT-States and the Clothing 16K. The preliminary experimental results show that our implemented approach allows a robot to correctly identify the objects referred to by human commands.
Asynchronous Collaborative Localization by Integrating Spatiotemporal Graph Learning with Model-Based Estimation
Nov 05, 2021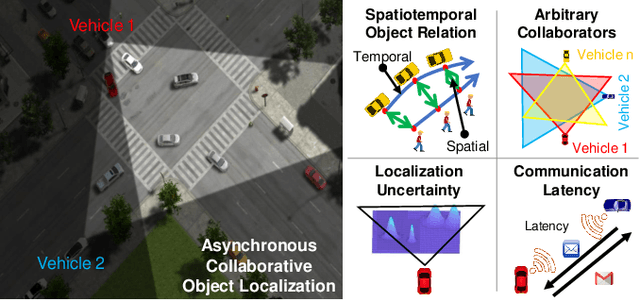
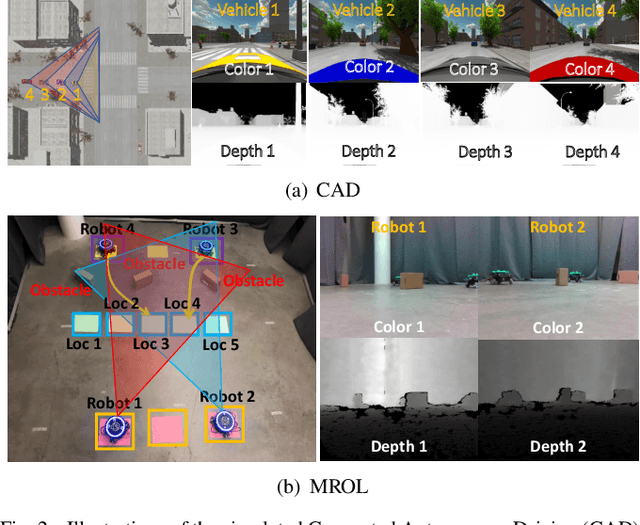
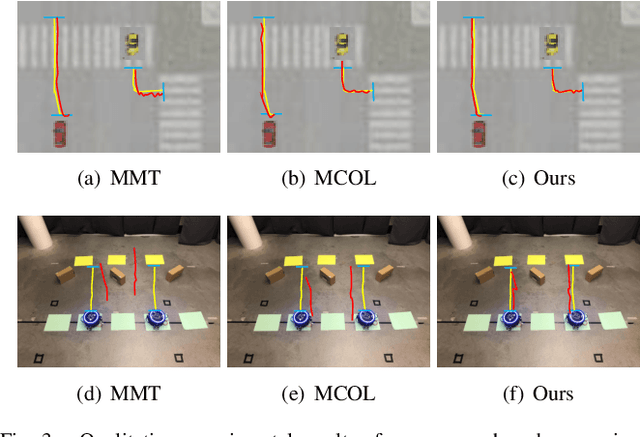
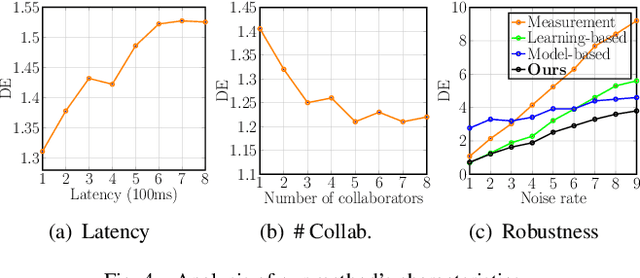
Collaborative localization is an essential capability for a team of robots such as connected vehicles to collaboratively estimate object locations from multiple perspectives with reliant cooperation. To enable collaborative localization, four key challenges must be addressed, including modeling complex relationships between observed objects, fusing observations from an arbitrary number of collaborating robots, quantifying localization uncertainty, and addressing latency of robot communications. In this paper, we introduce a novel approach that integrates uncertainty-aware spatiotemporal graph learning and model-based state estimation for a team of robots to collaboratively localize objects. Specifically, we introduce a new uncertainty-aware graph learning model that learns spatiotemporal graphs to represent historical motions of the objects observed by each robot over time and provides uncertainties in object localization. Moreover, we propose a novel method for integrated learning and model-based state estimation, which fuses asynchronous observations obtained from an arbitrary number of robots for collaborative localization. We evaluate our approach in two collaborative object localization scenarios in simulations and on real robots. Experimental results show that our approach outperforms previous methods and achieves state-of-the-art performance on asynchronous collaborative localization.
