 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards robust audio spoofing detection: a detailed comparison of traditional and learned features
May 28, 2019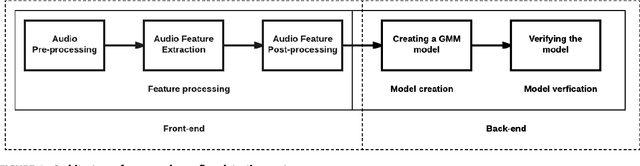

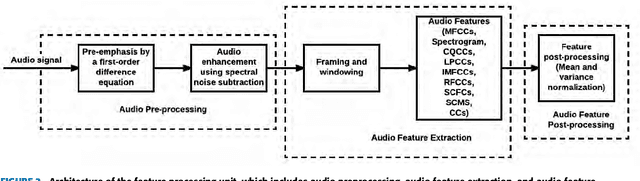
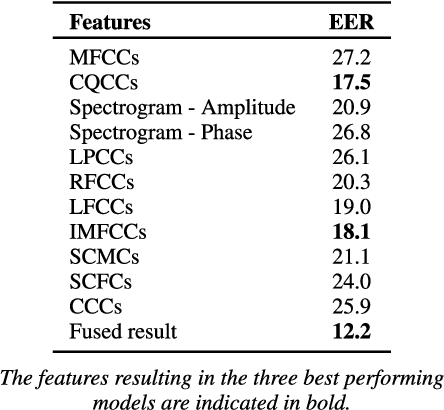
Automatic speaker verification, like every other biometric system, is vulnerable to spoofing attacks. Using only a few minutes of recorded voice of a genuine client of a speaker verification system, attackers can develop a variety of spoofing attacks that might trick such systems. Detecting these attacks using the audio cues present in the recordings is an important challenge. Most existing spoofing detection systems depend on knowing the used spoofing technique. With this research, we aim at overcoming this limitation, by examining robust audio features, both traditional and those learned through an autoencoder, that are generalizable over different types of replay spoofing. Furthermore, we provide a detailed account of all the steps necessary in setting up state-of-the-art audio feature detection, pre-, and postprocessing, such that the (non-audio expert) machine learning researcher can implement such systems. Finally, we evaluate the performance of our robust replay speaker detection system with a wide variety and different combinations of both extracted and machine learned audio features on the `out in the wild' ASVspoof 2017 dataset. This dataset contains a variety of new spoofing configurations. Since our focus is on examining which features will ensure robustness, we base our system on a traditional Gaussian Mixture Model-Universal Background Model. We then systematically investigate the relative contribution of each feature set. The fused models, based on both the known audio features and the machine learned features respectively, have a comparable performance with an Equal Error Rate (EER) of 12. The final best performing model, which obtains an EER of 10.8, is a hybrid model that contains both known and machine learned features, thus revealing the importance of incorporating both types of features when developing a robust spoofing prediction model.
Singing Voice Separation Using a Deep Convolutional Neural Network Trained by Ideal Binary Mask and Cross Entropy
Dec 04, 2018



Separating a singing voice from its music accompaniment remains an important challenge in the field of music information retrieval. We present a unique neural network approach inspired by a technique that has revolutionized the field of vision: pixel-wise image classification, which we combine with cross entropy loss and pretraining of the CNN as an autoencoder on singing voice spectrograms. The pixel-wise classification technique directly estimates the sound source label for each time-frequency (T-F) bin in our spectrogram image, thus eliminating common pre- and postprocessing tasks. The proposed network is trained by using the Ideal Binary Mask (IBM) as the target output label. The IBM identifies the dominant sound source in each T-F bin of the magnitude spectrogram of a mixture signal, by considering each T-F bin as a pixel with a multi-label (for each sound source). Cross entropy is used as the training objective, so as to minimize the average probability error between the target and predicted label for each pixel. By treating the singing voice separation problem as a pixel-wise classification task, we additionally eliminate one of the commonly used, yet not easy to comprehend, postprocessing steps: the Wiener filter postprocessing. The proposed CNN outperforms the first runner up in the Music Information Retrieval Evaluation eXchange (MIREX) 2016 and the winner of MIREX 2014 with a gain of 2.2702 ~ 5.9563 dB global normalized source to distortion ratio (GNSDR) when applied to the iKala dataset. An experiment with the DSD100 dataset on the full-tracks song evaluation task also shows that our model is able to compete with cutting-edge singing voice separation systems which use multi-channel modeling, data augmentation, and model blending.