 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Reasoning Tokens via RL and Parallel Thinking: Evidence From Competitive Programming
Apr 01, 2026We study how to scale reasoning token budgets for competitive programming through two complementary approaches: training-time reinforcement learning (RL) and test-time parallel thinking. During RL training, we observe an approximately log-linear relationship between validation accuracy and the average number of generated reasoning tokens over successive checkpoints, and show two ways to shift this training trajectory: verification RL warmup raises the starting point, while randomized clipping produces a steeper trend in the observed regime. As scaling single-generation reasoning during RL quickly becomes expensive under full attention, we introduce a multi-round parallel thinking pipeline that distributes the token budget across threads and rounds of generation, verification, and refinement. We train the model end-to-end on this pipeline to match the training objective to the test-time structure. Starting from Seed-OSS-36B, the full system with 16 threads and 16 rounds per thread matches the underlying RL model's oracle pass@16 at pass@1 using 7.6 million tokens per problem on average, and surpasses GPT-5-high on 456 hard competitive programming problems from AetherCode.
BFS-Prover: Scalable Best-First Tree Search for LLM-based Automatic Theorem Proving
Feb 05, 2025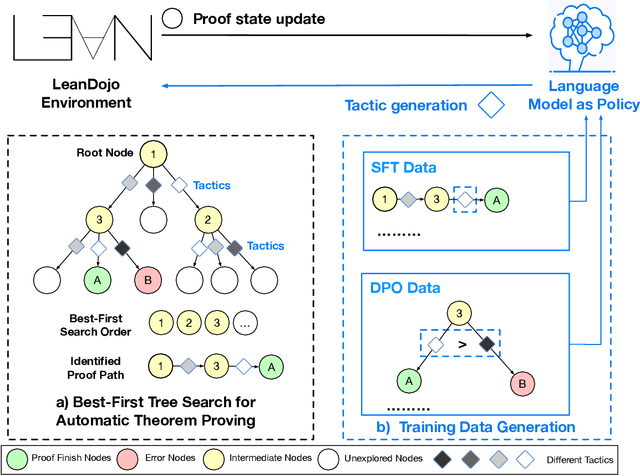
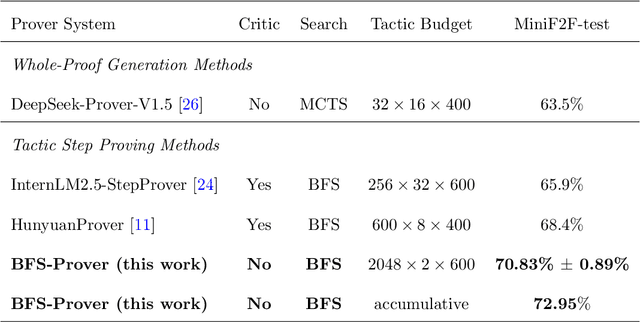
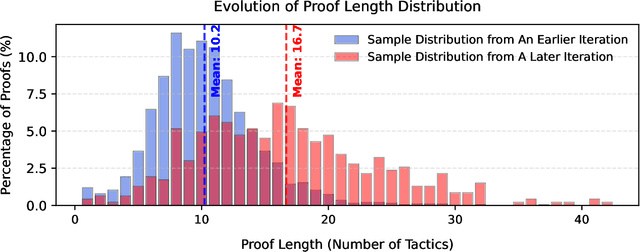
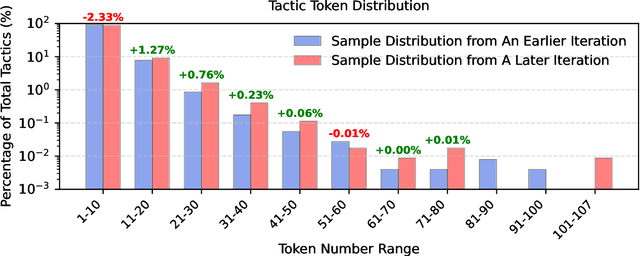
Recent advancements in large language models (LLMs) have spurred growing interest in automatic theorem proving using Lean4, where effective tree search methods are crucial for navigating proof search spaces. While the existing approaches primarily rely on value functions and Monte Carlo Tree Search (MCTS), the potential of simpler methods like Best-First Search (BFS) remains underexplored. This paper investigates whether BFS can achieve competitive performance in large-scale theorem proving tasks. We present \texttt{BFS-Prover}, a scalable expert iteration framework, featuring three key innovations. First, we implement strategic data filtering at each expert iteration round, excluding problems solvable via beam search node expansion to focus on harder cases. Second, we improve the sample efficiency of BFS through Direct Preference Optimization (DPO) applied to state-tactic pairs automatically annotated with compiler error feedback, refining the LLM's policy to prioritize productive expansions. Third, we employ length normalization in BFS to encourage exploration of deeper proof paths. \texttt{BFS-Prover} achieves a score of $71.31$ on the MiniF2F test set and therefore challenges the perceived necessity of complex tree search methods, demonstrating that BFS can achieve competitive performance when properly scaled.