Game Theoretic Decentralized and Communication-Free Multi-Robot Navigation
Dec 17, 2020
Effective multi-robot teams require the ability to move to goals in complex environments in order to address real-world applications such as search and rescue. Multi-robot teams should be able to operate in a completely decentralized manner, with individual robot team members being capable of acting without explicit communication between neighbors. In this paper, we propose a novel game theoretic model that enables decentralized and communication-free navigation to a goal position. Robots estimate the behavior of their local teammates in order to identify behaviors that move them in the direction of the goal, while also avoiding obstacles and maintaining team cohesion without collisions. We prove theoretically that generated actions approach a Nash equilibrium, which also corresponds to an optimal strategy identified for each robot. We show through simulations that our approach enables decentralized and communication-free navigation by a multi-robot system to a goal position, avoiding obstacles and collisions, while also maintaining connectivity.
Adaptation to Team Composition Changes for Heterogeneous Multi-Robot Sensor Coverage
Dec 17, 2020

We consider the problem of multi-robot sensor coverage, which deals with deploying a multi-robot team in an environment and optimizing the sensing quality of the overall environment. As real-world environments involve a variety of sensory information, and individual robots are limited in their available number of sensors, successful multi-robot sensor coverage requires the deployment of robots in such a way that each individual team member's sensing quality is maximized. Additionally, because individual robots have varying complements of sensors and both robots and sensors can fail, robots must be able to adapt and adjust how they value each sensing capability in order to obtain the most complete view of the environment, even through changes in team composition. We introduce a novel formulation for sensor coverage by multi-robot teams with heterogeneous sensing capabilities that maximizes each robot's sensing quality, balancing the varying sensing capabilities of individual robots based on the overall team composition. We propose a solution based on regularized optimization that uses sparsity-inducing terms to ensure a robot team focuses on all possible event types, and which we show is proven to converge to the optimal solution. Through extensive simulation, we show that our approach is able to effectively deploy a multi-robot team to maximize the sensing quality of an environment, responding to failures in the multi-robot team more robustly than non-adaptive approaches.
Team Assignment for Heterogeneous Multi-Robot Sensor Coverage through Graph Representation Learning
Dec 17, 2020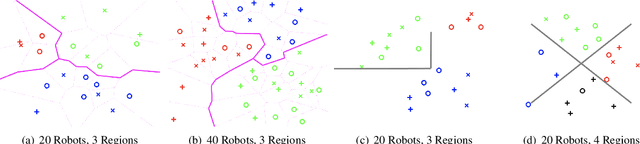
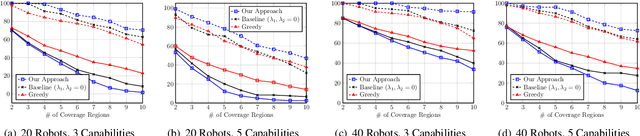


Sensor coverage is the critical multi-robot problem of maximizing the detection of events in an environment through the deployment of multiple robots. Large multi-robot systems are often composed of simple robots that are typically not equipped with a complete set of sensors, so teams with comprehensive sensing abilities are required to properly cover an area. Robots also exhibit multiple forms of relationships (e.g., communication connections or spatial distribution) that need to be considered when assigning robot teams for sensor coverage. To address this problem, in this paper we introduce a novel formulation of sensor coverage by multi-robot systems with heterogeneous relationships as a graph representation learning problem. We propose a principled approach based on the mathematical framework of regularized optimization to learn a unified representation of the multi-robot system from the graphs describing the heterogeneous relationships and to identify the learned representation's underlying structure in order to assign the robots to teams. To evaluate the proposed approach, we conduct extensive experiments on simulated multi-robot systems and a physical multi-robot system as a case study, demonstrating that our approach is able to effectively assign teams for heterogeneous multi-robot sensor coverage.
