 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk Questions with Double Hints: Visual Question Generation with Answer-awareness and Region-reference
Jul 06, 2024



The visual question generation (VQG) task aims to generate human-like questions from an image and potentially other side information (e.g. answer type). Previous works on VQG fall in two aspects: i) They suffer from one image to many questions mapping problem, which leads to the failure of generating referential and meaningful questions from an image. ii) They fail to model complex implicit relations among the visual objects in an image and also overlook potential interactions between the side information and image. To address these limitations, we first propose a novel learning paradigm to generate visual questions with answer-awareness and region-reference. Concretely, we aim to ask the right visual questions with Double Hints - textual answers and visual regions of interests, which could effectively mitigate the existing one-to-many mapping issue. Particularly, we develop a simple methodology to self-learn the visual hints without introducing any additional human annotations. Furthermore, to capture these sophisticated relationships, we propose a new double-hints guided Graph-to-Sequence learning framework, which first models them as a dynamic graph and learns the implicit topology end-to-end, and then utilizes a graph-to-sequence model to generate the questions with double hints. Experimental results demonstrate the priority of our proposed method.
Feeding What You Need by Understanding What You Learned
Mar 05, 2022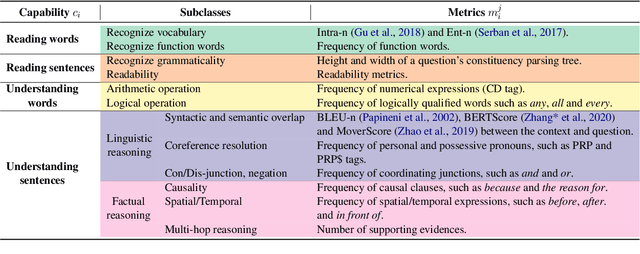



Machine Reading Comprehension (MRC) reveals the ability to understand a given text passage and answer questions based on it. Existing research works in MRC rely heavily on large-size models and corpus to improve the performance evaluated by metrics such as Exact Match ($EM$) and $F_1$. However, such a paradigm lacks sufficient interpretation to model capability and can not efficiently train a model with a large corpus. In this paper, we argue that a deep understanding of model capabilities and data properties can help us feed a model with appropriate training data based on its learning status. Specifically, we design an MRC capability assessment framework that assesses model capabilities in an explainable and multi-dimensional manner. Based on it, we further uncover and disentangle the connections between various data properties and model performance. Finally, to verify the effectiveness of the proposed MRC capability assessment framework, we incorporate it into a curriculum learning pipeline and devise a Capability Boundary Breakthrough Curriculum (CBBC) strategy, which performs a model capability-based training to maximize the data value and improve training efficiency. Extensive experiments demonstrate that our approach significantly improves performance, achieving up to an 11.22% / 8.71% improvement of $EM$ / $F_1$ on MRC tasks.
Multi-Choice Questions based Multi-Interest Policy Learning for Conversational Recommendation
Dec 22, 2021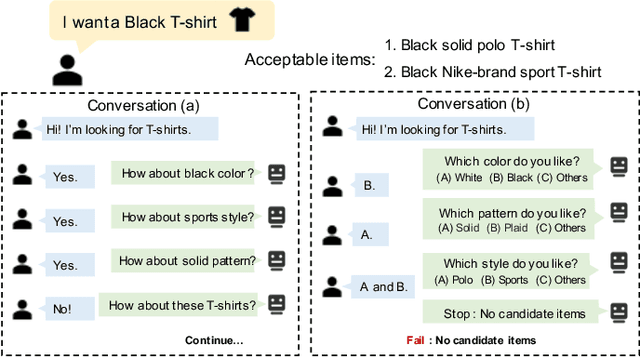
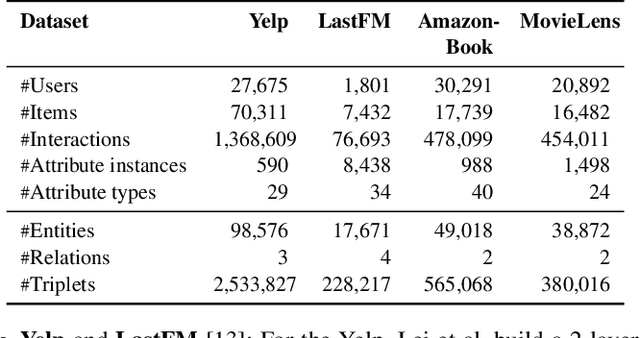


