 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSilent Speech Interfaces in the Era of Large Language Models: A Comprehensive Taxonomy and Systematic Review
Mar 12, 2026Human-computer interaction has traditionally relied on the acoustic channel, a dependency that introduces systemic vulnerabilities to environmental noise, privacy constraints, and physiological speech impairments. Silent Speech Interfaces (SSIs) emerge as a transformative paradigm that bypasses the acoustic stage by decoding linguistic intent directly from the neuro-muscular-articulatory continuum. This review provides a high-level synthesis of the SSI landscape, transitioning from traditional transducer-centric analysis to a holistic intent-to-execution taxonomy. We systematically evaluate sensing modalities across four critical physiological interception points: neural oscillations, neuromuscular activation, articulatory kinematics (ultrasound/magnetometry), and pervasive active probing via acoustic or radio-frequency sensing. Critically, we analyze the current paradigm shift from heuristic signal processing to Latent Semantic Alignment. In this new era, Large Language Models (LLMs) and deep generative architectures serve as high-level linguistic priors to resolve the ``informational sparsity'' and non-stationarity of biosignals. By mapping fragmented physiological gestures into structured semantic latent spaces, modern SSI frameworks have, for the first time, approached the Word Error Rate usability threshold required for real-world deployment. We further examine the transition of SSIs from bulky laboratory instrumentation to ``invisible interfaces'' integrated into commodity-grade wearables, such as earables and smart glasses. Finally, we outline a strategic roadmap addressing the ``user-dependency paradox'' through self-supervised foundation models and define the ethical boundaries of ``neuro-security'' to protect cognitive liberty in an increasingly interfaced world.
SMILE: a Scale-aware Multiple Instance Learning Method for Multicenter STAS Lung Cancer Histopathology Diagnosis
Mar 18, 2025Spread through air spaces (STAS) represents a newly identified aggressive pattern in lung cancer, which is known to be associated with adverse prognostic factors and complex pathological features. Pathologists currently rely on time consuming manual assessments, which are highly subjective and prone to variation. This highlights the urgent need for automated and precise diag nostic solutions. 2,970 lung cancer tissue slides are comprised from multiple centers, re-diagnosed them, and constructed and publicly released three lung cancer STAS datasets: STAS CSU (hospital), STAS TCGA, and STAS CPTAC. All STAS datasets provide corresponding pathological feature diagnoses and related clinical data. To address the bias, sparse and heterogeneous nature of STAS, we propose an scale-aware multiple instance learning(SMILE) method for STAS diagnosis of lung cancer. By introducing a scale-adaptive attention mechanism, the SMILE can adaptively adjust high attention instances, reducing over-reliance on local regions and promoting consistent detection of STAS lesions. Extensive experiments show that SMILE achieved competitive diagnostic results on STAS CSU, diagnosing 251 and 319 STAS samples in CPTAC andTCGA,respectively, surpassing clinical average AUC. The 11 open baseline results are the first to be established for STAS research, laying the foundation for the future expansion, interpretability, and clinical integration of computational pathology technologies. The datasets and code are available at https://anonymous.4open.science/r/IJCAI25-1DA1.
