 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving End-to-End Full-Duplex Speech Dialogue Models
Mar 09, 2026End-to-end full-duplex speech models feed user audio through an always-on LLM backbone, yet the speaker privacy implications of their hidden representations remain unexamined. Following the VoicePrivacy 2024 protocol with a lazy-informed attacker, we show that the hidden states of SALM-Duplex and Moshi leak substantial speaker identity across all transformer layers. Layer-wise and turn-wise analyses reveal that leakage persists across all layers, with SALM-Duplex showing stronger leakage in early layers while Moshi leaks uniformly, and that Linkability rises sharply within the first few turns. We propose two streaming anonymization setups using Stream-Voice-Anon: a waveform-level front-end (Anon-W2W) and a feature-domain replacement (Anon-W2F). Anon-W2F raises EER by over 3.5x relative to the discrete encoder baseline (11.2% to 41.0%), approaching the 50% random-chance ceiling, while Anon-W2W retains 78-93% of baseline sBERT across setups with sub-second response latency (FRL under 0.8 s).
CLEAR: Continuous Latent Autoregressive Modeling for High-quality and Low-latency Speech Synthesis
Aug 26, 2025Autoregressive (AR) language models have emerged as powerful solutions for zero-shot text-to-speech (TTS) synthesis, capable of generating natural speech from a few seconds of audio prompts. However, conventional AR-based TTS systems relying on discrete audio tokens face the challenge of lossy compression during tokenization, requiring longer discrete token sequences to capture the same information as continuous ones, which adds inference latency and complicates AR modeling. To address this challenge, this paper proposes the Continuous Latent Autoregressive model (CLEAR), a unified zero-shot TTS framework that directly models continuous audio representations. More specifically, CLEAR introduces an enhanced variational autoencoder with shortcut connections, which achieves a high compression ratio to map waveforms into compact continuous latents. A lightweight MLP-based rectified flow head that operates independently for each hidden state is presented to model the continuous latent probability distribution, and trained jointly with the AR model within a single-stage framework. Experiments show that the proposed zero-shot CLEAR TTS can synthesize high-quality speech with low latency. Compared to state-of-the-art (SOTA) TTS models, CLEAR delivers competitive performance in robustness, speaker similarity and naturalness, while offering a lower real-time factor (RTF). In particular, CLEAR achieves SOTA results on the LibriSpeech test-clean dataset, with a word error rate of 1.88\% and an RTF of 0.29. Moreover, CLEAR facilitates streaming speech synthesis with a first-frame delay of 96ms, while maintaining high-quality speech synthesis.
CrossMuSim: A Cross-Modal Framework for Music Similarity Retrieval with LLM-Powered Text Description Sourcing and Mining
Mar 29, 2025Music similarity retrieval is fundamental for managing and exploring relevant content from large collections in streaming platforms. This paper presents a novel cross-modal contrastive learning framework that leverages the open-ended nature of text descriptions to guide music similarity modeling, addressing the limitations of traditional uni-modal approaches in capturing complex musical relationships. To overcome the scarcity of high-quality text-music paired data, this paper introduces a dual-source data acquisition approach combining online scraping and LLM-based prompting, where carefully designed prompts leverage LLMs' comprehensive music knowledge to generate contextually rich descriptions. Exten1sive experiments demonstrate that the proposed framework achieves significant performance improvements over existing benchmarks through objective metrics, subjective evaluations, and real-world A/B testing on the Huawei Music streaming platform.
Efficient Adapter Tuning for Joint Singing Voice Beat and Downbeat Tracking with Self-supervised Learning Features
Mar 13, 2025Singing voice beat tracking is a challenging task, due to the lack of musical accompaniment that often contains robust rhythmic and harmonic patterns, something most existing beat tracking systems utilize and can be essential for estimating beats. In this paper, a novel temporal convolutional network-based beat-tracking approach featuring self-supervised learning (SSL) representations and adapter tuning is proposed to track the beat and downbeat of singing voices jointly. The SSL DistilHuBERT representations are utilized to capture the semantic information of singing voices and are further fused with the generic spectral features to facilitate beat estimation. Sources of variabilities that are particularly prominent with the non-homogeneous singing voice data are reduced by the efficient adapter tuning. Extensive experiments show that feature fusion and adapter tuning improve the performance individually, and the combination of both leads to significantly better performances than the un-adapted baseline system, with up to 31.6% and 42.4% absolute F1-score improvements on beat and downbeat tracking, respectively.
