 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Attacks Revisited: A Large-Scale Empirical Study in Real Computer Vision Settings
Apr 07, 2022

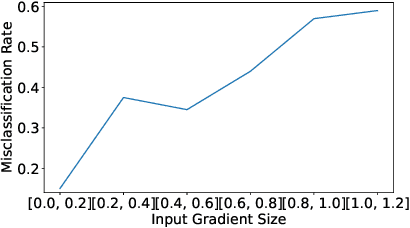
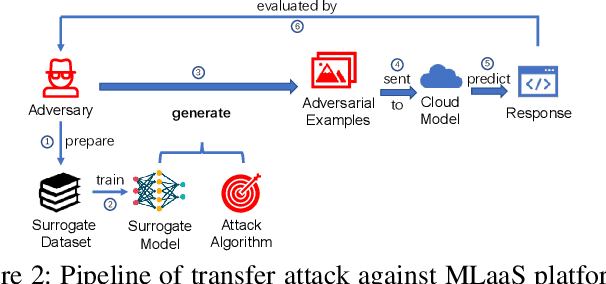
One intriguing property of adversarial attacks is their "transferability" -- an adversarial example crafted with respect to one deep neural network (DNN) model is often found effective against other DNNs as well. Intensive research has been conducted on this phenomenon under simplistic controlled conditions. Yet, thus far, there is still a lack of comprehensive understanding about transferability-based attacks ("transfer attacks") in real-world environments. To bridge this critical gap, we conduct the first large-scale systematic empirical study of transfer attacks against major cloud-based MLaaS platforms, taking the components of a real transfer attack into account. The study leads to a number of interesting findings which are inconsistent to the existing ones, including: (1) Simple surrogates do not necessarily improve real transfer attacks. (2) No dominant surrogate architecture is found in real transfer attacks. (3) It is the gap between posterior (output of the softmax layer) rather than the gap between logit (so-called $\kappa$ value) that increases transferability. Moreover, by comparing with prior works, we demonstrate that transfer attacks possess many previously unknown properties in real-world environments, such as (1) Model similarity is not a well-defined concept. (2) $L_2$ norm of perturbation can generate high transferability without usage of gradient and is a more powerful source than $L_\infty$ norm. We believe this work sheds light on the vulnerabilities of popular MLaaS platforms and points to a few promising research directions.
Deep Graph Matching and Searching for Semantic Code Retrieval
Oct 24, 2020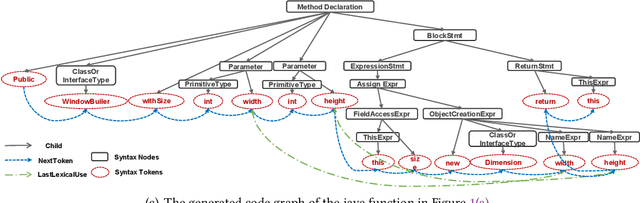

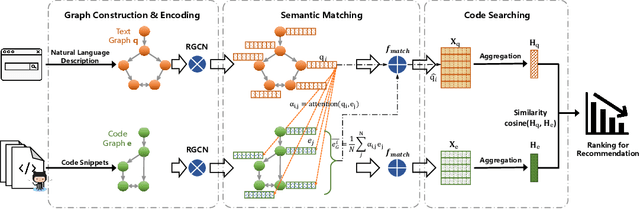

Code retrieval is to find the code snippet from a large corpus of source code repositories that highly matches the query of natural language description. Recent work mainly uses natural language processing techniques to process both query texts (i.e., human natural language) and code snippets (i.e., machine programming language), however neglecting the deep structured features of natural language query texts and source codes, both of which contain rich semantic information. In this paper, we propose an end-to-end deep graph matching and searching (DGMS) model based on graph neural networks for semantic code retrieval. To this end, we first represent both natural language query texts and programming language codes with the unified graph-structured data, and then use the proposed graph matching and searching model to retrieve the best matching code snippet. In particular, DGMS not only captures more structural information for individual query texts or code snippets but also learns the fine-grained similarity between them by a cross-attention based semantic matching operation. We evaluate the proposed DGMS model on two public code retrieval datasets from two representative programming languages (i.e., Java and Python). The experiment results demonstrate that DGMS significantly outperforms state-of-the-art baseline models by a large margin on both datasets. Moreover, our extensive ablation studies systematically investigate and illustrate the impact of each part of DGMS.