Conversational recommendation system (CRS) is able to obtain fine-grained and dynamic user preferences based on interactive dialogue. Previous CRS assumes that the user has a clear target item. However, for many users who resort to CRS, they might not have a clear idea about what they really like. Specifically, the user may have a clear single preference for some attribute types (e.g. color) of items, while for other attribute types, the user may have multiple preferences or even no clear preferences, which leads to multiple acceptable attribute instances (e.g. black and red) of one attribute type. Therefore, the users could show their preferences over items under multiple combinations of attribute instances rather than a single item with unique combination of all attribute instances. As a result, we first propose a more realistic CRS learning setting, namely Multi-Interest Multi-round Conversational Recommendation, where users may have multiple interests in attribute instance combinations and accept multiple items with partially overlapped combinations of attribute instances. To effectively cope with the new CRS learning setting, in this paper, we propose a novel learning framework namely, Multi-Choice questions based Multi-Interest Policy Learning . In order to obtain user preferences more efficiently, the agent generates multi-choice questions rather than binary yes/no ones on specific attribute instance. Besides, we propose a union set strategy to select candidate items instead of existing intersection set strategy in order to overcome over-filtering items during the conversation. Finally, we design a Multi-Interest Policy Learning module, which utilizes captured multiple interests of the user to decide next action, either asking attribute instances or recommending items. Extensive experimental results on four datasets verify the superiority of our method for the proposed setting.
RDF-to-Text Generation with Reinforcement Learning Based Graph-augmented Structural Neural Encoders
Nov 20, 2021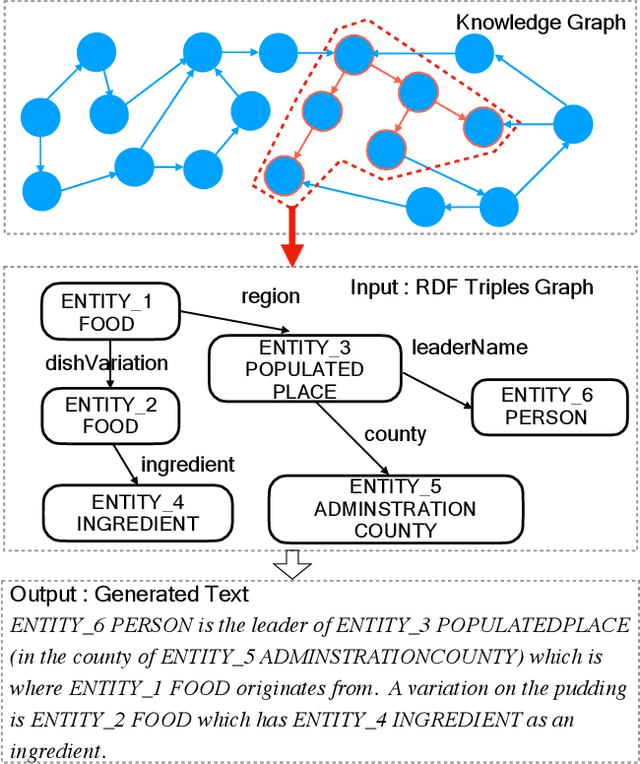

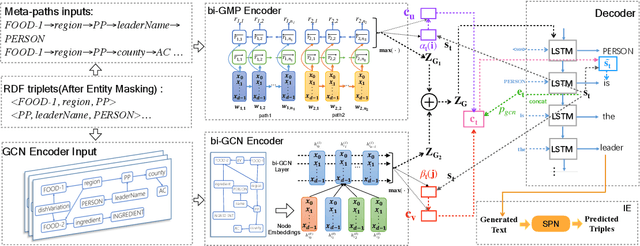
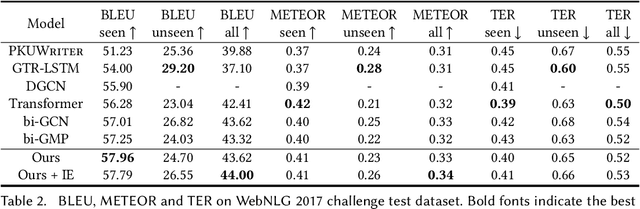
Considering a collection of RDF triples, the RDF-to-text generation task aims to generate a text description. Most previous methods solve this task using a sequence-to-sequence model or using a graph-based model to encode RDF triples and to generate a text sequence. Nevertheless, these approaches fail to clearly model the local and global structural information between and within RDF triples. Moreover, the previous methods also face the non-negligible problem of low faithfulness of the generated text, which seriously affects the overall performance of these models. To solve these problems, we propose a model combining two new graph-augmented structural neural encoders to jointly learn both local and global structural information in the input RDF triples. To further improve text faithfulness, we innovatively introduce a reinforcement learning (RL) reward based on information extraction (IE). We first extract triples from the generated text using a pretrained IE model and regard the correct number of the extracted triples as the additional RL reward. Experimental results on two benchmark datasets demonstrate that our proposed model outperforms the state-of-the-art baselines, and the additional reinforcement learning reward does help to improve the faithfulness of the generated text.
