 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Kimi-Audio Technical Report
Apr 25, 2025



We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.
MoonCast: High-Quality Zero-Shot Podcast Generation
Mar 19, 2025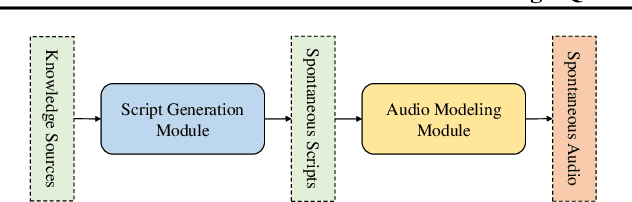


Recent advances in text-to-speech synthesis have achieved notable success in generating high-quality short utterances for individual speakers. However, these systems still face challenges when extending their capabilities to long, multi-speaker, and spontaneous dialogues, typical of real-world scenarios such as podcasts. These limitations arise from two primary challenges: 1) long speech: podcasts typically span several minutes, exceeding the upper limit of most existing work; 2) spontaneity: podcasts are marked by their spontaneous, oral nature, which sharply contrasts with formal, written contexts; existing works often fall short in capturing this spontaneity. In this paper, we propose MoonCast, a solution for high-quality zero-shot podcast generation, aiming to synthesize natural podcast-style speech from text-only sources (e.g., stories, technical reports, news in TXT, PDF, or Web URL formats) using the voices of unseen speakers. To generate long audio, we adopt a long-context language model-based audio modeling approach utilizing large-scale long-context speech data. To enhance spontaneity, we utilize a podcast generation module to generate scripts with spontaneous details, which have been empirically shown to be as crucial as the text-to-speech modeling itself. Experiments demonstrate that MoonCast outperforms baselines, with particularly notable improvements in spontaneity and coherence.
MDAN: Multi-level Dependent Attention Network for Visual Emotion Analysis
Mar 25, 2022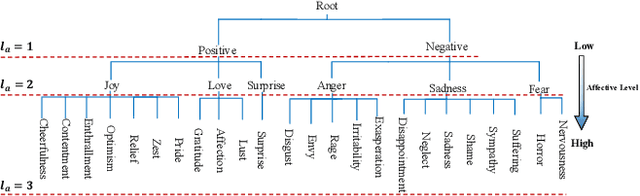
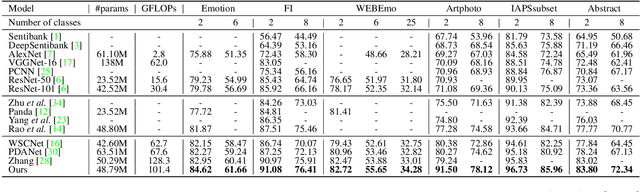
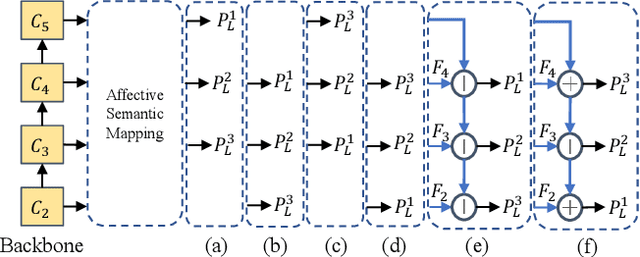