LDCSF: Local depth convolution-based Swim framework for classifying multi-label histopathology images
Aug 21, 2023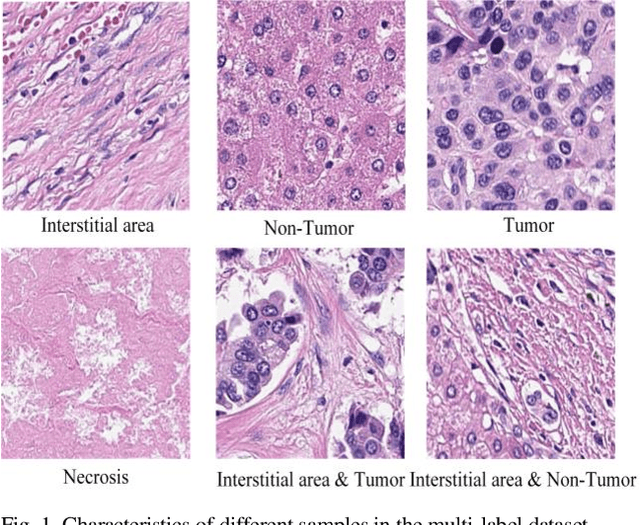
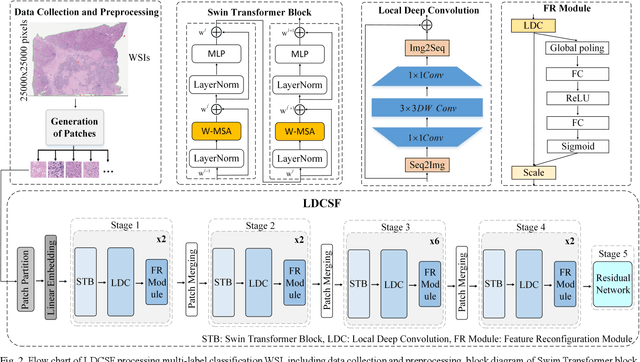
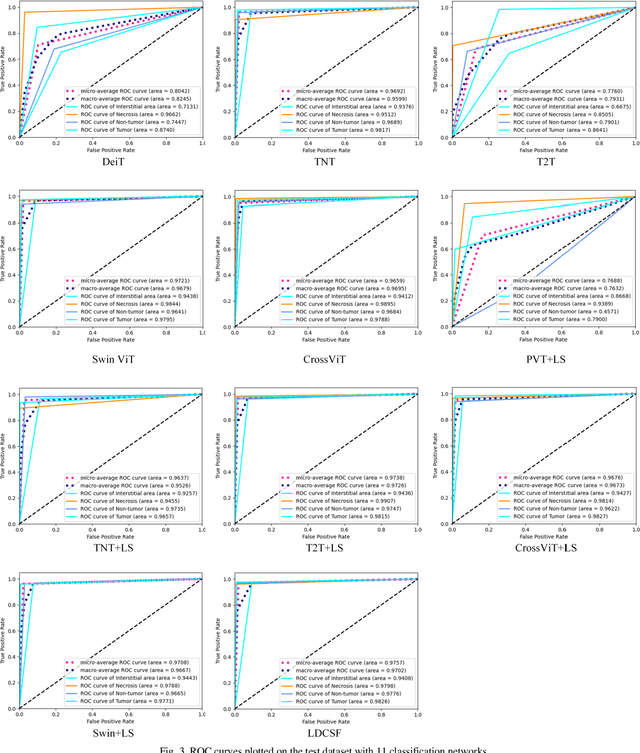
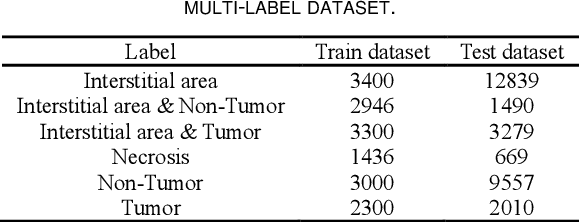
Histopathological images are the gold standard for diagnosing liver cancer. However, the accuracy of fully digital diagnosis in computational pathology needs to be improved. In this paper, in order to solve the problem of multi-label and low classification accuracy of histopathology images, we propose a locally deep convolutional Swim framework (LDCSF) to classify multi-label histopathology images. In order to be able to provide local field of view diagnostic results, we propose the LDCSF model, which consists of a Swin transformer module, a local depth convolution (LDC) module, a feature reconstruction (FR) module, and a ResNet module. The Swin transformer module reduces the amount of computation generated by the attention mechanism by limiting the attention to each window. The LDC then reconstructs the attention map and performs convolution operations in multiple channels, passing the resulting feature map to the next layer. The FR module uses the corresponding weight coefficient vectors obtained from the channels to dot product with the original feature map vector matrix to generate representative feature maps. Finally, the residual network undertakes the final classification task. As a result, the classification accuracy of LDCSF for interstitial area, necrosis, non-tumor and tumor reached 0.9460, 0.9960, 0.9808, 0.9847, respectively. Finally, we use the results of multi-label pathological image classification to calculate the tumor-to-stromal ratio, which lays the foundation for the analysis of the microenvironment of liver cancer histopathological images. Second, we released a multilabel histopathology image of liver cancer, our code and data are available at https://github.com/panliangrui/LSF.