Field-wise Embedding Size Search via Structural Hard Auxiliary Mask Pruning for Click-Through Rate Prediction
Aug 17, 2022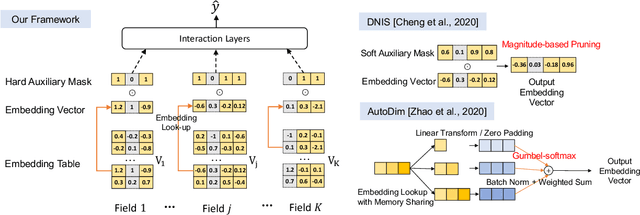


Feature embeddings are one of the most essential steps when training deep learning based Click-Through Rate prediction models, which map high-dimensional sparse features to dense embedding vectors. Classic human-crafted embedding size selection methods are shown to be "sub-optimal" in terms of the trade-off between memory usage and model capacity. The trending methods in Neural Architecture Search (NAS) have demonstrated their efficiency to search for embedding sizes. However, most existing NAS-based works suffer from expensive computational costs, the curse of dimensionality of the search space, and the discrepancy between continuous search space and discrete candidate space. Other works that prune embeddings in an unstructured manner fail to reduce the computational costs explicitly. In this paper, to address those limitations, we propose a novel strategy that searches for the optimal mixed-dimension embedding scheme by structurally pruning a super-net via Hard Auxiliary Mask. Our method aims to directly search candidate models in the discrete space using a simple and efficient gradient-based method. Furthermore, we introduce orthogonal regularity on embedding tables to reduce correlations within embedding columns and enhance representation capacity. Extensive experiments demonstrate it can effectively remove redundant embedding dimensions without great performance loss.
Enhanced Exploration in Neural Feature Selection for Deep Click-Through Rate Prediction Models via Ensemble of Gating Layers
Dec 07, 2021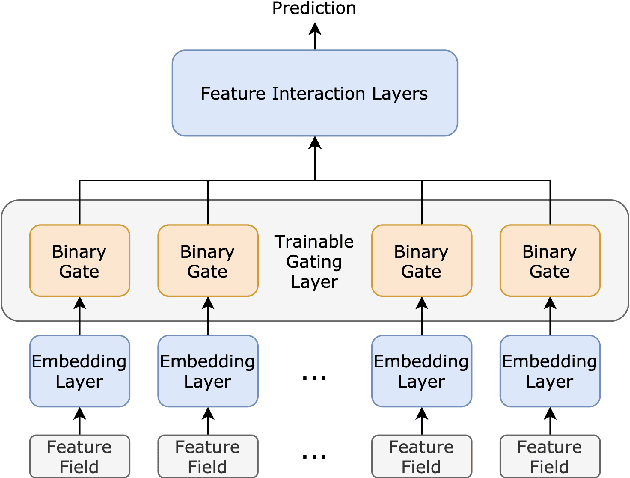
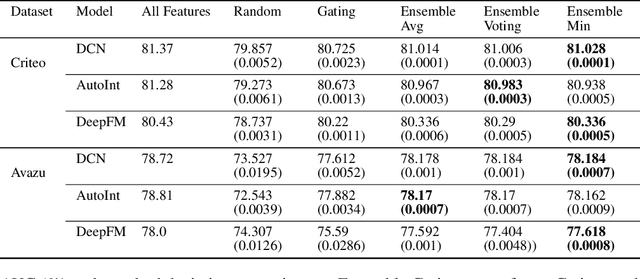
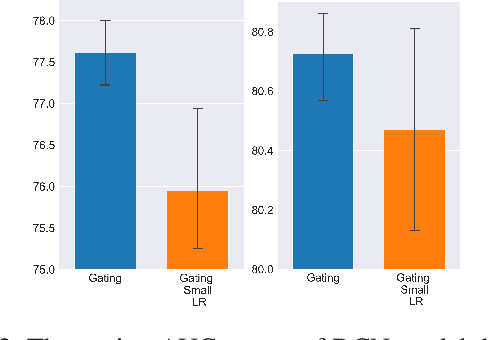

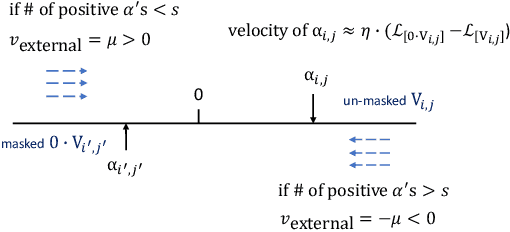
Feature selection has been an essential step in developing industry-scale deep Click-Through Rate (CTR) prediction systems. The goal of neural feature selection (NFS) is to choose a relatively small subset of features with the best explanatory power as a means to remove redundant features and reduce computational cost. Inspired by gradient-based neural architecture search (NAS) and network pruning methods, people have tackled the NFS problem with Gating approach that inserts a set of differentiable binary gates to drop less informative features. The binary gates are optimized along with the network parameters in an efficient end-to-end manner. In this paper, we analyze the gradient-based solution from an exploration-exploitation perspective and use empirical results to show that Gating approach might suffer from insufficient exploration. To improve the exploration capacity of gradient-based solutions, we propose a simple but effective ensemble learning approach, named Ensemble Gating. We choose two public datasets, namely Avazu and Criteo, to evaluate this approach. Our experiments show that, without adding any computational overhead or introducing any hyper-parameter (except the size of the ensemble), our method is able to consistently improve Gating approach and find a better subset of features on the two datasets with three different underlying deep CTR prediction models.