 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable-DiffCoder: Pushing the Frontier of Code Diffusion Large Language Model
Jan 23, 2026Diffusion-based language models (DLLMs) offer non-sequential, block-wise generation and richer data reuse compared to autoregressive (AR) models, but existing code DLLMs still lag behind strong AR baselines under comparable budgets. We revisit this setting in a controlled study and introduce Stable-DiffCoder, a block diffusion code model that reuses the Seed-Coder architecture, data, and training pipeline. To enable efficient knowledge learning and stable training, we incorporate a block diffusion continual pretraining (CPT) stage enhanced by a tailored warmup and block-wise clipped noise schedule. Under the same data and architecture, Stable-DiffCoder overall outperforms its AR counterpart on a broad suite of code benchmarks. Moreover, relying only on the CPT and supervised fine-tuning stages, Stable-DiffCoder achieves stronger performance than a wide range of \~8B ARs and DLLMs, demonstrating that diffusion-based training can improve code modeling quality beyond AR training alone. Moreover, diffusion-based any-order modeling improves structured code modeling for editing and reasoning, and through data augmentation, benefits low-resource coding languages.
FlashLabs Chroma 1.0: A Real-Time End-to-End Spoken Dialogue Model with Personalized Voice Cloning
Jan 16, 2026Recent end-to-end spoken dialogue systems leverage speech tokenizers and neural audio codecs to enable LLMs to operate directly on discrete speech representations. However, these models often exhibit limited speaker identity preservation, hindering personalized voice interaction. In this work, we present Chroma 1.0, the first open-source, real-time, end-to-end spoken dialogue model that achieves both low-latency interaction and high-fidelity personalized voice cloning. Chroma achieves sub-second end-to-end latency through an interleaved text-audio token schedule (1:2) that supports streaming generation, while maintaining high-quality personalized voice synthesis across multi-turn conversations. Our experimental results demonstrate that Chroma achieves a 10.96% relative improvement in speaker similarity over the human baseline, with a Real-Time Factor (RTF) of 0.43, while maintaining strong reasoning and dialogue capabilities. Our code and models are publicly available at https://github.com/FlashLabs-AI-Corp/FlashLabs-Chroma and https://huggingface.co/FlashLabs/Chroma-4B .
AInsteinBench: Benchmarking Coding Agents on Scientific Repositories
Dec 24, 2025We introduce AInsteinBench, a large-scale benchmark for evaluating whether large language model (LLM) agents can operate as scientific computing development agents within real research software ecosystems. Unlike existing scientific reasoning benchmarks which focus on conceptual knowledge, or software engineering benchmarks that emphasize generic feature implementation and issue resolving, AInsteinBench evaluates models in end-to-end scientific development settings grounded in production-grade scientific repositories. The benchmark consists of tasks derived from maintainer-authored pull requests across six widely used scientific codebases, spanning quantum chemistry, quantum computing, molecular dynamics, numerical relativity, fluid dynamics, and cheminformatics. All benchmark tasks are carefully curated through multi-stage filtering and expert review to ensure scientific challenge, adequate test coverage, and well-calibrated difficulty. By leveraging evaluation in executable environments, scientifically meaningful failure modes, and test-driven verification, AInsteinBench measures a model's ability to move beyond surface-level code generation toward the core competencies required for computational scientific research.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
OmniMoGen: Unifying Human Motion Generation via Learning from Interleaved Text-Motion Instructions
