 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRange Resolution Enhanced Method with Spectral Properties for Hyperspectral Lidar
Mar 03, 2023Waveform decomposition is needed as a first step in the extraction of various types of geometric and spectral information from hyperspectral full-waveform LiDAR echoes. We present a new approach to deal with the "Pseudo-monopulse" waveform formed by the overlapped waveforms from multi-targets when they are very close. We use one single skew-normal distribution (SND) model to fit waveforms of all spectral channels first and count the geometric center position distribution of the echoes to decide whether it contains multi-targets. The geometric center position distribution of the "Pseudo-monopulse" presents aggregation and asymmetry with the change of wavelength, while such an asymmetric phenomenon cannot be found from the echoes of the single target. Both theoretical and experimental data verify the point. Based on such observation, we further propose a hyperspectral waveform decomposition method utilizing the SND mixture model with: 1) initializing new waveform component parameters and their ranges based on the distinction of the three characteristics (geometric center position, pulse width, and skew-coefficient) between the echo and fitted SND waveform and 2) conducting single-channel waveform decomposition for all channels and 3) setting thresholds to find outlier channels based on statistical parameters of all single-channel decomposition results (the standard deviation and the means of geometric center position) and 4) re-conducting single-channel waveform decomposition for these outlier channels. The proposed method significantly improves the range resolution from 60cm to 5cm at most for a 4ns width laser pulse and represents the state-of-the-art in "Pseudo-monopulse" waveform decomposition.
Field-wise Embedding Size Search via Structural Hard Auxiliary Mask Pruning for Click-Through Rate Prediction
Aug 17, 2022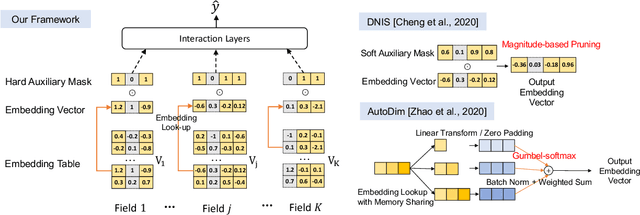


Feature embeddings are one of the most essential steps when training deep learning based Click-Through Rate prediction models, which map high-dimensional sparse features to dense embedding vectors. Classic human-crafted embedding size selection methods are shown to be "sub-optimal" in terms of the trade-off between memory usage and model capacity. The trending methods in Neural Architecture Search (NAS) have demonstrated their efficiency to search for embedding sizes. However, most existing NAS-based works suffer from expensive computational costs, the curse of dimensionality of the search space, and the discrepancy between continuous search space and discrete candidate space. Other works that prune embeddings in an unstructured manner fail to reduce the computational costs explicitly. In this paper, to address those limitations, we propose a novel strategy that searches for the optimal mixed-dimension embedding scheme by structurally pruning a super-net via Hard Auxiliary Mask. Our method aims to directly search candidate models in the discrete space using a simple and efficient gradient-based method. Furthermore, we introduce orthogonal regularity on embedding tables to reduce correlations within embedding columns and enhance representation capacity. Extensive experiments demonstrate it can effectively remove redundant embedding dimensions without great performance loss.