Hierarchical Graph Matching Networks for Deep Graph Similarity Learning
Jul 08, 2020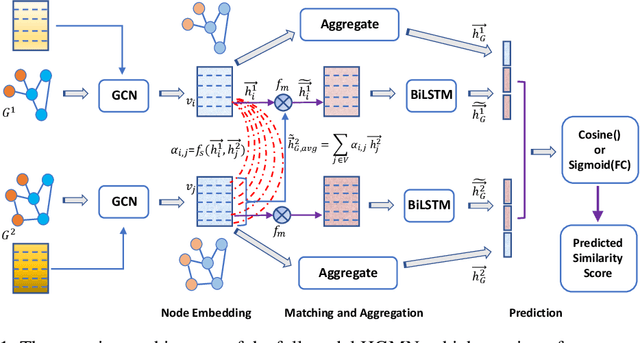
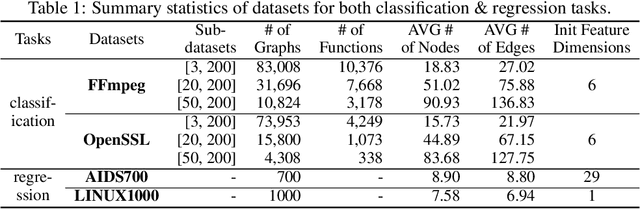
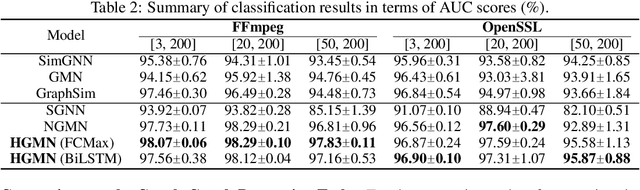
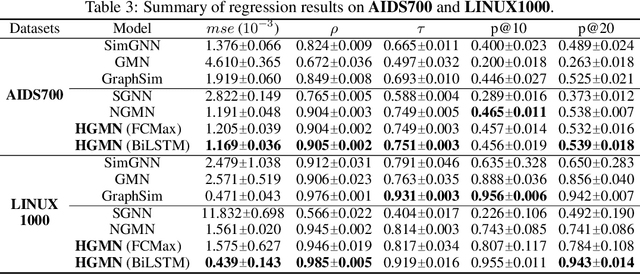
While the celebrated graph neural networks yield effective representations for individual nodes of a graph, there has been relatively less success in extending to deep graph similarity learning. Recent work has considered either global-level graph-graph interactions or low-level node-node interactions, ignoring the rich cross-level interactions (e.g., between nodes and a whole graph). In this paper, we propose a Hierarchical Graph Matching Network (HGMN) for computing the graph similarity between any pair of graph-structured objects. Our model jointly learns graph representations and a graph matching metric function for computing graph similarities in an end-to-end fashion. The proposed HGMN model consists of a node-graph matching network for effectively learning cross-level interactions between nodes of a graph and a whole graph, and a siamese graph neural network for learning global-level interactions between two graphs. Our comprehensive experiments demonstrate that HGMN consistently outperforms state-of-the-art graph matching network baselines for both classification and regression tasks.
