 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttendAffectNet: Self-Attention based Networks for Predicting Affective Responses from Movies
Oct 21, 2020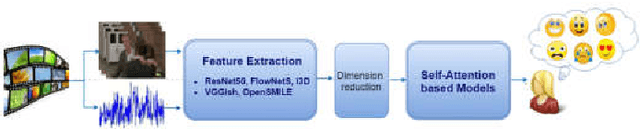

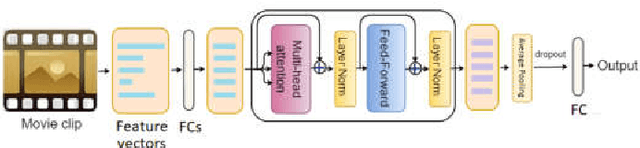
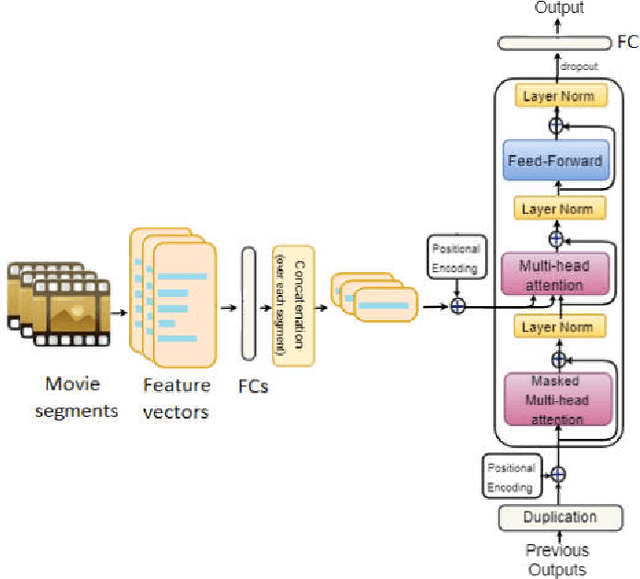
In this work, we propose different variants of the self-attention based network for emotion prediction from movies, which we call AttendAffectNet. We take both audio and video into account and incorporate the relation among multiple modalities by applying self-attention mechanism in a novel manner into the extracted features for emotion prediction. We compare it to the typically temporal integration of the self-attention based model, which in our case, allows to capture the relation of temporal representations of the movie while considering the sequential dependencies of emotion responses. We demonstrate the effectiveness of our proposed architectures on the extended COGNIMUSE dataset [1], [2] and the MediaEval 2016 Emotional Impact of Movies Task [3], which consist of movies with emotion annotations. Our results show that applying the self-attention mechanism on the different audio-visual features, rather than in the time domain, is more effective for emotion prediction. Our approach is also proven to outperform many state-ofthe-art models for emotion prediction. The code to reproduce our results with the models' implementation is available at: https://github.com/ivyha010/AttendAffectNet.
Latent space representation for multi-target speaker detection and identification with a sparse dataset using Triplet neural networks
Oct 04, 2019



We present an approach to tackle the speaker recognition problem using Triplet Neural Networks. Currently, the $i$-vector representation with probabilistic linear discriminant analysis (PLDA) is the most commonly used technique to solve this problem, due to high classification accuracy with a relatively short computation time. In this paper, we explore a neural network approach, namely Triplet Neural Networks (TNNs), to built a latent space for different classifiers to solve the Multi-Target Speaker Detection and Identification Challenge Evaluation 2018 (MCE 2018) dataset. This training set contains $i$-vectors from 3,631 speakers, with only 3 samples for each speaker, thus making speaker recognition a challenging task. When using the train and development set for training both the TNN and baseline model (i.e., similarity evaluation directly on the $i$-vector representation), our proposed model outperforms the baseline by 23%. When reducing the training data to only using the train set, our method results in 309 confusions for the Multi-target speaker identification task, which is 46% better than the baseline model. These results show that the representational power of TNNs is especially evident when training on small datasets with few instances available per class.
* Accepted for ASRU 2019
Singing Voice Separation Using a Deep Convolutional Neural Network Trained by Ideal Binary Mask and Cross Entropy
Dec 04, 2018



Separating a singing voice from its music accompaniment remains an important challenge in the field of music information retrieval. We present a unique neural network approach inspired by a technique that has revolutionized the field of vision: pixel-wise image classification, which we combine with cross entropy loss and pretraining of the CNN as an autoencoder on singing voice spectrograms. The pixel-wise classification technique directly estimates the sound source label for each time-frequency (T-F) bin in our spectrogram image, thus eliminating common pre- and postprocessing tasks. The proposed network is trained by using the Ideal Binary Mask (IBM) as the target output label. The IBM identifies the dominant sound source in each T-F bin of the magnitude spectrogram of a mixture signal, by considering each T-F bin as a pixel with a multi-label (for each sound source). Cross entropy is used as the training objective, so as to minimize the average probability error between the target and predicted label for each pixel. By treating the singing voice separation problem as a pixel-wise classification task, we additionally eliminate one of the commonly used, yet not easy to comprehend, postprocessing steps: the Wiener filter postprocessing. The proposed CNN outperforms the first runner up in the Music Information Retrieval Evaluation eXchange (MIREX) 2016 and the winner of MIREX 2014 with a gain of 2.2702 ~ 5.9563 dB global normalized source to distortion ratio (GNSDR) when applied to the iKala dataset. An experiment with the DSD100 dataset on the full-tracks song evaluation task also shows that our model is able to compete with cutting-edge singing voice separation systems which use multi-channel modeling, data augmentation, and model blending.