 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-interactive Siamese graph encoder-based image analysis to predict STAS from histopathology images in lung cancer
Nov 22, 2024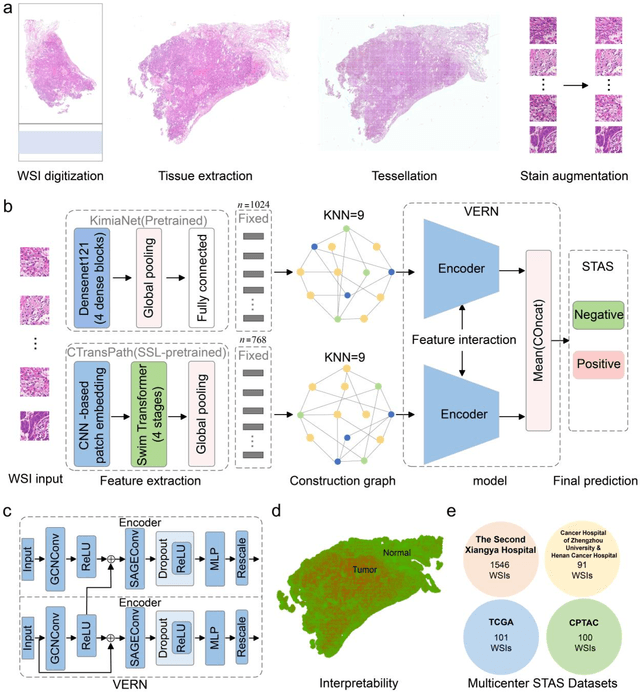
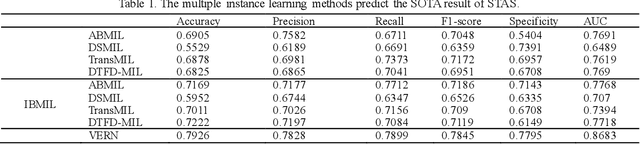
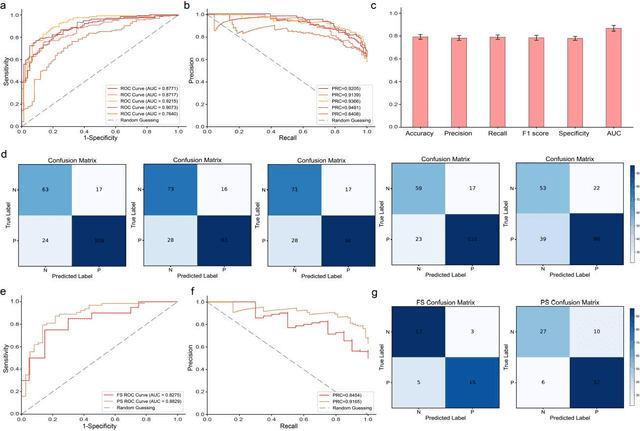
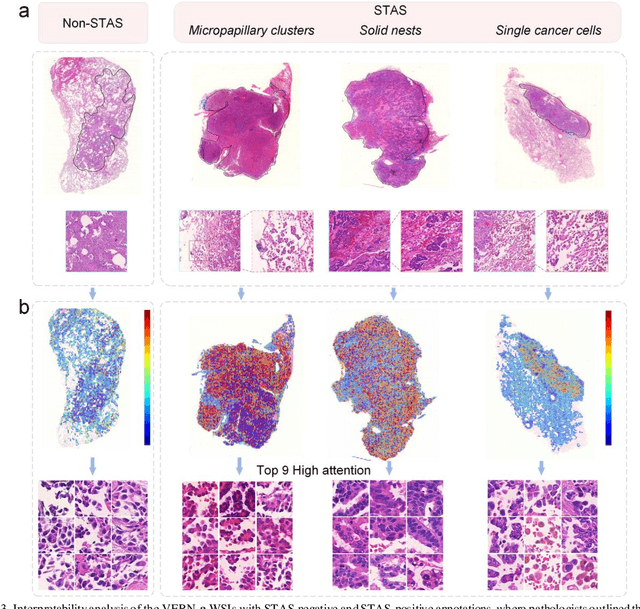
Spread through air spaces (STAS) is a distinct invasion pattern in lung cancer, crucial for prognosis assessment and guiding surgical decisions. Histopathology is the gold standard for STAS detection, yet traditional methods are subjective, time-consuming, and prone to misdiagnosis, limiting large-scale applications. We present VERN, an image analysis model utilizing a feature-interactive Siamese graph encoder to predict STAS from lung cancer histopathological images. VERN captures spatial topological features with feature sharing and skip connections to enhance model training. Using 1,546 histopathology slides, we built a large single-cohort STAS lung cancer dataset. VERN achieved an AUC of 0.9215 in internal validation and AUCs of 0.8275 and 0.8829 in frozen and paraffin-embedded test sections, respectively, demonstrating clinical-grade performance. Validated on a single-cohort and three external datasets, VERN showed robust predictive performance and generalizability, providing an open platform (http://plr.20210706.xyz:5000/) to enhance STAS diagnosis efficiency and accuracy.
FORESEE: Multimodal and Multi-view Representation Learning for Robust Prediction of Cancer Survival
May 13, 2024Integrating the different data modalities of cancer patients can significantly improve the predictive performance of patient survival. However, most existing methods ignore the simultaneous utilization of rich semantic features at different scales in pathology images. When collecting multimodal data and extracting features, there is a likelihood of encountering intra-modality missing data, introducing noise into the multimodal data. To address these challenges, this paper proposes a new end-to-end framework, FORESEE, for robustly predicting patient survival by mining multimodal information. Specifically, the cross-fusion transformer effectively utilizes features at the cellular level, tissue level, and tumor heterogeneity level to correlate prognosis through a cross-scale feature cross-fusion method. This enhances the ability of pathological image feature representation. Secondly, the hybrid attention encoder (HAE) uses the denoising contextual attention module to obtain the contextual relationship features and local detail features of the molecular data. HAE's channel attention module obtains global features of molecular data. Furthermore, to address the issue of missing information within modalities, we propose an asymmetrically masked triplet masked autoencoder to reconstruct lost information within modalities. Extensive experiments demonstrate the superiority of our method over state-of-the-art methods on four benchmark datasets in both complete and missing settings.