Graph-augmented Learning to Rank for Querying Large-scale Knowledge Graph
Nov 20, 2021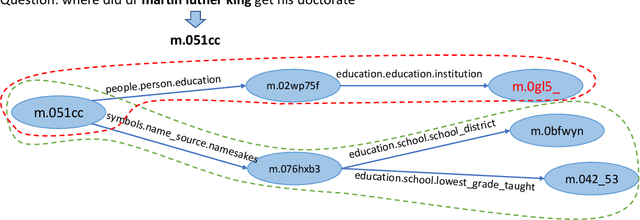

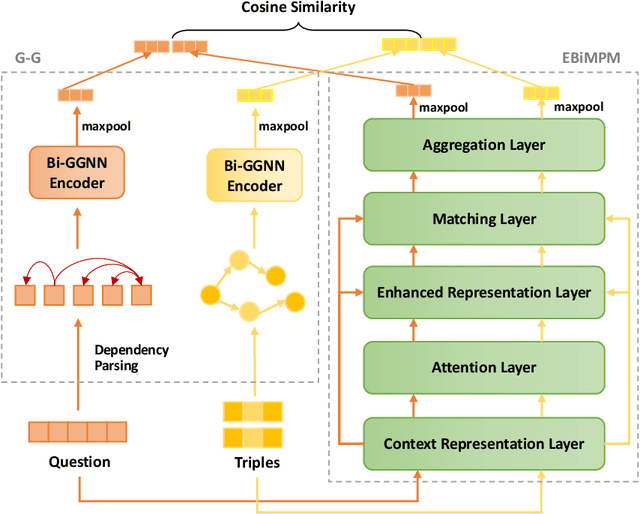

Knowledge graph question answering (i.e., KGQA) based on information retrieval aims to answer a question by retrieving answer from a large-scale knowledge graph. Most existing methods first roughly retrieve the knowledge subgraphs (KSG) that may contain candidate answer, and then search for the exact answer in the subgraph. However, the coarsely retrieved KSG may contain thousands of candidate nodes since the knowledge graph involved in querying is often of large scale. To tackle this problem, we first propose to partition the retrieved KSG to several smaller sub-KSGs via a new subgraph partition algorithm and then present a graph-augmented learning to rank model to select the top-ranked sub-KSGs from them. Our proposed model combines a novel subgraph matching networks to capture global interactions in both question and subgraphs and an Enhanced Bilateral Multi-Perspective Matching model to capture local interactions. Finally, we apply an answer selection model on the full KSG and the top-ranked sub-KSGs respectively to validate the effectiveness of our proposed graph-augmented learning to rank method. The experimental results on multiple benchmark datasets have demonstrated the effectiveness of our approach.
