 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFORESEE: Multimodal and Multi-view Representation Learning for Robust Prediction of Cancer Survival
May 13, 2024Integrating the different data modalities of cancer patients can significantly improve the predictive performance of patient survival. However, most existing methods ignore the simultaneous utilization of rich semantic features at different scales in pathology images. When collecting multimodal data and extracting features, there is a likelihood of encountering intra-modality missing data, introducing noise into the multimodal data. To address these challenges, this paper proposes a new end-to-end framework, FORESEE, for robustly predicting patient survival by mining multimodal information. Specifically, the cross-fusion transformer effectively utilizes features at the cellular level, tissue level, and tumor heterogeneity level to correlate prognosis through a cross-scale feature cross-fusion method. This enhances the ability of pathological image feature representation. Secondly, the hybrid attention encoder (HAE) uses the denoising contextual attention module to obtain the contextual relationship features and local detail features of the molecular data. HAE's channel attention module obtains global features of molecular data. Furthermore, to address the issue of missing information within modalities, we propose an asymmetrically masked triplet masked autoencoder to reconstruct lost information within modalities. Extensive experiments demonstrate the superiority of our method over state-of-the-art methods on four benchmark datasets in both complete and missing settings.
SELECTOR: Heterogeneous graph network with convolutional masked autoencoder for multimodal robust prediction of cancer survival
Mar 14, 2024Accurately predicting the survival rate of cancer patients is crucial for aiding clinicians in planning appropriate treatment, reducing cancer-related medical expenses, and significantly enhancing patients' quality of life. Multimodal prediction of cancer patient survival offers a more comprehensive and precise approach. However, existing methods still grapple with challenges related to missing multimodal data and information interaction within modalities. This paper introduces SELECTOR, a heterogeneous graph-aware network based on convolutional mask encoders