Dec 22, 2025Large language models (LLMs) have unified diverse linguistic tasks within a single framework, yet such unification remains unexplored in human motion generation. Existing methods are confined to isolated tasks, limiting flexibility for free-form and omni-objective generation. To address this, we propose OmniMoGen, a unified framework that enables versatile motion generation through interleaved text-motion instructions. Built upon a concise RVQ-VAE and transformer architecture, OmniMoGen supports end-to-end instruction-driven motion generation. We construct X2Mo, a large-scale dataset of over 137K interleaved text-motion instructions, and introduce AnyContext, a benchmark for evaluating interleaved motion generation. Experiments show that OmniMoGen achieves state-of-the-art performance on text-to-motion, motion editing, and AnyContext, exhibiting emerging capabilities such as compositional editing, self-reflective generation, and knowledge-informed generation. These results mark a step toward the next intelligent motion generation. Project Page: https://OmniMoGen.github.io/.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
CodeContests+: High-Quality Test Case Generation for Competitive Programming
Jun 06, 2025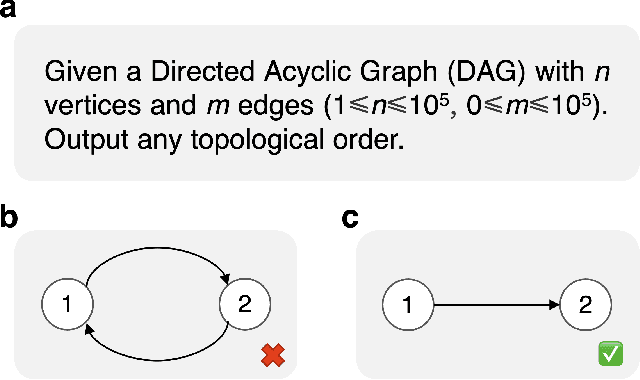
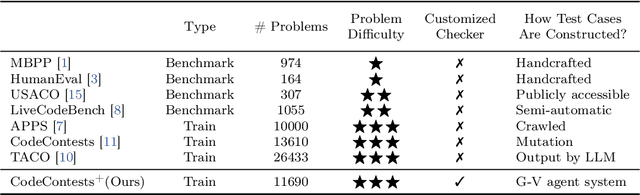
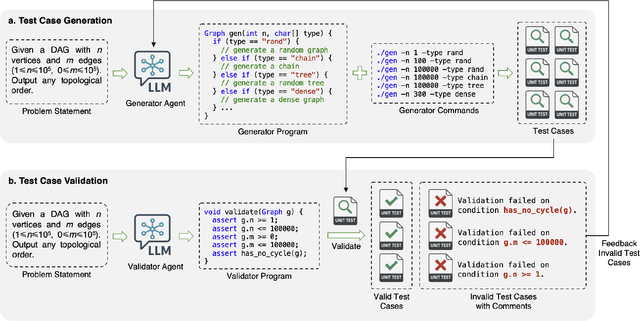
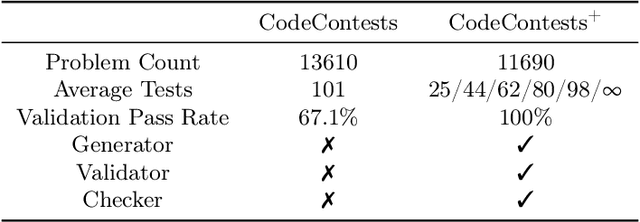
Competitive programming, due to its high reasoning difficulty and precise correctness feedback, has become a key task for both training and evaluating the reasoning capabilities of large language models (LLMs). However, while a large amount of public problem data, such as problem statements and solutions, is available, the test cases of these problems are often difficult to obtain. Therefore, test case generation is a necessary task for building large-scale datasets, and the quality of the test cases directly determines the accuracy of the evaluation. In this paper, we introduce an LLM-based agent system that creates high-quality test cases for competitive programming problems. We apply this system to the CodeContests dataset and propose a new version with improved test cases, named CodeContests+. We evaluated the quality of test cases in CodeContestsPlus. First, we used 1.72 million submissions with pass/fail labels to examine the accuracy of these test cases in evaluation. The results indicated that CodeContests+ achieves significantly higher accuracy than CodeContests, particularly with a notably higher True Positive Rate (TPR). Subsequently, our experiments in LLM Reinforcement Learning (RL) further confirmed that improvements in test case quality yield considerable advantages for RL.
FocusDiff: Advancing Fine-Grained Text-Image Alignment for Autoregressive Visual Generation through RL
Jun 05, 2025Recent studies extend the autoregression paradigm to text-to-image generation, achieving performance comparable to diffusion models. However, our new PairComp benchmark -- featuring test cases of paired prompts with similar syntax but different fine-grained semantics -- reveals that existing models struggle with fine-grained text-image alignment thus failing to realize precise control over visual tokens. To address this, we propose FocusDiff, which enhances fine-grained text-image semantic alignment by focusing on subtle differences between similar text-image pairs. We construct a new dataset of paired texts and images with similar overall expressions but distinct local semantics, further introducing a novel reinforcement learning algorithm to emphasize such fine-grained semantic differences for desired image generation. Our approach achieves state-of-the-art performance on existing text-to-image benchmarks and significantly outperforms prior methods on PairComp.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Kimi-Audio Technical Report
Apr 25, 2025



We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.