Simultaneous View and Feature Selection for Collaborative Multi-Robot Recognition
Dec 17, 2020
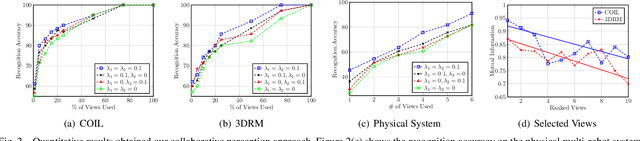


Collaborative multi-robot perception provides multiple views of an environment, offering varying perspectives to collaboratively understand the environment even when individual robots have poor points of view or when occlusions are caused by obstacles. These multiple observations must be intelligently fused for accurate recognition, and relevant observations need to be selected in order to allow unnecessary robots to continue on to observe other targets. This research problem has not been well studied in the literature yet. In this paper, we propose a novel approach to collaborative multi-robot perception that simultaneously integrates view selection, feature selection, and object recognition into a unified regularized optimization formulation, which uses sparsity-inducing norms to identify the robots with the most representative views and the modalities with the most discriminative features. As our optimization formulation is hard to solve due to the introduced non-smooth norms, we implement a new iterative optimization algorithm, which is guaranteed to converge to the optimal solution. We evaluate our approach on multi-view benchmark datasets, a case-study in simulation, and on a physical multi-robot system. Experimental results demonstrate that our approach enables accurate object recognition and effective view selection as defined by mutual information.
Representing Multi-Robot Structure through Multimodal Graph Embedding for the Selection of Robot Teams
Apr 07, 2020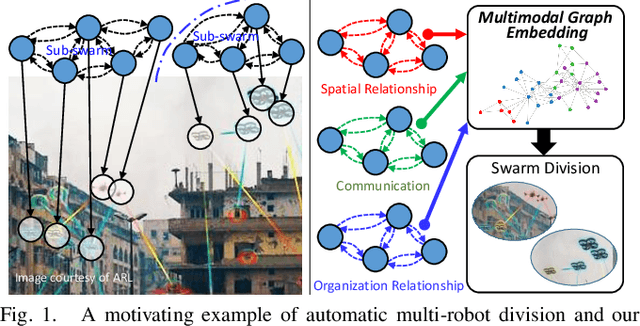

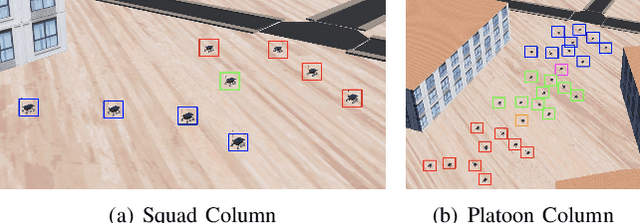
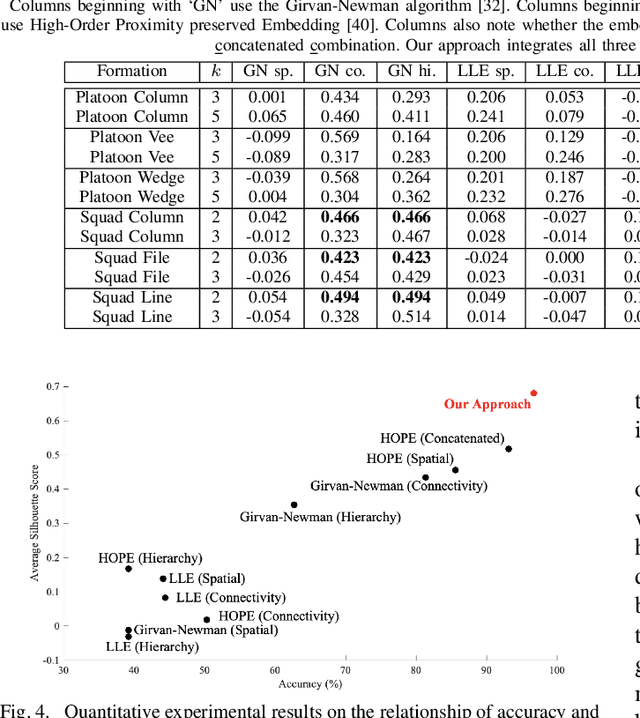
Multi-robot systems of increasing size and complexity are used to solve large-scale problems, such as area exploration and search and rescue. A key decision in human-robot teaming is dividing a multi-robot system into teams to address separate issues or to accomplish a task over a large area. In order to address the problem of selecting teams in a multi-robot system, we propose a new multimodal graph embedding method to construct a unified representation that fuses multiple