for robust multimodal prediction of cancer patient survival. SELECTOR comprises feature edge reconstruction, convolutional mask encoder, feature cross-fusion, and multimodal survival prediction modules. Initially, we construct a multimodal heterogeneous graph and employ the meta-path method for feature edge reconstruction, ensuring comprehensive incorporation of feature information from graph edges and effective embedding of nodes. To mitigate the impact of missing features within the modality on prediction accuracy, we devised a convolutional masked autoencoder (CMAE) to process the heterogeneous graph post-feature reconstruction. Subsequently, the feature cross-fusion module facilitates communication between modalities, ensuring that output features encompass all features of the modality and relevant information from other modalities. Extensive experiments and analysis on six cancer datasets from TCGA demonstrate that our method significantly outperforms state-of-the-art methods in both modality-missing and intra-modality information-confirmed cases. Our codes are made available at https://github.com/panliangrui/Selector.
CVFC: Attention-Based Cross-View Feature Consistency for Weakly Supervised Semantic Segmentation of Pathology Images
Aug 21, 2023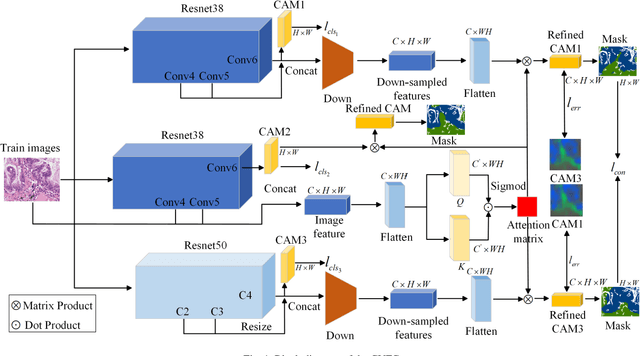
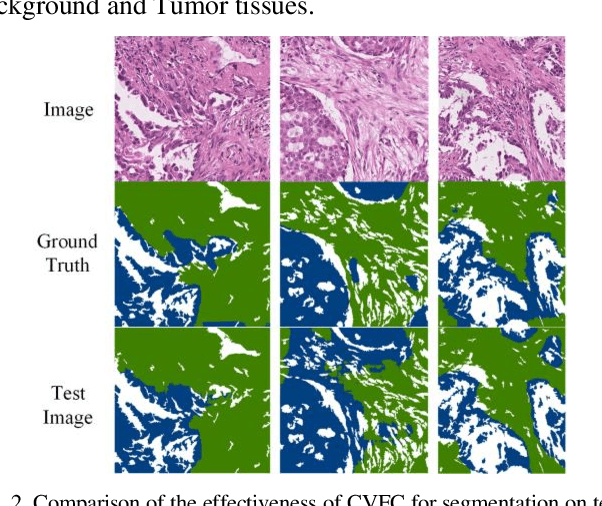
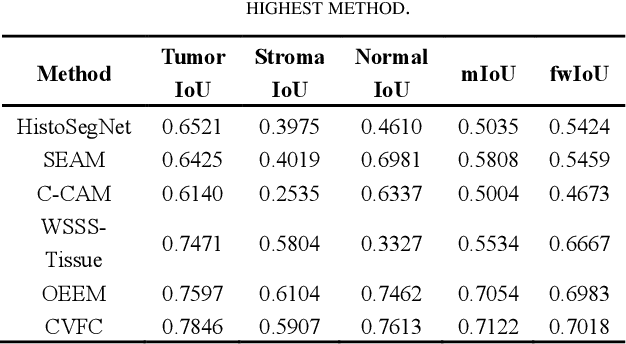

Histopathology image segmentation is the gold standard for diagnosing cancer, and can indicate cancer prognosis. However, histopathology image segmentation requires high-quality masks, so many studies now use imagelevel labels to achieve pixel-level segmentation to reduce the need for fine-grained annotation. To solve this problem, we propose an attention-based cross-view feature consistency end-to-end pseudo-mask generation framework named CVFC based on the attention mechanism. Specifically, CVFC is a three-branch joint framework composed of two Resnet38 and one Resnet50, and the independent branch multi-scale integrated feature map to generate a class activation map (CAM); in each branch, through down-sampling and The expansion method adjusts the size of the CAM; the middle branch projects the feature matrix to the query and key feature spaces, and generates a feature space perception matrix through the connection layer and inner product to adjust