Multi-behavior Graph Contextual Aware Network for Session-based Recommendation
Sep 24, 2021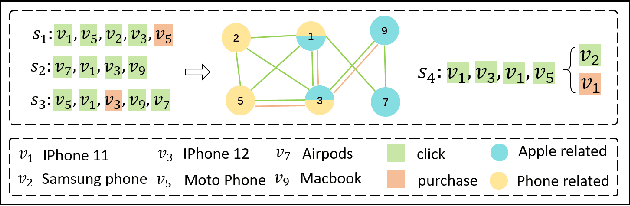
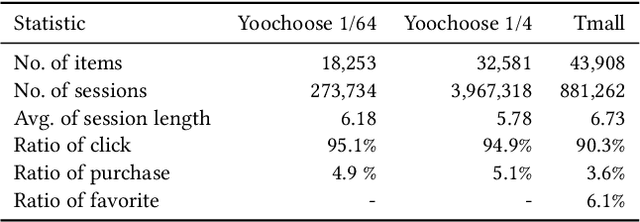

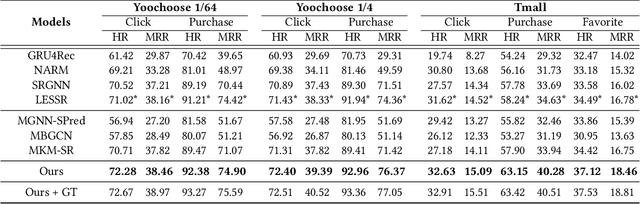
Predicting the next interaction of a short-term sequence is a challenging task in session-based recommendation (SBR).Multi-behavior session recommendation considers session sequence with multiple interaction types, such as click and purchase, to capture more effective user intention representation sufficiently.Despite the superior performance of existing multi-behavior based methods for SBR, there are still several severe limitations:(i) Almost all existing works concentrate on single target type of next behavior and fail to model multiplex behavior sessions uniformly.(ii) Previous methods also ignore the semantic relations between various next behavior and historical behavior sequence, which are significant signals to obtain current latent intention for SBR.(iii) The global cross-session item-item graph established by some existing models may incorporate semantics and context level noise for multi-behavior session-based recommendation. To overcome the limitations (i) and (ii), we propose two novel tasks for SBR, which require the incorporation of both historical behaviors and next behaviors into unified multi-behavior recommendation modeling. To this end, we design a Multi-behavior Graph Contextual Aware Network (MGCNet) for multi-behavior session-based recommendation for the two proposed tasks. Specifically, we build a multi-behavior global item transition graph based on all sessions involving all interaction types. Based on the global graph, MGCNet attaches the global interest representation to final item representation based on local contextual intention to address the limitation (iii). In the end, we utilize the next behavior information explicitly to guide the learning of general interest and current intention for SBR. Experiments on three public benchmark datasets show that MGCNet can outperform state-of-the-art models for multi-behavior session-based recommendation.
Graph Learning Augmented Heterogeneous Graph Neural Network for Social Recommendation
Sep 24, 2021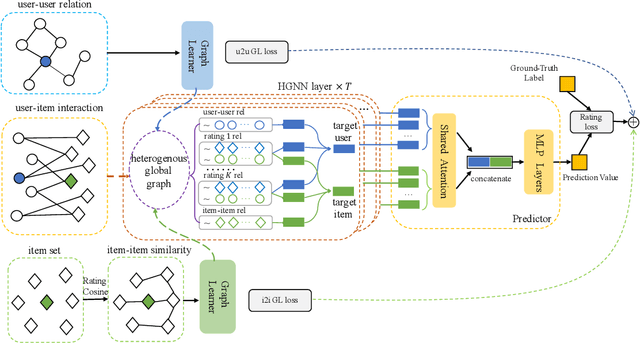
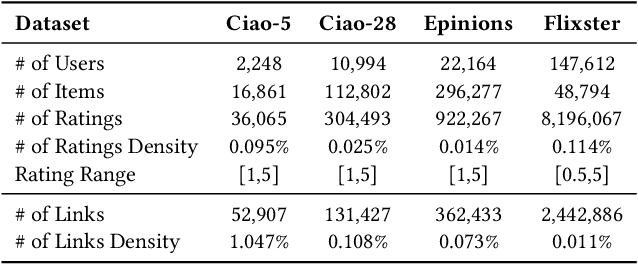
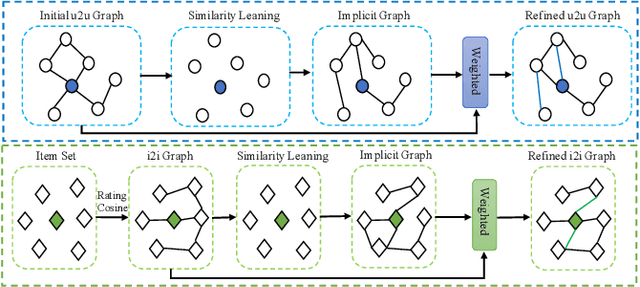
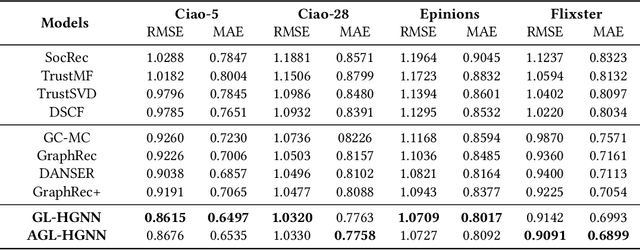
Social recommendation based on social network has achieved great success in improving the performance of recommendation system. Since social network (user-user relations) and user-item interactions are both naturally represented as graph-structured data, Graph Neural Networks (GNNs) have thus been widely applied for social recommendation. In this work, we propose an end-to-end heterogeneous global graph learning framework, namely Graph Learning Augmented Heterogeneous Graph Neural Network (GL-HGNN) for social recommendation. GL-HGNN aims to learn a heterogeneous global graph that makes full use of user-user relations, user-item interactions and item-item similarities in a unified perspective. To this end, we design a Graph Learner (GL) method to learn and optimize user-user and item-item connections separately. Moreover, we employ a Heterogeneous Graph Neural Network (HGNN) to capture the high-order complex semantic relations from our learned heterogeneous global graph. To scale up the computation of graph learning, we further present the Anchor-based Graph Learner (AGL) to reduce computational complexity. Extensive experiments on four real-world datasets demonstrate the effectiveness of our model.