Multi-Head Attention Mechanism Learning for Cancer New Subtypes and Treatment Based on Cancer Multi-Omics Data
Jul 09, 2023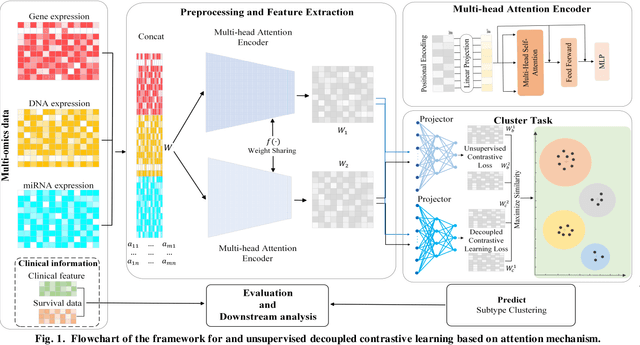
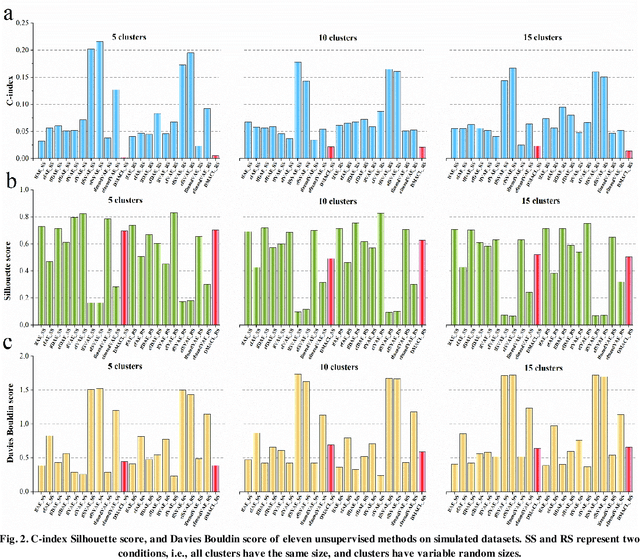
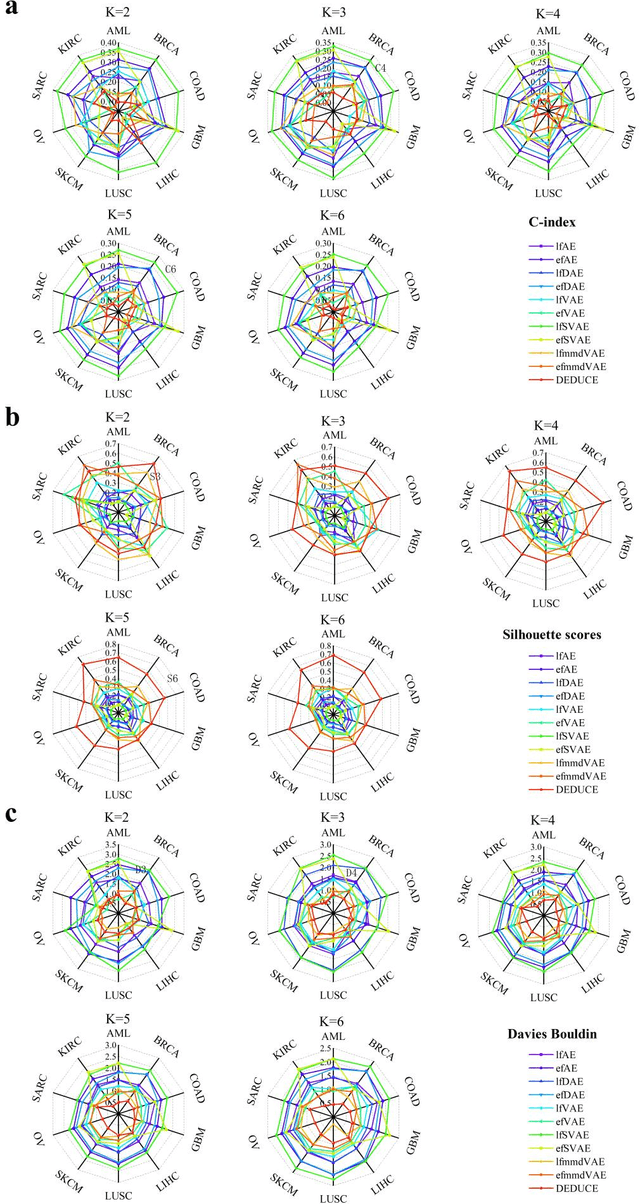
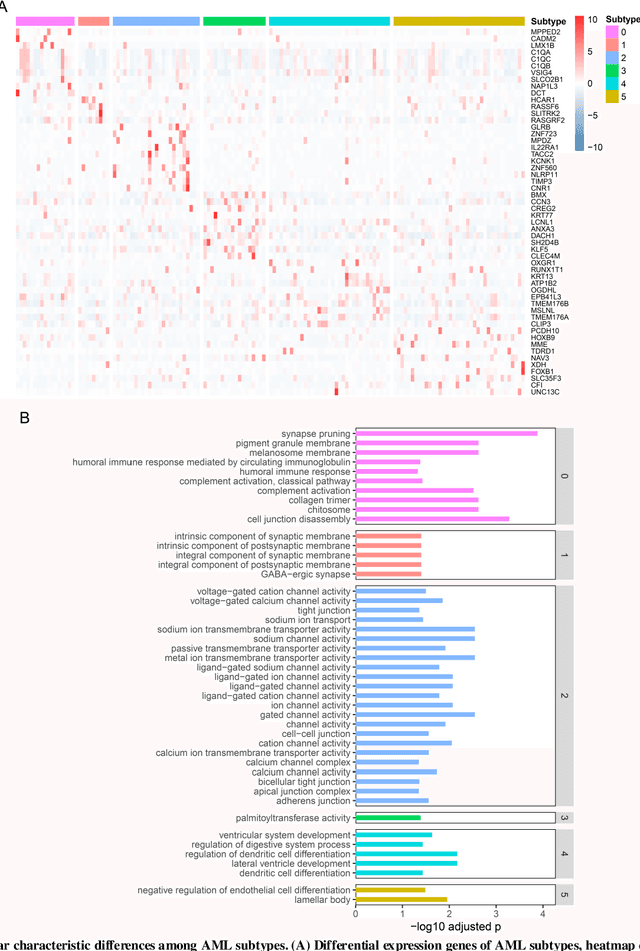
Due to the high heterogeneity and clinical characteristics of cancer, there are significant differences in multi-omics data and clinical features among subtypes of different cancers. Therefore, the identification and discovery of cancer subtypes are crucial for the diagnosis, treatment, and prognosis of cancer. In this study, we proposed a generalization framework based on attention mechanisms for unsupervised contrastive learning (AMUCL) to analyze cancer multi-omics data for the identification and characterization of cancer subtypes. AMUCL framework includes a unsupervised multi-head attention mechanism, which deeply extracts multi-omics data features. Importantly, a decoupled contrastive learning model (DMACL) based on a multi-head attention mechanism is proposed to learn multi-omics data features and clusters and identify new cancer subtypes. This unsupervised contrastive learning method clusters subtypes by calculating the similarity between samples in the feature space and sample space of multi-omics data. Compared to 11 other deep learning models, the DMACL model achieved a C-index of 0.002, a Silhouette score of 0.801, and a Davies Bouldin Score of 0.38 on a single-cell multi-omics dataset. On a cancer multi-omics dataset, the DMACL model obtained a C-index of 0.016, a Silhouette score of 0.688, and a Davies Bouldin Score of 0.46, and obtained the most reliable cancer subtype clustering results for each type of cancer. Finally, we used the DMACL model in the AMUCL framework to reveal six cancer subtypes of AML. By analyzing the GO functional enrichment, subtype-specific biological functions, and GSEA of AML, we further enhanced the interpretability of cancer subtype analysis based on the generalizable AMUCL framework.