and refine the CAM of each branch; finally, through the feature consistency loss and feature cross loss to optimize the parameters of CVFC in co-training mode. After a large number of experiments, An IoU of 0.7122 and a fwIoU of 0.7018 are obtained on the WSSS4LUAD dataset, which outperforms HistoSegNet, SEAM, C-CAM, WSSS-Tissue, and OEEM, respectively.
LDCSF: Local depth convolution-based Swim framework for classifying multi-label histopathology images
Aug 21, 2023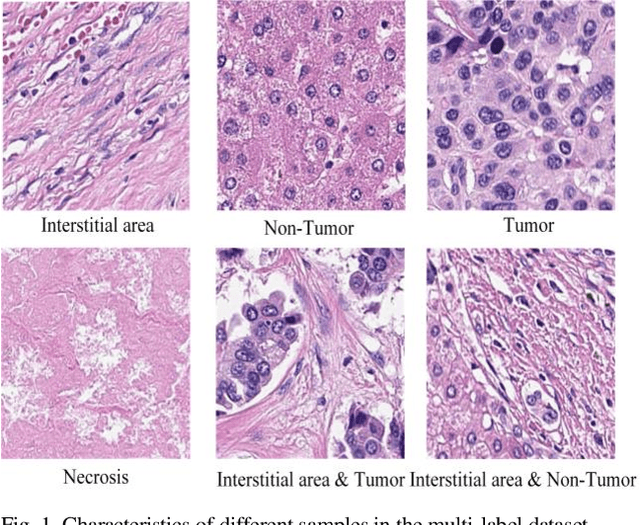
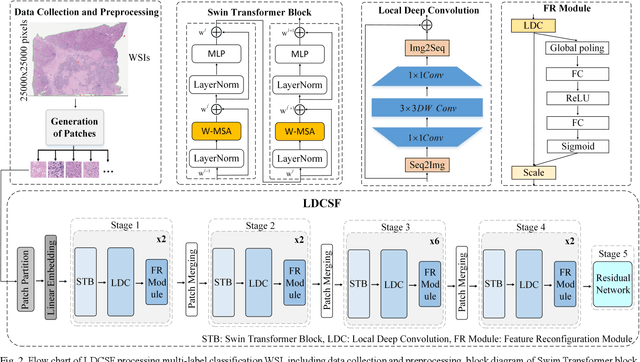
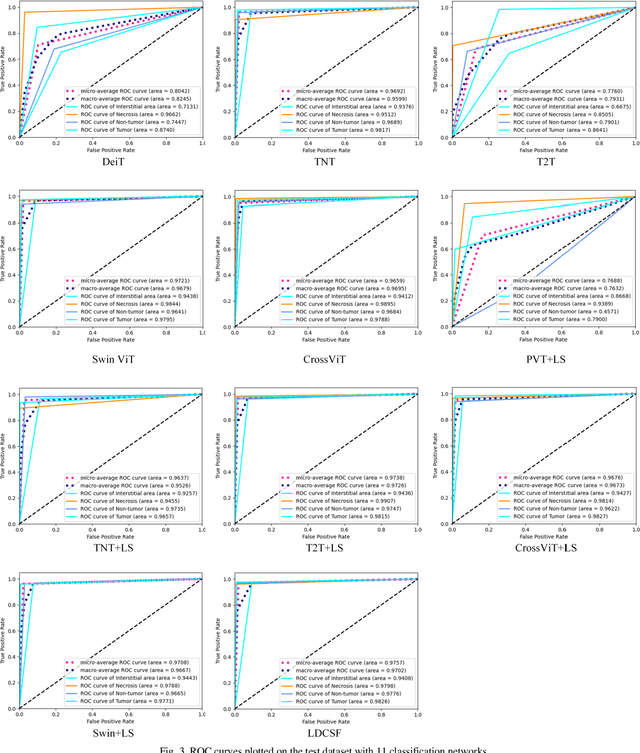
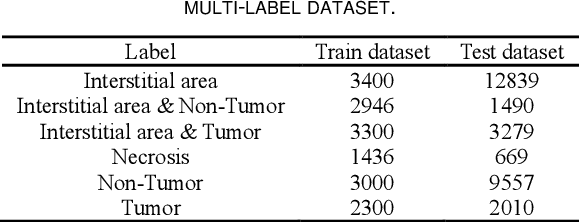
Histopathological images are the gold standard for diagnosing liver cancer. However, the accuracy of fully digital diagnosis in computational pathology needs to be improved. In this paper, in order to solve the problem of multi-label and low classification accuracy of histopathology images, we propose a locally deep convolutional Swim framework (LDCSF) to classify multi-label histopathology images. In order to be able to provide local field of view diagnostic results, we propose the LDCSF model, which consists of a Swin transformer module, a local depth convolution (LDC) module, a feature reconstruction (FR) module, and a ResNet module. The Swin transformer module reduces the amount of computation generated by the attention mechanism by limiting the attention to each window. The LDC then reconstructs the attention map and performs convolution operations in multiple channels, passing the resulting feature map to the next layer. The FR module uses the corresponding weight coefficient vectors obtained from the channels to dot product with the original feature map vector matrix to generate representative feature maps. Finally, the residual network undertakes the final classification task. As a result, the classification accuracy of LDCSF for interstitial area, necrosis, non-tumor and tumor reached 0.9460, 0.9960, 0.9808, 0.9847, respectively. Finally, we use the results of multi-label pathological image classification to calculate the tumor-to-stromal ratio, which lays the foundation for the analysis of the microenvironment of liver cancer histopathological images. Second, we released a multilabel histopathology image of liver cancer, our code and data are available at https://github.com/panliangrui/LSF.