MDAN: Multi-level Dependent Attention Network for Visual Emotion Analysis
Mar 25, 2022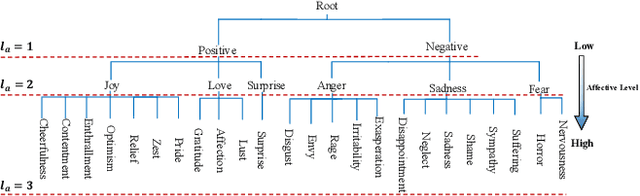
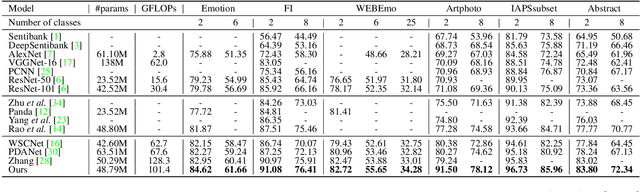
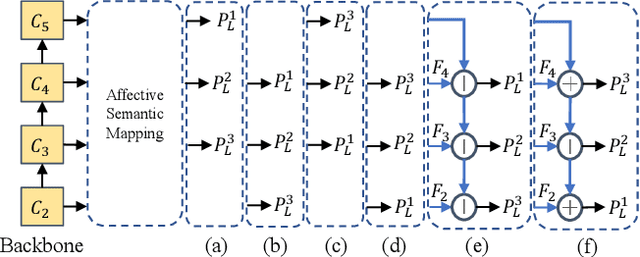

Visual Emotion Analysis (VEA) is attracting increasing attention. One of the biggest challenges of VEA is to bridge the affective gap between visual clues in a picture and the emotion expressed by the picture. As the granularity of emotions increases, the affective gap increases as well. Existing deep approaches try to bridge the gap by directly learning discrimination among emotions globally in one shot without considering the hierarchical relationship among emotions at different affective levels and the affective level of emotions to be classified. In this paper, we present the Multi-level Dependent Attention Network (MDAN) with two branches, to leverage the emotion hierarchy and the correlation between different affective levels and semantic levels. The bottom-up branch directly learns emotions at the highest affective level and strictly follows the emotion hierarchy while predicting emotions at lower affective levels. In contrast, the top-down branch attempt to disentangle the affective gap by one-to-one mapping between semantic levels and affective levels, namely, Affective Semantic Mapping. At each semantic level, a local classifier learns discrimination among emotions at the corresponding affective level. Finally, We integrate global learning and local learning into a unified deep framework and optimize the network simultaneously. Moreover, to properly extract and leverage channel dependencies and spatial attention while disentangling the affective gap, we carefully designed two attention modules: the Multi-head Cross Channel Attention module and the Level-dependent Class Activation Map module. Finally, the proposed deep framework obtains new state-of-the-art performance on six VEA benchmarks, where it outperforms existing state-of-the-art methods by a large margin, e.g., +3.85% on the WEBEmo dataset at 25 classes classification accuracy.
KaraTuner: Towards end to end natural pitch correction for singing voice in karaoke
Oct 18, 2021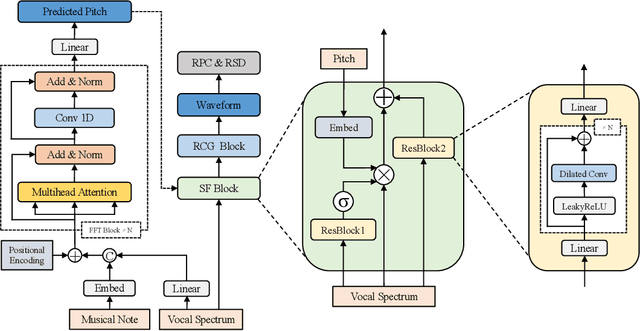

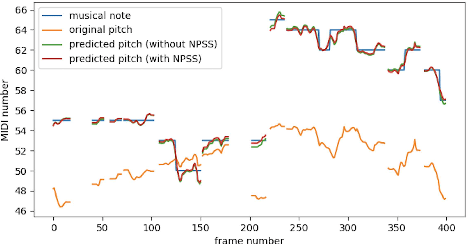
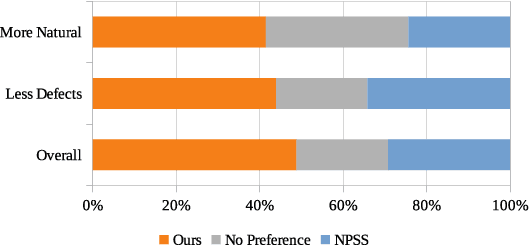
An automatic pitch correction system typically includes several stages, such as pitch extraction, deviation estimation, pitch shift processing, and cross-fade smoothing. However, designing these components with strategies often requires domain expertise and they are likely to fail on corner cases. In this paper, we present KaraTuner, an end-to-end neural architecture that predicts pitch curve and resynthesizes the singing voice directly from the tuned pitch and vocal spectrum extracted from the original recordings. Several vital technical points have been introduced in KaraTuner to ensure pitch accuracy, pitch naturalness, timbre consistency, and sound quality. A feed-forward Transformer is employed in the pitch predictor to capture long-term dependencies in the vocal spectrum and musical note. We also develop a pitch-controllable vocoder base on a novel source-filter block and the Fre-GAN architecture. KaraTuner obtains a higher preference than the rule-based pitch correction approach through A/B tests, and perceptual experiments show that the proposed vocoder achieves significant advantages in timbre consistency and sound quality compared with the parametric WORLD vocoder and phase vocoder.