Fine-grained Vibration Based Sensing Using a Smartphone
Jul 08, 2020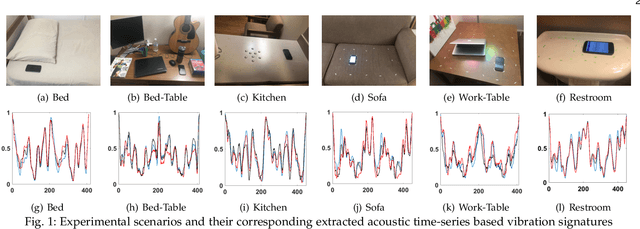
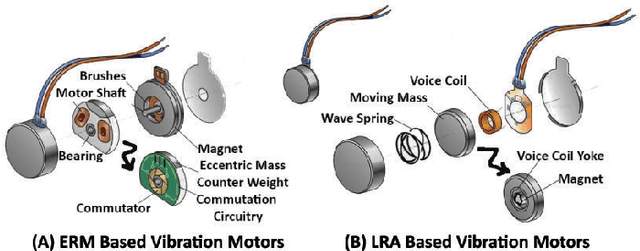
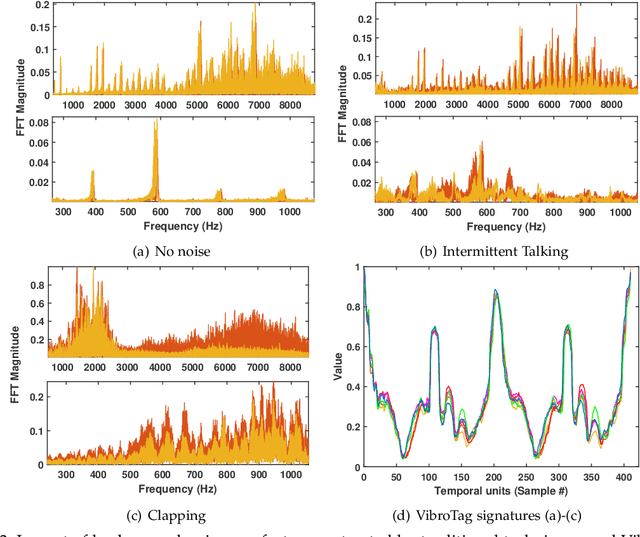
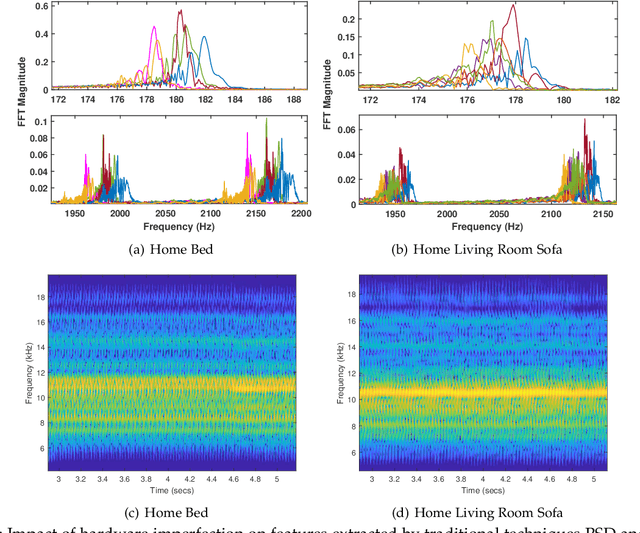
Recognizing surfaces based on their vibration signatures is useful as it can enable tagging of different locations without requiring any additional hardware such as Near Field Communication (NFC) tags. However, previous vibration based surface recognition schemes either use custom hardware for creating and sensing vibration, which makes them difficult to adopt, or use inertial (IMU) sensors in commercial off-the-shelf (COTS) smartphones to sense movements produced due to vibrations, which makes them coarse-grained because of the low sampling rates of IMU sensors. The mainstream COTS smartphones based schemes are also susceptible to inherent hardware based irregularities in vibration mechanism of the smartphones. Moreover, the existing schemes that use microphones to sense vibration are prone to short-term and constant background noises (e.g. intermittent talking, exhaust fan, etc.) because microphones not only capture the sounds created by vibration but also other interfering sounds present in the environment. In this paper, we propose VibroTag, a robust and practical vibration based sensing scheme that works with smartphones with different hardware, can extract fine-grained vibration signatures of different surfaces, and is robust to environmental noise and hardware based irregularities. We implemented VibroTag on two different Android phones and evaluated in multiple different environments where we collected data from 4 individuals for 5 to 20 consecutive days. Our results show that VibroTag achieves an average accuracy of 86.55% while recognizing 24 different locations/surfaces, even when some of those surfaces were made of similar material. VibroTag's accuracy is 37% higher than the average accuracy of 49.25% achieved by one of the state-of-the-art IMUs based schemes, which we implemented for comparison with VibroTag.