Visual Emotion Analysis (VEA) is attracting increasing attention. One of the biggest challenges of VEA is to bridge the affective gap between visual clues in a picture and the emotion expressed by the picture. As the granularity of emotions increases, the affective gap increases as well. Existing deep approaches try to bridge the gap by directly learning discrimination among emotions globally in one shot without considering the hierarchical relationship among emotions at different affective levels and the affective level of emotions to be classified. In this paper, we present the Multi-level Dependent Attention Network (MDAN) with two branches, to leverage the emotion hierarchy and the correlation between different affective levels and semantic levels. The bottom-up branch directly learns emotions at the highest affective level and strictly follows the emotion hierarchy while predicting emotions at lower affective levels. In contrast, the top-down branch attempt to disentangle the affective gap by one-to-one mapping between semantic levels and affective levels, namely, Affective Semantic Mapping. At each semantic level, a local classifier learns discrimination among emotions at the corresponding affective level. Finally, We integrate global learning and local learning into a unified deep framework and optimize the network simultaneously. Moreover, to properly extract and leverage channel dependencies and spatial attention while disentangling the affective gap, we carefully designed two attention modules: the Multi-head Cross Channel Attention module and the Level-dependent Class Activation Map module. Finally, the proposed deep framework obtains new state-of-the-art performance on six VEA benchmarks, where it outperforms existing state-of-the-art methods by a large margin, e.g., +3.85% on the WEBEmo dataset at 25 classes classification accuracy.
Towards thinner convolutional neural networks through Gradually Global Pruning
Mar 29, 2017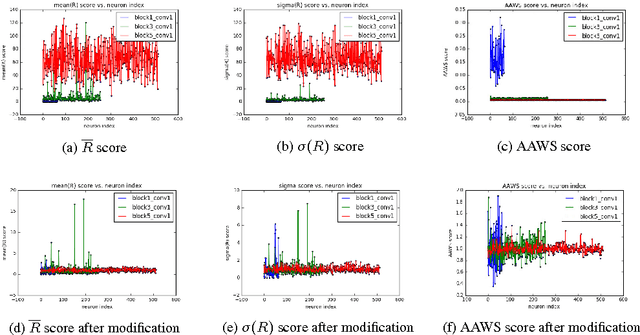
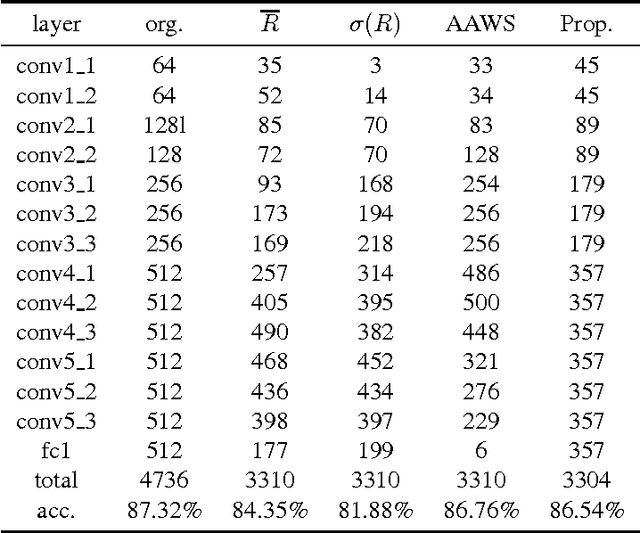
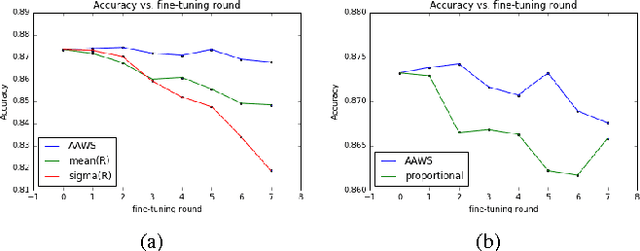
Deep network pruning is an effective method to reduce the storage and computation cost of deep neural networks when applying them to resource-limited devices. Among many pruning granularities, neuron level pruning will remove redundant neurons and filters in the model and result in thinner networks. In this paper, we propose a gradually global pruning scheme for neuron level pruning. In each pruning step, a small percent of neurons were selected and dropped across all layers in the model. We also propose a simple method to eliminate the biases in evaluating the importance of neurons to make the scheme feasible. Compared with layer-wise pruning scheme, our scheme avoid the difficulty in determining the redundancy in each layer and is more effective for deep networks. Our scheme would automatically find a thinner sub-network in original network under a given performance.
Attribute-controlled face photo synthesis from simple line drawing
Feb 09, 2017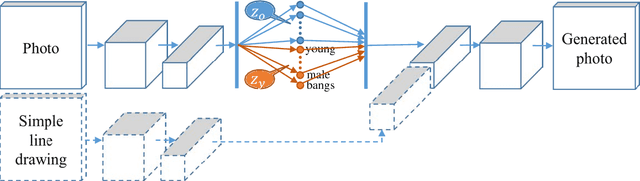



Face photo synthesis from simple line drawing is a one-to-many task as simple line drawing merely contains the contour of human face. Previous exemplar-based methods are over-dependent on the datasets and are hard to generalize to complicated natural scenes. Recently, several works utilize deep neural networks to increase the generalization, but they are still limited in the controllability of the users. In this paper, we propose a deep generative model to synthesize face photo from simple line drawing controlled by face attributes such as hair color and complexion. In order to maximize the controllability of face attributes, an attribute-disentangled variational auto-encoder (AD-VAE) is firstly introduced to learn latent representations disentangled with respect to specified attributes. Then we conduct photo synthesis from simple line drawing based on AD-VAE. Experiments show that our model can well disentangle the variations of attributes from other variations of face photos and synthesize detailed photorealistic face images with desired attributes. Regarding background and illumination as the style and human face as the content, we can also synthesize face photos with the target style of a style photo.
Every Filter Extracts A Specific Texture In Convolutional Neural Networks
Aug 18, 2016



Many works have concentrated on visualizing and understanding the inner mechanism of convolutional neural networks (CNNs) by generating images that activate some specific neurons, which is called deep visualization. However, it is still unclear what the filters extract from images intuitively. In this paper, we propose a modified code inversion algorithm, called feature map inversion, to understand the function of filter of interest in CNNs. We reveal that every filter extracts a specific texture. The texture from higher layer contains more colours and more intricate structures. We also demonstrate that style of images could be a combination of these texture primitives. Two methods are proposed to reallocate energy distribution of feature maps randomly and purposefully. Then, we inverse the modified code and generate images of diverse styles. With these results, we provide an explanation about why Gram matrix of feature maps \cite{Gatys_2016_CVPR} could represent image style.