Towards robust audio spoofing detection: a detailed comparison of traditional and learned features
May 28, 2019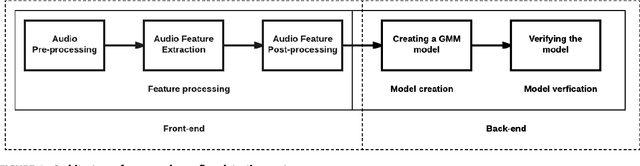

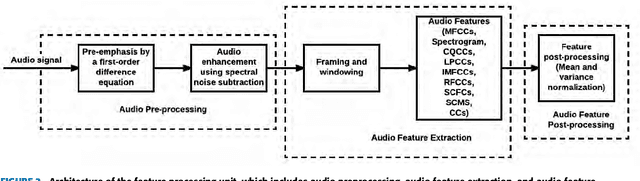
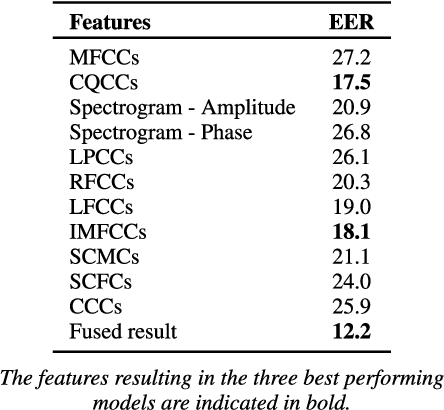
Automatic speaker verification, like every other biometric system, is vulnerable to spoofing attacks. Using only a few minutes of recorded voice of a genuine client of a speaker verification system, attackers can develop a variety of spoofing attacks that might trick such systems. Detecting these attacks using the audio cues present in the recordings is an important challenge. Most existing spoofing detection systems depend on knowing the used spoofing technique. With this research, we aim at overcoming this limitation, by examining robust audio features, both traditional and those learned through an autoencoder, that are generalizable over different types of replay spoofing. Furthermore, we provide a detailed account of all the steps necessary in setting up state-of-the-art audio feature detection, pre-, and postprocessing, such that the (non-audio expert) machine learning researcher can implement such systems. Finally, we evaluate the performance of our robust replay speaker detection system with a wide variety and different combinations of both extracted and machine learned audio features on the `out in the wild' ASVspoof 2017 dataset. This dataset contains a variety of new spoofing configurations. Since our focus is on examining which features will ensure robustness, we base our system on a traditional Gaussian Mixture Model-Universal Background Model. We then systematically investigate the relative contribution of each feature set. The fused models, based on both the known audio features and the machine learned features respectively, have a comparable performance with an Equal Error Rate (EER) of 12. The final best performing model, which obtains an EER of 10.8, is a hybrid model that contains both known and machine learned features, thus revealing the importance of incorporating both types of features when developing a robust spoofing prediction model.
Singing Voice Separation Using a Deep Convolutional Neural Network Trained by Ideal Binary Mask and Cross Entropy
Dec 04, 2018



Separating a singing voice from its music accompaniment remains an important challenge in the field of music information retrieval. We present a unique neural network approach inspired by a technique that has revolutionized the field of vision: pixel-wise image classification, which we combine with cross entropy loss and pretraining of the CNN as an autoencoder on singing voice spectrograms. The pixel-wise classification technique directly estimates the sound source label for each time-frequency (T-F) bin in our spectrogram image, thus eliminating common pre- and postprocessing tasks. The proposed network is trained by using the Ideal Binary Mask (IBM) as the target output label. The IBM identifies the dominant sound source in each T-F bin of the magnitude spectrogram of a mixture signal, by considering each T-F bin as a pixel with a multi-label (for each sound source). Cross entropy is used as the training objective, so as to minimize the average probability error between the target and predicted label for each pixel. By treating the singing voice separation problem as a pixel-wise classification task, we additionally eliminate one of the commonly used, yet not easy to comprehend, postprocessing steps: the Wiener filter postprocessing. The proposed CNN outperforms the first runner up in the Music Information Retrieval Evaluation eXchange (MIREX) 2016 and the winner of MIREX 2014 with a gain of 2.2702 ~ 5.9563 dB global normalized source to distortion ratio (GNSDR) when applied to the iKala dataset. An experiment with the DSD100 dataset on the full-tracks song evaluation task also shows that our model is able to compete with cutting-edge singing voice separation systems which use multi-channel modeling, data augmentation, and model blending.