Monitoring Browsing Behavior of Customers in Retail Stores via RFID Imaging
Jul 07, 2020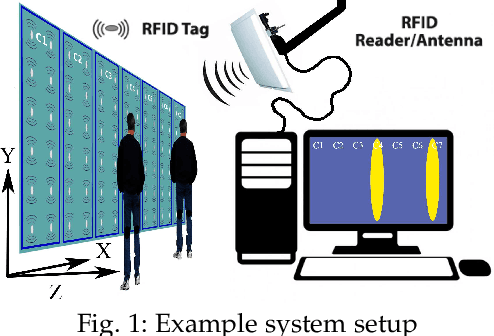
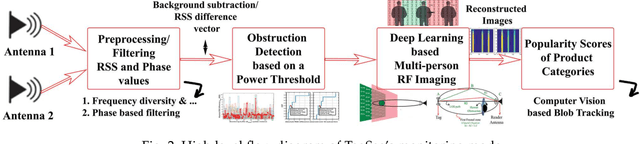
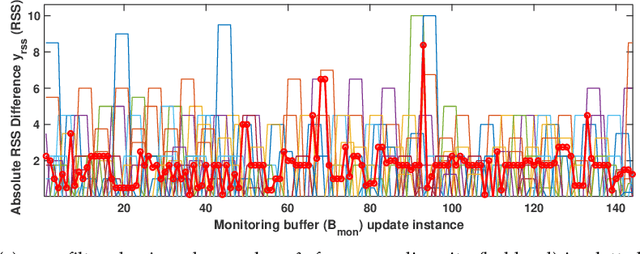
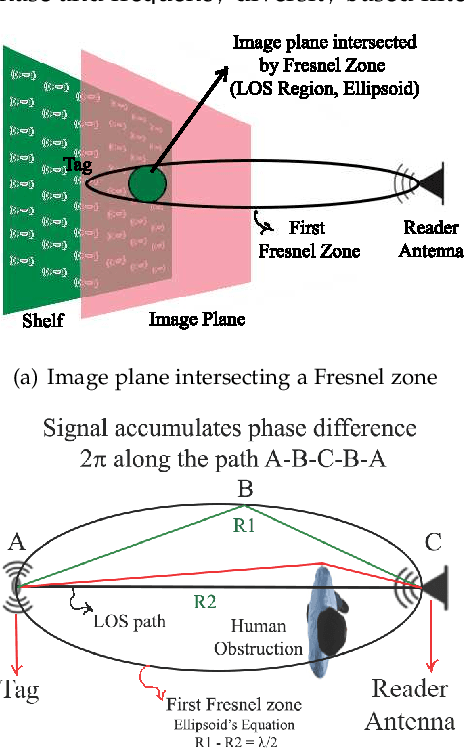
In this paper, we propose to use commercial off-the-shelf (COTS) monostatic RFID devices (i.e. which use a single antenna at a time for both transmitting and receiving RFID signals to and from the tags) to monitor browsing activity of customers in front of display items in places such as retail stores. To this end, we propose TagSee, a multi-person imaging system based on monostatic RFID imaging. TagSee is based on the insight that when customers are browsing the items on a shelf, they stand between the tags deployed along the boundaries of the shelf and the reader, which changes the multi-paths that the RFID signals travel along, and both the RSS and phase values of the RFID signals that the reader receives change. Based on these variations observed by the reader, TagSee constructs a coarse grained image of the customers. Afterwards, TagSee identifies the items that are being browsed by the customers by analyzing the constructed images. The key novelty of this paper is on achieving browsing behavior monitoring of multiple customers in front of display items by constructing coarse grained images via robust, analytical model-driven deep learning based, RFID imaging. To achieve this, we first mathematically formulate the problem of imaging humans using monostatic RFID devices and derive an approximate analytical imaging model that correlates the variations caused by human obstructions in the RFID signals. Based on this model, we then develop a deep learning framework to robustly image customers with high accuracy. We implement TagSee scheme using a Impinj Speedway R420 reader and SMARTRAC DogBone RFID tags. TagSee can achieve a TPR of more than ~90% and a FPR of less than ~10% in multi-person scenarios using training data from just 3-4 users.