information modalities to describe and divide a multi-robot system. The relationship modalities are encoded as directed graphs that can encode asymmetrical relationships, which are embedded into a unified representation for each robot. Then, the constructed multimodal representation is used to determine teams based upon unsupervised learning. We perform experiments to evaluate our approach on expert-defined team formations, large-scale simulated multi-robot systems, and a system of physical robots. Experimental results show that our method successfully decides correct teams based on the multifaceted internal structures describing multi-robot systems, and outperforms baseline methods based upon only one mode of information, as well as other graph embedding-based division methods.
Simultaneous Learning from Human Pose and Object Cues for Real-Time Activity Recognition
Mar 26, 2020
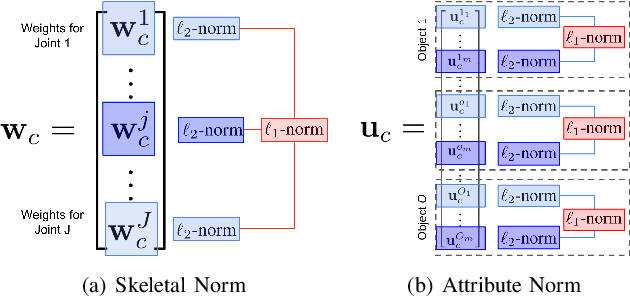


Real-time human activity recognition plays an essential role in real-world human-centered robotics applications, such as assisted living and human-robot collaboration. Although previous methods based on skeletal data to encode human poses showed promising results on real-time activity recognition, they lacked the capability to consider the context provided by objects within the scene and in use by the humans, which can provide a further discriminant between human activity categories. In this paper, we propose a novel approach to real-time human activity recognition, through simultaneously learning from observations of both human poses and objects involved in the human activity. We formulate human activity recognition as a joint optimization problem under a unified mathematical framework, which uses a regression-like loss function to integrate human pose and object cues and defines structured sparsity-inducing norms to identify discriminative body joints and object attributes. To evaluate our method, we perform extensive experiments on two benchmark datasets and a physical robot in a home assistance setting. Experimental results have shown that our method outperforms previous methods and obtains real-time performance for human activity recognition with a processing speed of 10^4 Hz.