Multi-Head Attention Mechanism Learning for Cancer New Subtypes and Treatment Based on Cancer Multi-Omics Data
Jul 09, 2023Due to the high heterogeneity and clinical characteristics of cancer, there are significant differences in multi-omics data and clinical features among subtypes of different cancers. Therefore, the identification and discovery of cancer subtypes are crucial for the diagnosis, treatment, and prognosis of cancer. In this study, we proposed a generalization framework based on attention mechanisms for unsupervised contrastive learning (AMUCL) to analyze cancer multi-omics data for the identification and characterization of cancer subtypes. AMUCL framework includes a unsupervised multi-head attention mechanism, which deeply extracts multi-omics data features. Importantly, a decoupled contrastive learning model (DMACL) based on a multi-head attention mechanism is proposed to learn multi-omics data features and clusters and identify new cancer subtypes. This unsupervised contrastive learning method clusters subtypes by calculating the similarity between samples in the feature space and sample space of multi-omics data. Compared to 11 other deep learning models, the DMACL model achieved a C-index of 0.002, a Silhouette score of 0.801, and a Davies Bouldin Score of 0.38 on a single-cell multi-omics dataset. On a cancer multi-omics dataset, the DMACL model obtained a C-index of 0.016, a Silhouette score of 0.688, and a Davies Bouldin Score of 0.46, and obtained the most reliable cancer subtype clustering results for each type of cancer. Finally, we used the DMACL model in the AMUCL framework to reveal six cancer subtypes of AML. By analyzing the GO functional enrichment, subtype-specific biological functions, and GSEA of AML, we further enhanced the interpretability of cancer subtype analysis based on the generalizable AMUCL framework.
MDAN: Multi-level Dependent Attention Network for Visual Emotion Analysis
Mar 25, 2022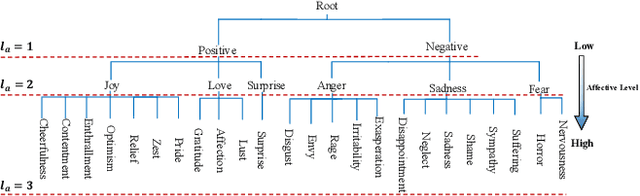
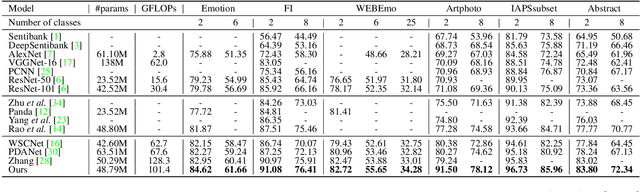
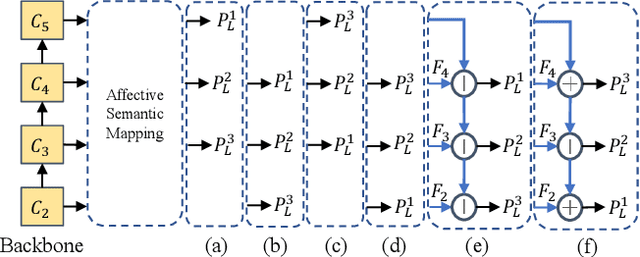

Visual Emotion Analysis (VEA) is attracting increasing attention. One of the biggest challenges of VEA is to bridge the affective gap between visual clues in a picture and the emotion expressed by the picture. As the granularity of emotions increases, the affective gap increases as well. Existing deep approaches try to bridge the gap by directly learning discrimination among emotions globally in one shot without considering the hierarchical relationship among emotions at different affective levels and the affective level of emotions to be classified. In this paper, we present the Multi-level Dependent Attention Network (MDAN) with two branches, to leverage the emotion hierarchy and the correlation between different affective levels and semantic levels. The bottom-up branch directly learns emotions at the highest affective level and strictly follows the emotion hierarchy while predicting emotions at lower affective levels. In contrast, the top-down branch attempt to disentangle the affective gap by one-to-one mapping between semantic levels and affective levels, namely, Affective Semantic Mapping. At each semantic level, a local classifier learns discrimination among emotions at the corresponding affective level. Finally, We integrate global learning and local learning into a unified deep framework and optimize the network simultaneously. Moreover, to properly extract and leverage channel dependencies and spatial attention while disentangling the affective gap, we carefully designed two attention modules: the Multi-head Cross Channel Attention module and the Level-dependent Class Activation Map module. Finally, the proposed deep framework obtains new state-of-the-art performance on six VEA benchmarks, where it outperforms existing state-of-the-art methods by a large margin, e.g., +3.85% on the WEBEmo dataset at 25 classes classification accuracy.