Heterogeneous Global Graph Neural Networks for Personalized Session-based Recommendation
Jul 08, 2021
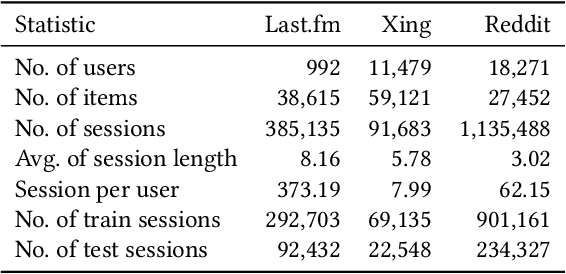
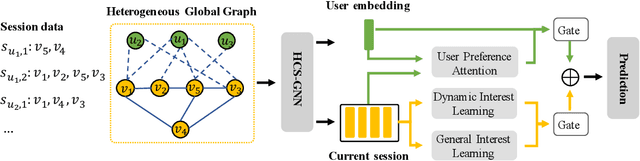
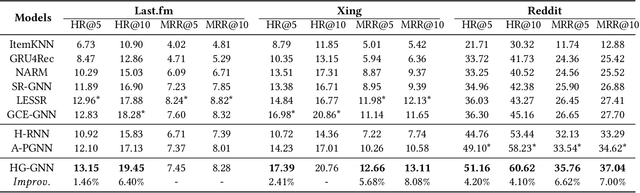
Predicting the next interaction of a short-term interaction session is a challenging task in session-based recommendation. Almost all existing works rely on item transition patterns, and neglect the impact of user historical sessions while modeling user preference, which often leads to non-personalized recommendation. Additionally, existing personalized session-based recommenders capture user preference only based on the sessions of the current user, but ignore the useful item-transition patterns from other user's historical sessions. To address these issues, we propose a novel Heterogeneous Global Graph Neural Networks (HG-GNN) to exploit the item transitions over all sessions in a subtle manner for better inferring user preference from the current and historical sessions. To effectively exploit the item transitions over all sessions from users, we propose a novel heterogeneous global graph that contains item transitions of sessions, user-item interactions and global co-occurrence items. Moreover, to capture user preference from sessions comprehensively, we propose to learn two levels of user representations from the global graph via two graph augmented preference encoders. Specifically, we design a novel heterogeneous graph neural network (HGNN) on the heterogeneous global graph to learn the long-term user preference and item representations with rich semantics. Based on the HGNN, we propose the Current Preference Encoder and the Historical Preference Encoder to capture the different levels of user preference from the current and historical sessions, respectively. To achieve personalized recommendation, we integrate the representations of the user current preference and historical interests to generate the final user preference representation. Extensive experimental results on three real-world datasets show that our model outperforms other state-of-the-art methods.