An Adaptive and Fast Convergent Approach to Differentially Private Deep Learning
Dec 19, 2019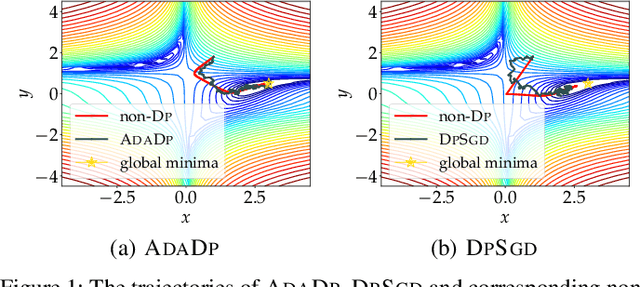
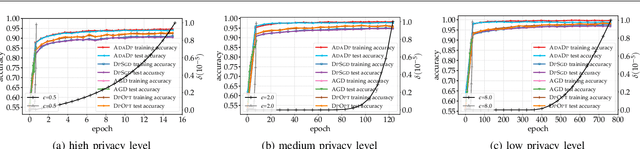
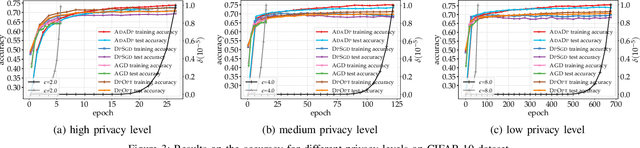
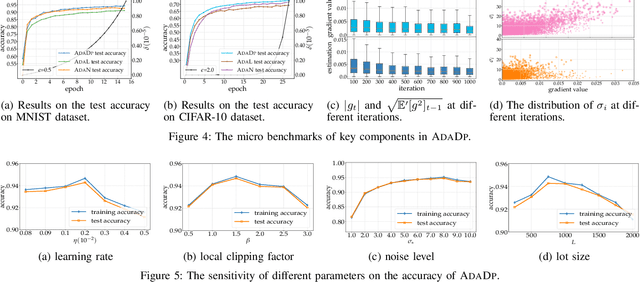
With the advent of the era of big data, deep learning has become a prevalent building block in a variety of machine learning or data mining tasks, such as signal processing, network modeling and traffic analysis, to name a few. The massive user data crowdsourced plays a crucial role in the success of deep learning models. However, it has been shown that user data may be inferred from trained neural models and thereby exposed to potential adversaries, which raises information security and privacy concerns. To address this issue, recent studies leverage the technique of differential privacy to design private-preserving deep learning algorithms. Albeit successful at privacy protection, differential privacy degrades the performance of neural models. In this paper, we develop ADADP, an adaptive and fast convergent learning algorithm with a provable privacy guarantee. ADADP significantly reduces the privacy cost by improving the convergence speed with an adaptive learning rate and mitigates the negative effect of differential privacy upon the model accuracy by introducing adaptive noise. The performance of ADADP is evaluated on real-world datasets. Experiment results show that it outperforms state-of-the-art differentially private approaches in terms of both privacy cost and model accuracy.