Space-Time Representation of People Based on 3D Skeletal Data: A Review
Feb 04, 2017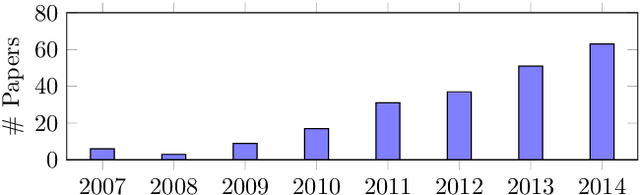
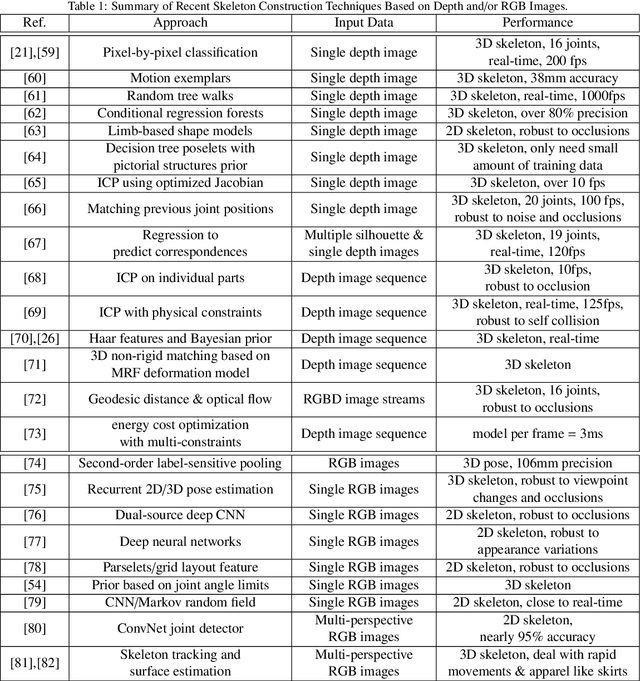
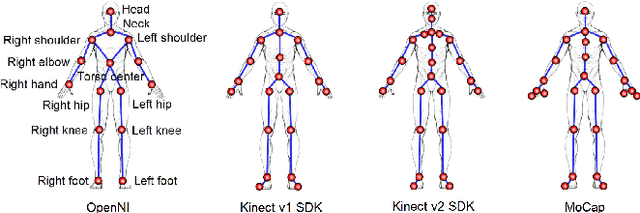
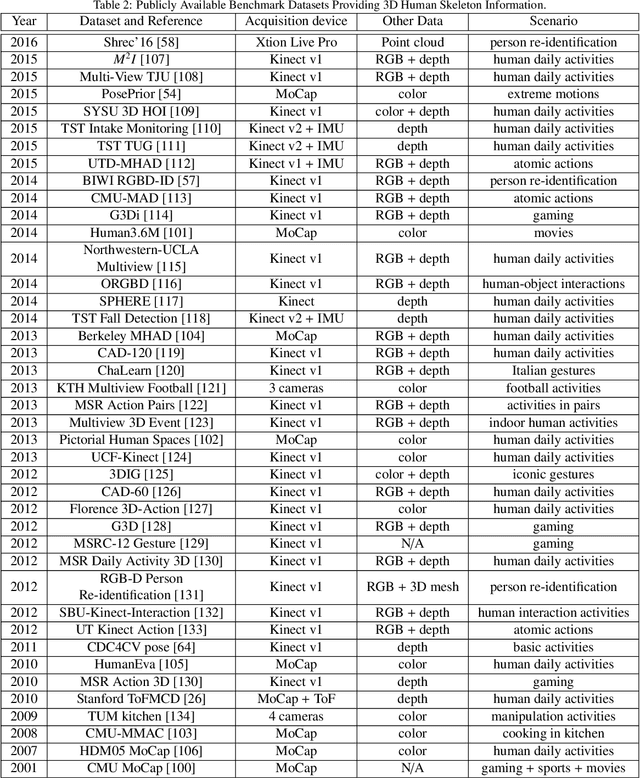
Spatiotemporal human representation based on 3D visual perception data is a rapidly growing research area. Based on the information sources, these representations can be broadly categorized into two groups based on RGB-D information or 3D skeleton data. Recently, skeleton-based human representations have been intensively studied and kept attracting an increasing attention, due to their robustness to variations of viewpoint, human body scale and motion speed as well as the realtime, online performance. This paper presents a comprehensive survey of existing space-time representations of people based on 3D skeletal data, and provides an informative categorization and analysis of these methods from the perspectives, including information modality, representation encoding, structure and transition, and feature engineering. We also provide a brief overview of skeleton acquisition devices and construction methods, enlist a number of public benchmark datasets with skeleton data, and discuss potential future research directions.