Constructing Contrastive samples via Summarization for Text Classification with limited annotations
Apr 11, 2021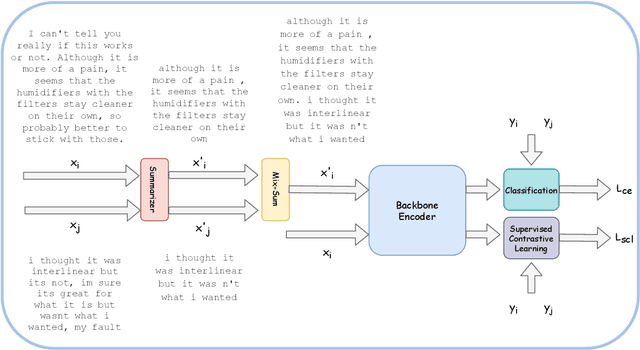
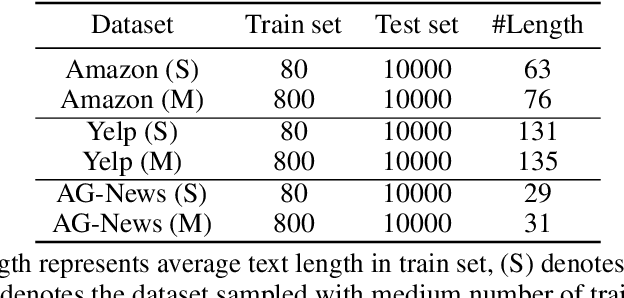
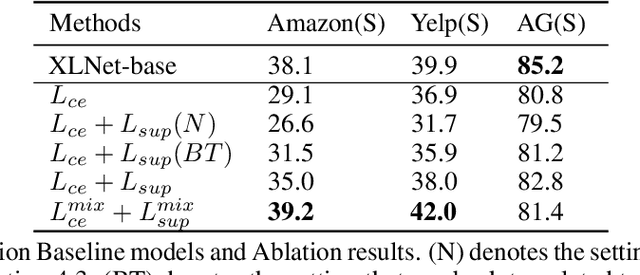
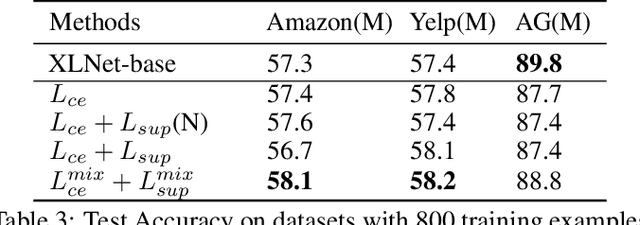
Contrastive Learning has emerged as a powerful representation learning method and facilitates various downstream tasks especially when supervised data is limited. How to construct efficient contrastive samples through data augmentation is key to its success. Unlike vision tasks, the data augmentation method for contrastive learning has not been investigated sufficiently in language tasks. In this paper, we propose a novel approach to constructing contrastive samples for language tasks using text summarization. We use these samples for supervised contrastive learning to gain better text representations which greatly benefit text classification tasks with limited annotations. To further improve the method, we mix up samples from different classes and add an extra regularization, named mix-sum regularization, in addition to the cross-entropy-loss. Experiments on real-world text classification datasets (Amazon-5, Yelp-5, AG News) demonstrate the effectiveness of the proposed contrastive learning framework with summarization-based data augmentation and mix-sum regularization.
Deep Graph Matching and Searching for Semantic Code Retrieval
Oct 24, 2020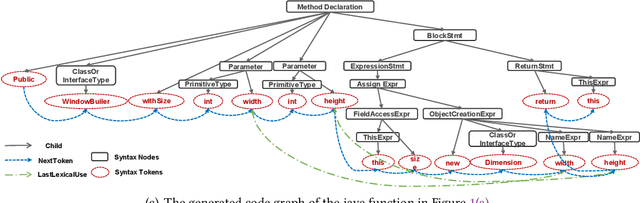

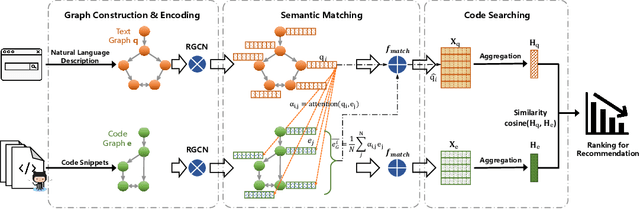

Code retrieval is to find the code snippet from a large corpus of source code repositories that highly matches the query of natural language description. Recent work mainly uses natural language processing techniques to process both query texts (i.e., human natural language) and code snippets (i.e., machine programming language), however neglecting the deep structured features of natural language query texts and source codes, both of which contain rich semantic information. In this paper, we propose an end-to-end deep graph matching and searching (DGMS) model based on graph neural networks for semantic code retrieval. To this end, we first represent both natural language query texts and programming language codes with the unified graph-structured data, and then use the proposed graph matching and searching model to retrieve the best matching code snippet. In particular, DGMS not only captures more structural information for individual query texts or code snippets but also learns the fine-grained similarity between them by a cross-attention based semantic matching operation. We evaluate the proposed DGMS model on two public code retrieval datasets from two representative programming languages (i.e., Java and Python). The experiment results demonstrate that DGMS significantly outperforms state-of-the-art baseline models by a large margin on both datasets. Moreover, our extensive ablation studies systematically investigate and illustrate the impact of each part of DGMS.