 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeeding What You Need by Understanding What You Learned
Paper and Code
Mar 05, 2022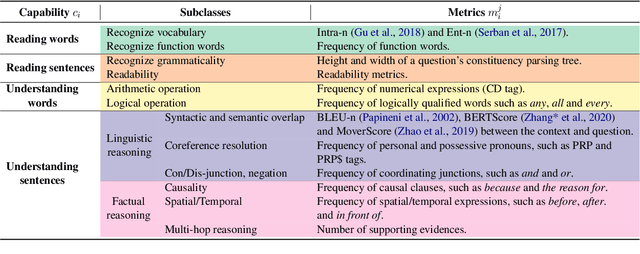



Machine Reading Comprehension (MRC) reveals the ability to understand a given text passage and answer questions based on it. Existing research works in MRC rely heavily on large-size models and corpus to improve the performance evaluated by metrics such as Exact Match ($EM$) and $F_1$. However, such a paradigm lacks sufficient interpretation to model capability and can not efficiently train a model with a large corpus. In this paper, we argue that a deep understanding of model capabilities and data properties can help us feed a model with appropriate training data based on its learning status. Specifically, we design an MRC capability assessment framework that assesses model capabilities in an explainable and multi-dimensional manner. Based on it, we further uncover and disentangle the connections between various data properties and model performance. Finally, to verify the effectiveness of the proposed MRC capability assessment framework, we incorporate it into a curriculum learning pipeline and devise a Capability Boundary Breakthrough Curriculum (CBBC) strategy, which performs a model capability-based training to maximize the data value and improve training efficiency. Extensive experiments demonstrate that our approach significantly improves performance, achieving up to an 11.22% / 8.71% improvement of $EM$ / $F_1$ on MRC tasks.